rjones (Mon, 19 Nov 2018 18:14:58 GMT):
User User_1 added by rjones.
rjones (Mon, 19 Nov 2018 18:15:08 GMT):
nage
rjones (Mon, 19 Nov 2018 18:15:38 GMT):
User User_2 added by rjones.
rjones (Mon, 19 Nov 2018 18:15:50 GMT):
User User_3 added by rjones.
rjones (Mon, 19 Nov 2018 18:16:05 GMT):
kenebert
rjones (Mon, 19 Nov 2018 18:16:09 GMT):
pknowles
tom_weiss (Mon, 19 Nov 2018 18:22:08 GMT):
Has joined the channel.
nhelmy (Mon, 19 Nov 2018 18:23:51 GMT):
Has joined the channel.
pknowles (Mon, 19 Nov 2018 18:37:43 GMT):
Welcome to the new *#indy-semantics* channel, a home for all Hyperledger Indy data capture and semantics discussions!
pknowles (Mon, 19 Nov 2018 18:37:43 GMT):
Welcome to the new *#indy-semantics* channel, a home for all Hyperledger Indy data capture and semantics discussions including schemas and overlays!
pknowles (Mon, 19 Nov 2018 18:37:43 GMT):
Welcome to the new *#indy-semantics* channel, a home for all Hyperledger Indy data capture and semantics discussions!
rjones (Mon, 19 Nov 2018 18:54:45 GMT):
rjones (Mon, 19 Nov 2018 18:55:15 GMT):
*I leave this channel in your capable hands*
rjones (Mon, 19 Nov 2018 18:55:18 GMT):
Has left the channel.
nage (Mon, 19 Nov 2018 19:07:09 GMT):
Thanks @rjones
rjones (Mon, 19 Nov 2018 19:07:09 GMT):
Has joined the channel.
nage (Mon, 19 Nov 2018 19:07:30 GMT):
Home for all Hyperledger Indy data capture and semantics discussions including schemas and overlays
mtfkremoveme (Mon, 19 Nov 2018 19:10:23 GMT):
Has joined the channel.
mtfkremoveme (Mon, 19 Nov 2018 19:10:53 GMT):
HI all!
mtfkremoveme (Mon, 19 Nov 2018 19:20:39 GMT):
Has left the channel.
mtfk (Mon, 19 Nov 2018 19:20:51 GMT):
Has joined the channel.
mtfkremoveme (Mon, 19 Nov 2018 19:23:19 GMT):
Has joined the channel.
mtfkremoveme (Mon, 19 Nov 2018 19:23:42 GMT):
Has left the channel.
rjones (Mon, 19 Nov 2018 19:37:12 GMT):
Has left the channel.
Sean_Bohan (Mon, 19 Nov 2018 20:39:51 GMT):
Has joined the channel.
darrell.odonnell (Mon, 19 Nov 2018 22:00:08 GMT):
Has joined the channel.
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays 1O1* to the *HL Indy WG* call attendees. The video from that call is housed at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUug
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays 1O1* to the *HL Indy WG* attendees. The video from that call is housed at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUug
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays* to the *Indy WG* attendees. The video from that call is housed at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUu
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays* to the *Indy WG* attendees. The video from that call is housed at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUug
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays* to the *Indy WG* attendees. The video from that call is available at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUug
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays* to the *Indy WG* attendees. The video from that call is available for viewing at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUug
pknowles (Mon, 19 Nov 2018 22:05:44 GMT):
Last Thursday, @mtfk and I presented *Overlays* to the *Indy WG* attendees. The video from that call can be viewed at https://drive.google.com/open?id=1a4ydpu6RDlyrqWX7eLomElR_CTj8hUug
pknowles (Mon, 19 Nov 2018 22:12:25 GMT):
User User_4 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:12:25 GMT):
User User_5 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:12:25 GMT):
User User_6 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:13:25 GMT):
User User_7 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:13:25 GMT):
User User_8 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:29:36 GMT):
User User_9 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:30:29 GMT):
User User_10 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:31:25 GMT):
User User_11 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:38:44 GMT):
User User_12 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:38:44 GMT):
User User_13 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:38:44 GMT):
User User_14 added by pknowles.
pknowles (Mon, 19 Nov 2018 22:40:24 GMT):
User User_15 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:39 GMT):
User User_16 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:39 GMT):
User User_17 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:39 GMT):
User User_18 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:39 GMT):
User User_19 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_20 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_21 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_22 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_23 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_24 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_25 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_26 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_27 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_28 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_29 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_30 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_31 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_32 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_33 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:36:40 GMT):
User User_34 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:37:41 GMT):
User User_35 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:39:18 GMT):
User User_36 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:39:18 GMT):
User User_37 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:39:18 GMT):
User User_38 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:41:26 GMT):
User User_39 added by pknowles.
pknowles (Mon, 19 Nov 2018 23:55:41 GMT):
User User_40 added by pknowles.
drummondreed (Tue, 20 Nov 2018 03:13:31 GMT):
Very nice, @pknowles. I hope your SSI Meetup webinar went well today—my lunch with the University of Washington (who is very seriously looking into Hyperledger Indy and SSI) went long so I wasn't able to attend. But I'll watch the recording on SSI Meetup.
arunwij (Tue, 20 Nov 2018 05:11:19 GMT):
Has joined the channel.
gudkov (Tue, 20 Nov 2018 10:48:20 GMT):
Has joined the channel.
mxs1491 (Tue, 20 Nov 2018 11:02:18 GMT):
Has joined the channel.
pknowles (Tue, 20 Nov 2018 12:03:41 GMT):
The video recording and slideshare presentation from yesterday’s *SSIMeetup* are now available for viewing. The title of the presentation was *Overlays 1O1: Establishing Schema Definitions within the Self-Sovereign Identity (SSI) Ecosystem*. Here is the link. Enjoy! http://ssimeetup.org/overlays-1o1-establishing-schema-definitions-self-sovereign-identity-ssi-ecosystem-paul-knowles-webinar-17/
pknowles (Tue, 20 Nov 2018 12:03:41 GMT):
The video recording and slideshare presentation from yesterday’s *SSIMeetup* are now available for viewing. The title of the presentation: *Overlays 1O1: Establishing Schema Definitions within the Self-Sovereign Identity (SSI) Ecosystem*. Here is the link. Enjoy! http://ssimeetup.org/overlays-1o1-establishing-schema-definitions-self-sovereign-identity-ssi-ecosystem-paul-knowles-webinar-17/
pknowles (Tue, 20 Nov 2018 12:03:41 GMT):
The video recording and slideshare presentation from yesterday’s *SSIMeetup* are now available for viewing. The title of the presentation: "*Overlays 1O1: Establishing Schema Definitions within the Self-Sovereign Identity (SSI) Ecosystem*". Here is the link. Enjoy! http://ssimeetup.org/overlays-1o1-establishing-schema-definitions-self-sovereign-identity-ssi-ecosystem-paul-knowles-webinar-17/
pknowles (Tue, 20 Nov 2018 12:03:41 GMT):
The video recording and slideshare presentation from yesterday’s *SSIMeetup* are now available for viewing. The title of the presentation: " *Overlays 1O1: Establishing Schema Definitions within the Self-Sovereign Identity (SSI) Ecosystem* ". Here is the link. Enjoy! http://ssimeetup.org/overlays-1o1-establishing-schema-definitions-self-sovereign-identity-ssi-ecosystem-paul-knowles-webinar-17/
pknowles (Tue, 20 Nov 2018 12:03:41 GMT):
The video recording and slideshare presentation from yesterday’s *SSIMeetup* are now available for viewing. The title of the presentation: " *Overlays 1O1: Establishing Schema Definitions within the Self-Sovereign Identity (SSI) Ecosystem* ". Here is the link. http://ssimeetup.org/overlays-1o1-establishing-schema-definitions-self-sovereign-identity-ssi-ecosystem-paul-knowles-webinar-17/
Silona (Tue, 20 Nov 2018 15:07:32 GMT):
Has joined the channel.
MattRaffel (Tue, 20 Nov 2018 16:28:56 GMT):
Has joined the channel.
drummondreed (Tue, 20 Nov 2018 17:16:37 GMT):
Awesome. Great job, Paul.
kannancet (Tue, 20 Nov 2018 19:34:35 GMT):
Has joined the channel.
tom_weiss (Tue, 20 Nov 2018 20:55:48 GMT):
Lovely to be hear
pknowles (Tue, 20 Nov 2018 20:56:48 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=wcFcSnpsnC23qtJC8) @tom_weiss Welcome, Old Bean!
Sean_Bohan (Tue, 20 Nov 2018 23:10:49 GMT):
welcome!
esplinr (Tue, 20 Nov 2018 23:25:05 GMT):
Has joined the channel.
pknowles (Mon, 26 Nov 2018 07:54:26 GMT):
Due to the amalgamation of all data capture and semantics initiatives being undertaken on Hyperledger Indy, a new *Semantics WG* has been implemented in place of the old *Schemas and Overlays WG*. Our first meeting under the new name will take place on Tuesday, November 27th providing an opportunity for members of the community to discuss any HL Indy semantics initiatives that they've been working on. Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 27th November
Time:
10am-11am PT
11am-12pm MT
12pm-1pm CT
1pm-2pm ET
6pm-7pm GMT
Anyone is welcome to join the call.
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Schemas/Overlays data capture architecture ( @pknowles / @mtfk ) - 15 mins
- Reference - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
• Sovrin Verifiable Credentials data model ( @brentzundel / @kenebert ) - 15 mins
• Consent Receipt model ( @JanL 5 ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 10 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Mon, 26 Nov 2018 07:54:26 GMT):
Due to the amalgamation of all data capture and semantics initiatives being undertaken on Hyperledger Indy, a new *Semantics WG* has been implemented in place of the old *Schemas and Overlays WG*. Our first meeting under the new name will take place on Tuesday, November 27th providing an opportunity for members of the community to discuss any HL Indy semantics initiatives that they've been working on. Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 27th November
Time:
10am-11am PT
11am-12pm MT
12pm-1pm CT
1pm-2pm ET
6pm-7pm GMT
Anyone is welcome to join the call.
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Schemas/Overlays data capture architecture ( @pknowles / @mtfk ) - 15 mins
- Reference - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
• Sovrin Verifiable Credentials data model ( @brentzundel / @kenebert ) - 15 mins
• Consent Receipt model ( @JanL 5 ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 10 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Mon, 26 Nov 2018 07:54:26 GMT):
Due to the amalgamation of all data capture and semantics initiatives being undertaken on Hyperledger Indy, a new *Semantics WG* has been implemented in place of the old *Schemas and Overlays WG*. Our first meeting under the new name will take place on Tuesday, November 27th providing an opportunity for members of the community to discuss any HL Indy semantics initiatives that they've been working on. Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 27th November
Time:
10am-11am PT
11am-12pm MT
12pm-1pm CT
1pm-2pm ET
6pm-7pm GMT
Anyone is welcome to join the call.
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Schemas/Overlays data capture architecture ( @pknowles / @mtfk ) - 15 mins
- Reference - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
• Sovrin Verifiable Credentials data model ( @brentzundel / @kenebert ) - 15 mins
• Consent Receipt model ( @JanL 5 ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 10 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Mon, 26 Nov 2018 07:54:26 GMT):
Due to the amalgamation of all data capture and semantics initiatives being undertaken on Hyperledger Indy, a new *Semantics WG* has been implemented in place of the old *Schemas and Overlays WG*. Our first meeting under the new name will take place on Tuesday, November 27th providing an opportunity for members of the community to discuss any HL Indy semantics initiatives they've been working on. Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 27th November
Time:
10am-11am PT
11am-12pm MT
12pm-1pm CT
1pm-2pm ET
6pm-7pm GMT
Anyone is welcome to join the call.
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Schemas/Overlays data capture architecture ( @pknowles / @mtfk ) - 15 mins
- Reference - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
• Sovrin Verifiable Credentials data model ( @brentzundel / @kenebert ) - 15 mins
• Consent Receipt model ( @JanL 5 ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 10 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Mon, 26 Nov 2018 07:54:26 GMT):
Due to the amalgamation of all data capture and semantics initiatives being undertaken on Hyperledger Indy, a new *Semantics WG* has been implemented in place of the old *Schemas and Overlays WG*. Our first meeting under the new name will take place on Tuesday, November 27th providing an opportunity for members of the community to discuss any HL Indy semantics initiatives they've been working on. Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 27th November
Time:
10am-11am PT
11am-12pm MT
12pm-1pm CT
1pm-2pm ET
6pm-7pm GMT
Anyone is welcome to join the call.
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Schemas/Overlays data capture architecture ( @pknowles / @mtfk ) - 15 mins
- Reference - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
• Sovrin Verifiable Credentials data model ( @brentzundel / @kenebert ) - 15 mins
• Consent Receipt model ( @JanL 5 ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 10 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Mon, 26 Nov 2018 07:54:26 GMT):
Due to the amalgamation of all data capture and semantics initiatives being undertaken on Hyperledger Indy, a new *Semantics WG* has been implemented in place of the old *Schemas and Overlays WG*. Our first meeting under the new name will take place on Tuesday, November 27th providing an opportunity for members of the community to discuss any HL Indy semantics initiatives they've been working on. Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 27th November
Time:
10am-11am PT
11am-12pm MT
12pm-1pm CT
1pm-2pm ET
6pm-7pm GMT
Anyone is welcome to join the call.
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Schemas/Overlays data capture architecture ( @pknowles / @mtfk ) - 15 mins
- Reference - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
• Sovrin Verifiable Credentials data model ( @brentzundel / @kenebert ) - 15 mins
• Consent Receipt model ( @JanL 5 ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 10 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
brycecurtis (Tue, 27 Nov 2018 15:51:57 GMT):
Has joined the channel.
pknowles (Tue, 27 Nov 2018 17:43:01 GMT):
This week's *Semantics WG* call starts in 15 minutes. Agenda Doc: https://drive.google.com/drive/u/0/folders/1kN-INYUNYB-yA8teZR3EarxcwdMMmKrl?ogsrc=32
pknowles (Tue, 27 Nov 2018 23:09:42 GMT):
The agenda, video, notes, etc. from today's *Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, December 12th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
jljordan_bcgov (Fri, 30 Nov 2018 04:01:05 GMT):
Has joined the channel.
olegwb (Fri, 30 Nov 2018 12:20:34 GMT):
Has joined the channel.
darrell.odonnell (Sat, 01 Dec 2018 15:44:56 GMT):
@pknowles consider the following business case - I want to consider providing a Sovrin-backed Verifiable Credential from a credit union. My "dream state" would allow a combination of static data (e..g. "MemberSince", "Institution Name") and some dynamic data (e.g. "Average Monthly Balance", "Good Customer Standing").
I recognize that the current Verifiable Creds, particularly with the ZKP support, require totally new credentials when any data change. Does the current Overlay concept allow data augmentation - combining live/dynamic data from other sources with the VerCred static data?
darrell.odonnell (Sat, 01 Dec 2018 15:47:19 GMT):
if you could point me at the most current docs I would like to include reference to the Overlays (and Schema) work that you've been working on so hard. I am publishing a report with some experts in the Sovrin/Indy space about Digital Wallets and what they need to become. Overlays is a key feature.
pknowles (Sat, 01 Dec 2018 16:47:04 GMT):
@darrell.odonnell In short, yes, the Overlays architecture will allow the capture of static data with dynamic augmentation from a combination of different internal or external sources. I'll DM you for some more specifics so that I can draft a hypothetical Overlays solution for your particular use case. In the meantime, although still in draft, the following two documents are the most current and relevant to your query: (i.) *Schema Overlays* - https://github.com/mitfik/overlays-demo/blob/master/SOD.md and (ii.) *Consent Receipt* - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
pknowles (Sat, 01 Dec 2018 16:47:04 GMT):
@darrell.odonnell In short, yes, the Overlays architecture will allow the capture of static data with dynamic augmentation from a combination of different internal or external sources. I'll DM you for some more specifics so that I can draft a hypothetical Overlays solution for your particular use case. In the meantime, although still in draft, the following two documents are the most current and relevant to your query: (i.) *Schema Overlays* - https://github.com/mitfik/overlays-demo/blob/master/SOD.md and (ii.) *Consent Receipt* - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt [Cc: @mtfk @JanL 5]
pknowles (Sat, 01 Dec 2018 16:47:04 GMT):
@darrell.odonnell In short, yes, the Overlays architecture will allow the capture of static data with dynamic augmentation from a combination of different internal or external sources. I'll DM you for some more specifics so that I can draft a hypothetical Overlays solution for your particular use case. In the meantime, although still in draft, the following two documents are the most current and relevant to your query: (i.) *Schema Overlays* - https://github.com/mitfik/overlays-demo/blob/master/SOD.md and (ii.) *Consent Receipt* - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt [Cc: @mtfk @JanL]
pknowles (Sat, 01 Dec 2018 16:47:04 GMT):
@swcurran There are new pieces being added all the time. The data capture architecture has evolved beyond the 101 sessions. In terms of Darrell's query, I see dynamic data being closely aligned with the consent definitions on those particular attributes which we can capture via a combination of consent attributes in the schema definition, a consent overlay and a proof schema.
pknowles (Sat, 01 Dec 2018 16:47:04 GMT):
@darrell.odonnell In short, yes, the Overlays architecture should allow the capture of static data with augmentation from a combination of different internal or external sources. I’ll DM for some more specifics so that I can draft a hypothetical Overlays solution for your particular use case. In the meantime, although still in draft, the following two documents are the most current and potentially relevant to your query: (i.) *Schema Overlays - https://github.com/mitfik/overlays-demo/blob/master/SOD.md and (ii.) *Consent Receipt* - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt [Cc: @mtfk @JanL ]
pknowles (Sat, 01 Dec 2018 16:47:04 GMT):
@darrell.odonnell In short, yes, the Overlays architecture should allow the capture of static data with augmentation from a combination of different internal or external sources. I’ll DM for some more specifics so that I can draft a hypothetical Overlays solution for your particular use case. In the meantime, although still in draft, the following two documents are the most current and potentially relevant to your query: (i.) *Schema Overlays* - https://github.com/mitfik/overlays-demo/blob/master/SOD.md and (ii.) *Consent Receipt* - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt [Cc: @mtfk @JanL ]
pknowles (Sat, 01 Dec 2018 17:40:18 GMT):
@mtfk @JanL 5 ^^
swcurran (Sat, 01 Dec 2018 21:14:17 GMT):
@pknowles is that new since the 101 sessions you've been doing? I can't see how the type of dynamic data @darrell.odonnell is talking about is possible with the overlays model I have seen. He wants dynamic data per credential, not per schema.
pknowles (Sat, 01 Dec 2018 21:25:00 GMT):
@swcurran The 101 sessions have since evolved and we're adding pieces that should be able to deal with Darrell's use case. I see the handling of dynamic data being closely aligned with the consent definitions on those particular attributes which we can capture via a combination of consent attributes in the schema definition, a consent overlay and a proof schema.
pknowles (Sat, 01 Dec 2018 21:25:15 GMT):
Screen Shot 2018-12-01 at 20.41.28.png
pknowles (Sat, 01 Dec 2018 21:26:06 GMT):
From my side, if the Issuer has the ability to dictate the conditions defining the consent window, an automated tool could be built to pull in dynamic data at regular intervals without breaking the overlay terms.
pknowles (Sat, 01 Dec 2018 21:29:17 GMT):
@brentzundel also added his thoughts from a *Credential Definition* perspective: "To enable the presentation of dynamic data, the prover could possibly issue the verifier a credential that allows it to access an endpoint which would resolve as the source of dynamic data. The encoding of this end point could be static, signed by the issuer, and revealed to the verifier as part of the proof. This would only be okay if the issuer controls the data provided at the endpoint, but the prover controls access to the endpoint."
swcurran (Sat, 01 Dec 2018 21:29:35 GMT):
But it still relies on the issuance of a credential so that it can be proven. Regardless of the automation around the event, it still means using a verifiable credential - I can't see getting around that.
swcurran (Sat, 01 Dec 2018 21:32:56 GMT):
Your last point is interesting - seems technically challenging, especially with the desire for a Holder to prove claims independent of the issuer. Seems that might need to be given up?
swcurran (Sat, 01 Dec 2018 21:33:36 GMT):
Perhaps the benefit of the dynamic data would be worth the trade off?
pknowles (Sat, 01 Dec 2018 21:36:05 GMT):
It's definitely an interesting use case and an important one at that. Our next *Semantics WG* meeting is on *Tuesday, December 11th* ( *10am-11am PT* ). I'm going to add this as an agenda item. It'll be good to get this one aired for sure.
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
Is there a reference to the dynamic data as described above? I think I get the idea, except how the dynamic data can be handled in a proof. Harri from (I think) Tieto did something like that to grant access to data, but it was just a feed of raw data, but encapsulated as a proof.
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
Is there a reference to the dynamic data as described above? I think I get the idea, except how the dynamic data can be handled in a proof. Harri from (I think) Tieto did something like that to grant access to data, bu t it was just a feed of raw data, not encapsulated as a proof.
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
Is there a reference to the dynamic data as described above? I think I get the idea, except how the dynamic data can be handled in a proof. Harri from (I think) Tieto did something like that to grant access to data, but it was just a feed of raw data, not encapsulated as a proof.
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=3c6e3681-0017-4ea7-8f80-4cab9ef05763) @swcurran @brentzundel Is there a reference to your point re dynamic data? "To enable the presentation of dynamic data, the prover could possibly issue the verifier a credential that allows it to access an endpoint which would resolve as the source of dynamic data. The encoding of this end point could be static, signed by the issuer, and revealed to the verifier as part of the proof. This would only be okay if the issuer controls the data provided at the endpoint, but the prover controls access to the endpoint."
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
@brentzundel Is there a reference to your point re dynamic data? "To enable the presentation of dynamic data, the prover could possibly issue the verifier a credential that allows it to access an endpoint which would resolve as the source of dynamic data. The encoding of this end point could be static, signed by the issuer, and revealed to the verifier as part of the proof. This would only be okay if the issuer controls the data provided at the endpoint, but the prover controls access to the endpoint.
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
Is there a reference to the dynamic data as described above? I think I get the idea, except how the dynamic data can be handled in a proof. Harri from (I think) Tieto did something like that to grant access to data, but it was just a feed of raw data, not encapsulated as a proof.
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
@brentzundel Is there a reference to the dynamic data idea that you described above? "To enable the presentation of dynamic data, the prover could possibly issue the verifier a credential that allows it to access an endpoint which would resolve as the source of dynamic data. The encoding of this end point could be static, signed by the issuer, and revealed to the verifier as part of the proof. This would only be okay if the issuer controls the data provided at the endpoint, but the prover controls access to the endpoint." [Cc: @swcurran ]
swcurran (Sat, 01 Dec 2018 21:49:37 GMT):
@brentzundel Is there a reference to the dynamic data idea that you described above? "To enable the presentation of dynamic data, the prover could possibly issue the verifier a credential that allows it to access an endpoint which would resolve as the source of dynamic data. The encoding of this end point could be static, signed by the issuer, and revealed to the verifier as part of the proof. This would only be okay if the issuer controls the data provided at the endpoint, but the prover controls access to the endpoint."
swcurran (Sat, 01 Dec 2018 21:50:37 GMT):
Which may be just fine.
Don't quite see the connection to overlays, but I'm interested in reading/hearing more.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer, in this case, then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period. I guess until we nut this out, we may be over thinking it but I see dynamic data collection as a combination of verifiable credential and consent terms.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer in this particular case then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period. I guess until we nut this out, we may be over thinking it but I see dynamic data collection as a combination of verifiable credential and consent terms.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer in this particular case then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period. I guess until we nut this out, we may be over thinking it but I see dynamic data collection as a combination of verifiable credential remit and consent terms.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer in this particular case then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of "verifiable credential" remit and consent terms defined by a Consent Overlay.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of "verifiable credential" remit and consent terms defined by a Consent Overlay.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of consent terms defined by a Consent Overlay and information held in the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of consent terms defined by a Consent Overlay and data held in the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of consent terms defined by a Consent Overlay with some of that data held in the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of consent terms defined by a Consent Overlay with some of the timestamp information held in the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a combination of Verifiable Credential with consent terms defined by a Consent Overlay with some of the timestamp information held in the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, we may be over complicating it but I ultimately see dynamic data collection as a credential with consent terms defined by a Consent Overlay with some of the timestamp information being retained within the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, I may be over complicating it but I ultimately see dynamic data collection as a credential with consent terms defined by a Consent Overlay with some of the timestamp information being retained within the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, I may be overcomplicating it but I ultimately see dynamic data collection as a credential with consent terms defined by a Consent Overlay with some of the timestamp information being retained within the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, I may be overcomplicating it but I ultimately see dynamic data collection as a credential with consent terms being defined by a Consent Overlay with some of that timestamp information being retained within the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. If those terms are not dictated by the Issuer (in this particular example) then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, I may be overcomplicating it but I ultimately see dynamic data collection as a credential with consent terms being defined by a Consent Overlay with countdown information being retained within the credential.
pknowles (Sat, 01 Dec 2018 21:58:05 GMT):
All of the consent definitions are bound by entries in a Consent Overlay. In this particular example, if those terms are not dictated by the Issuer then they wouldn't necessarily have the legal right to collect dynamic data over a predefined period of time. I guess until we nut this out, I may be overcomplicating it but I ultimately see dynamic data collection as a credential with consent terms being defined by a Consent Overlay with countdown information being retained within the credential.
pknowles (Sat, 01 Dec 2018 21:59:29 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=3c6e3681-0017-4ea7-8f80-4cab9ef05763) @swcurran ^^ @brentzundel
pknowles (Sat, 01 Dec 2018 21:59:29 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=3c6e3681-0017-4ea7-8f80-4cab9ef05763) ^^ @brentzundel
pknowles (Sat, 01 Dec 2018 22:11:39 GMT):
User User_41 added by pknowles.
pknowles (Sat, 01 Dec 2018 22:16:48 GMT):
@harrihoo I've added you to this channel so that we can get your thoughts on dynamic data collection. See conversation above which @darrell.odonnell kicked off. @swcurran suggested that in the recent past you have managed to grant access to dynamic data via a raw data feed, not encapsulated as a proof. Are you able to explain that piece or point us to a reference document?
pknowles (Sun, 02 Dec 2018 21:18:43 GMT):
@swcurran From @harrihoo - "It’s a special marriage of OAuth2 and Indy agents :slightly_smiling_face: - for the initial messaging diagrams you can have a look at this: https://docs.google.com/presentation/d/1KqB7clTef6aMXISCW34MgX6ycfhmRGQrgE2vYuCmB08/edit?usp=sharing "
pknowles (Sun, 02 Dec 2018 21:18:43 GMT):
@swcurran From @harrihoo : "It’s a special marriage of OAuth2 and Indy agents :slightly_smiling_face: - for the initial messaging diagrams you can have a look at this: https://docs.google.com/presentation/d/1KqB7clTef6aMXISCW34MgX6ycfhmRGQrgE2vYuCmB08/edit?usp=sharing "
mtfk (Mon, 03 Dec 2018 07:46:28 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=7RjLgFDesYJM8jXHz) @darrell.odonnell @darrell.odonnell Base on my understanding one of possible way to make it work could be like this: you use schema + overlays to describe verifiable credential structure. Let say your verifiable credential is issued by Credit Union and could look like this:
```
SCHEMA = {
did: "did:sov:abcdefg123455",
name: 'Dream state',
description: "Created by Darrell",
version: '1.0',
attr_names: {
MemberSince: Date,
InstitutionName: String
AverageMonthlyBalance: Double,
GoodCustomerStanding: Integer
},
consent: "did:schema:27312381238123", # reference to consent schema
# Attributes flagged according to the Blinding Identity Taxonomy
# by the issuer of the schema
bit_attributes: ["MemberSince"],
}
```
Next when you create verifiable credentials according to the schema you bind static variables same way as you do it now (including ZKP) and for dynamic attributes likes `AverageMonthlyBalance` you bind it to the did source. Let say that overlay could look like this:
```
DYNAMIC_OVERLAY = {
did: "did:sov:57ass8abcd",
type: "spec/overlay/1.0/dynamic",
name: "Dynamic Overlay for Dream State",
dynamic_attributes: {
AverageMonthlyBalance: "did:sov:0987poiu",
GoodCustomerStanding: "did:sov:0987poiu",
}
}
```
Which basically mean that you bind attribute `AverageMonthlyBalance` and `GoodCustomerStanding` to specific source from where they can come. Which could mean that each time when you would fetch the dynamic attributes they have to be signed by those specific DID's defined in that overlay.
Would that work/make sens?
mtfk (Mon, 03 Dec 2018 07:46:28 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=7RjLgFDesYJM8jXHz) @darrell.odonnell Base on my understanding one of possible way to make it work could be like this: you use schema + overlays to describe verifiable credential structure. Let say your verifiable credential is issued by Credit Union and could look like this:
```
SCHEMA = {
did: "did:sov:abcdefg123455",
name: 'Dream state',
description: "Created by Darrell",
version: '1.0',
attr_names: {
MemberSince: Date,
InstitutionName: String
AverageMonthlyBalance: Double,
GoodCustomerStanding: Integer
},
consent: "did:schema:27312381238123", # reference to consent schema
# Attributes flagged according to the Blinding Identity Taxonomy
# by the issuer of the schema
bit_attributes: ["MemberSince"],
}
```
Next when you create verifiable credentials according to the schema you bind static variables same way as you do it now (including ZKP) and for dynamic attributes likes `AverageMonthlyBalance` you bind it to the did source. Let say that overlay could look like this:
```
DYNAMIC_OVERLAY = {
did: "did:sov:57ass8abcd",
type: "spec/overlay/1.0/dynamic",
name: "Dynamic Overlay for Dream State",
dynamic_attributes: {
AverageMonthlyBalance: "did:sov:0987poiu",
GoodCustomerStanding: "did:sov:0987poiu",
}
}
```
Which basically mean that you bind attribute `AverageMonthlyBalance` and `GoodCustomerStanding` to specific source from where they can come. Which could mean that each time when you would fetch the dynamic attributes they have to be signed by those specific DID's defined in that overlay.
Would that work/make sens?
mtfk (Mon, 03 Dec 2018 07:46:28 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=7RjLgFDesYJM8jXHz) @darrell.odonnell Base on my understanding one of possible way to make it work for dynamic/static attributes could be like this: you use schema + overlays to describe verifiable credential structure. Let say your verifiable credential is issued by Credit Union and could look like this:
```
SCHEMA = {
did: "did:sov:abcdefg123455",
name: 'Dream state',
description: "Created by Darrell",
version: '1.0',
attr_names: {
MemberSince: Date,
InstitutionName: String
AverageMonthlyBalance: Double,
GoodCustomerStanding: Integer
},
consent: "did:schema:27312381238123", # reference to consent schema
# Attributes flagged according to the Blinding Identity Taxonomy
# by the issuer of the schema
bit_attributes: ["MemberSince"],
}
```
Next when you create verifiable credentials according to the schema you bind static variables same way as you do it now (including ZKP) and for dynamic attributes likes `AverageMonthlyBalance` you bind it to the did source. Let say that overlay could look like this:
```
DYNAMIC_OVERLAY = {
did: "did:sov:57ass8abcd",
type: "spec/overlay/1.0/dynamic",
name: "Dynamic Overlay for Dream State",
dynamic_attributes: {
AverageMonthlyBalance: "did:sov:0987poiu",
GoodCustomerStanding: "did:sov:0987poiu",
}
}
```
Which basically mean that you bind attribute `AverageMonthlyBalance` and `GoodCustomerStanding` to specific source from where they can come. Which could mean that each time when you would fetch the dynamic attributes they have to be signed by those specific DID's defined in that overlay.
Would that work/make sens?
mtfk (Mon, 03 Dec 2018 07:46:28 GMT):
@darrell.odonnell Base on my understanding one of possible way to make it work for dynamic/static attributes could be like this: you use schema + overlays to describe verifiable credential structure. Let say your verifiable credential is issued by Credit Union and could look like this:
```
SCHEMA = {
did: "did:sov:abcdefg123455",
name: 'Dream state',
description: "Created by Darrell",
version: '1.0',
attr_names: {
MemberSince: Date,
InstitutionName: String
AverageMonthlyBalance: Double,
GoodCustomerStanding: Integer
},
consent: "did:schema:27312381238123", # reference to consent schema
# Attributes flagged according to the Blinding Identity Taxonomy
# by the issuer of the schema
bit_attributes: ["MemberSince","InstitutionName"],
}
```
Next when you create verifiable credentials according to the schema you bind static variables same way as you do it now (including ZKP) and for dynamic attributes likes `AverageMonthlyBalance` you bind it to the did source. Let say that overlay could look like this:
```
DYNAMIC_OVERLAY = {
did: "did:sov:57ass8abcd",
type: "spec/overlay/1.0/dynamic",
name: "Dynamic Overlay for Dream State",
dynamic_attributes: {
AverageMonthlyBalance: "did:sov:0987poiu",
GoodCustomerStanding: "did:sov:0987poiu",
}
}
```
Which basically mean that you bind attribute `AverageMonthlyBalance` and `GoodCustomerStanding` to specific source from where they can come. Which could mean that each time when you would fetch the dynamic attributes they have to be signed by those specific DID's defined in that overlay.
Would that work/make sens?
mtfk (Mon, 03 Dec 2018 07:49:52 GMT):
So even when you agree on something by creating verifiable credentials you agree on the specific static fields right away and on some dynamic attributes just agree who in the future would deliver those attributes (so you create trusted binding between attribute and some entity (his did) which commit to provide it/update it in the future)
mtfk (Mon, 03 Dec 2018 07:49:52 GMT):
So by creating verifiable credentials you agree on the specific static fields right away and on some dynamic attributes just agree who in the future would deliver those attributes (so you create trusted binding between attribute and some entity (his did) which commit to provide it/update it in the future)
mtfk (Mon, 03 Dec 2018 07:49:52 GMT):
So by creating verifiable credentials you agree on the specific data for static fields right away and for dynamic attributes you agree who in the future would deliver the data for them (so you create trusted binding between attribute and some entity (it's/his did) which commit to provide it/update it in the future)
swcurran (Mon, 03 Dec 2018 11:40:51 GMT):
@mtfk - who do you see fetching the dynamic data - the Holder/Prover or the Verifier? I think it would have to be the Holder/Prover, and that the data would be signed by the Issuer using the DID associated with the Credential Definition. I don't think the Verifier could get it directly, since there would not be a way to prevent the Verifier from sharing (without consent) the endpoint. If the Holder/Prover, why not just get an updated Credential with the latest info?
Alternatively does it make sense to just have this handled at the Agent-to-Agent message level vs. in the proof process? E.g. do overlays bring value to this? Alternatively, specifically add this to the proof process a
Separate observation: It seems like the concept here is tightly tied to the Issuer and hence the Credential Definition vs an Overlay. Perhaps a Credential Definition should have an optional Overlay included with it for handling these situations that are clearly Issuer-specific. Non-Issuer specific Overlays would be used for more cross-cutting concerns - e.g. language translations, conditional handling, etc.
swcurran (Mon, 03 Dec 2018 11:40:51 GMT):
@mtfk - who do you see fetching the dynamic data - the Holder/Prover or the Verifier? I think it would have to be the Holder/Prover, and that the data would be signed by the Issuer using the DID associated with the Credential Definition. I don't think the Verifier could get it directly, since there would not be a way to prevent the Verifier from sharing (without consent) the endpoint. If the Holder/Prover, why not just get an updated Credential with the latest info?
Alternatively does it make sense to just have this handled at the Agent-to-Agent message level vs. in the proof process? E.g. do overlays bring value to this? Alternatively, specifically add this to the proof process claims that are "signed but not provable", that can be filled in at proof time.
Separate observation: It seems like the concept here is tightly tied to the Issuer and hence the Credential Definition vs an Overlay. Perhaps a Credential Definition should have an optional Overlay included with it for handling these situations that are clearly Issuer-specific. Non-Issuer specific Overlays would be used for more cross-cutting concerns - e.g. language translations, conditional handling, etc.
swcurran (Mon, 03 Dec 2018 11:45:41 GMT):
One way for the Verifier to get the data directly from the Issuer without risk of them sharing endpoint access would be for the Holder/Prover (e.g. the Customer of the Credit Union in Darrell's case) to issue a Verifiable Credential to the 3rd party to authorize them to get data from the Issuer. This is a form of the Delegation of Authority pattern that we think will be very common in the future.
mwherman2000 (Mon, 03 Dec 2018 12:00:45 GMT):
@darrell.odonnell If you think about this more broadly (i.e. any NFE), some (a few) might evolve over time or need to be corrected, I suggested you look at a generalized approach to created time-sequenced or versioned NFEs on Indy-Sovrin ...essentially think of Indy-Sovrin as a write-only database ...how do you represent changes/updates on a write-only database?
mwherman2000 (Mon, 03 Dec 2018 12:00:45 GMT):
@darrell.odonnell If you think about this more broadly (i.e. any NFE), some (a few) might evolve over time or need to be corrected, I suggested you look at a generalized approach to created time-sequenced or versioned NFEs on Indy-Sovrin ...essentially think of Indy-Sovrin as a write-only database ...how do you represent changes/updates on a write-only database? e.g. Ethereum or NEO.
mwherman2000 (Mon, 03 Dec 2018 12:00:45 GMT):
@darrell.odonnell If you think about this more broadly (i.e. any NFE), the values of some attributes for some entity types (only a few by definition) might evolve over time or need to be corrected, I suggest you look at a generalized approach to created time-sequenced or versioned NFEs on Indy-Sovrin ...essentially think of Indy-Sovrin as a write-only database ...how do you represent entity changes/updates on a write-only database? e.g. Ethereum or NEO.
mwherman2000 (Mon, 03 Dec 2018 12:00:45 GMT):
@darrell.odonnell If you think about this more broadly (i.e. any NFE), the values of some attributes for some entity types (only a few by definition) might evolve over time or need to be corrected, I suggest you look at a generalized approach to created time-sequenced or versioned NFEs on Indy-Sovrin ...essentially think of Indy-Sovrin as a write-only database ...how do you represent entity changes/updates on a write-only database? e.g. Ethereum or NEO or the Stratis Platform
mwherman2000 (Mon, 03 Dec 2018 12:02:16 GMT):
Reference 1: https://medium.com/@mwherman2000/best-way-to-store-secure-immutable-auditable-historized-permanent-data-stored-on-the-69a874ee17cd
mwherman2000 (Mon, 03 Dec 2018 12:02:16 GMT):
Reference 1: https://github.com/mwherman2000/serentitydapps/blob/master/SerentityDapp.Perfmon/README.md
Reference 2: https://medium.com/@mwherman2000/best-way-to-store-secure-immutable-auditable-historized-permanent-data-stored-on-the-69a874ee17cd
mwherman2000 (Mon, 03 Dec 2018 12:03:21 GMT):
Reference 2: https://github.com/mwherman2000/serentitydapps/blob/master/SerentityDapp.Perfmon/README.md
mwherman2000 (Mon, 03 Dec 2018 12:03:21 GMT):
Reference 2: https://github.com/mwherman2000/serentitydapps/blob/master/SerentityDapp.Perfmon/README.mdReference 2: https://github.com/mwherman2000/serentitydapps/blob/master/SerentityDapp.Perfmon/README.md
mwherman2000 (Mon, 03 Dec 2018 12:08:20 GMT):
@darrell.odonnell Another approach is to created an aggregated entity that aggregated separate entities of two classes: static and dynamic.
mwherman2000 (Mon, 03 Dec 2018 12:08:20 GMT):
@darrell.odonnell Another approach is to create an aggregated entity that aggregates (by reference) separate entities of two classes: static and dynamic.
mwherman2000 (Mon, 03 Dec 2018 12:08:20 GMT):
@darrell.odonnell Another approach is to create an aggregated entity that aggregates (by reference) separate entities of two classes: static and dynamic. This diagram...
mwherman2000 (Mon, 03 Dec 2018 12:08:20 GMT):
@darrell.odonnell Another approach is to create an aggregated entity that aggregates (by reference) separate entities of two classes: static and dynamic. Something like this diagram...
mwherman2000 (Mon, 03 Dec 2018 12:10:08 GMT):
HBB-Gumball Protocol-Indy-Sovrin-Mapping v0.4-Small.png
pknowles (Mon, 03 Dec 2018 13:18:35 GMT):
@swcurran I haven't thought about it in any great detail but there might also be a case of using Overlays on top of Credential Definitions [Cc: @kenebert @brentzundel ]. This new data architecture allows maximum flexibility so we might be able to utilise Overlays on top of other data structures, not just Schemas.
pknowles (Mon, 03 Dec 2018 13:18:35 GMT):
@swcurran I haven't thought about it in any great detail but there might also be a case of using Overlays on top of Credential Definitions, etc. [Cc: @kenebert @brentzundel ]. This new data architecture allows maximum flexibility so we might be able to utilise Overlays on top of other data structures, not just Schemas.
pknowles (Mon, 03 Dec 2018 13:18:35 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=pSjrk2pgMiH4M25td) @swcurran Gotcha
swcurran (Mon, 03 Dec 2018 13:21:35 GMT):
I don't mean an Overlay on top of Cred Def - rather that an Issuer could specify a Schema Overlay as part of a Cred Def where there was a desire for the Issuer to be able to count on the use of an Overlay, vs. it being up to the Prover/Holder or Verifier to use Overlays.
swcurran (Mon, 03 Dec 2018 13:21:35 GMT):
I don't mean an Overlay on top of Cred Def - rather that an Issuer could specify a Schema Overlay as part of a Cred Def where there was a desire for the Issuer to be able to count on the use of that Overlay, vs. it being up to the Prover/Holder or Verifier to use Overlays.
darrell.odonnell (Mon, 03 Dec 2018 13:41:15 GMT):
@swcurran - so a Driver Licence could come with a couple of overlays: full, age_of_majority
swcurran (Mon, 03 Dec 2018 13:42:56 GMT):
I don't think so - those are proof request formats. There is talk of standardizing them as well - making them available somewhere.
mtfk (Mon, 03 Dec 2018 22:37:24 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=rZiPxEHqzE3b4c6mr) @swcurran @swcurran I think that Holder of the data/issuer of verifiable credential or holder of it (it could be an agent, data vault, smart contract with access to the data or authorize entity which keeps my data or myself). Of course your argument is valid that the credential could be updated and new credential could be issued. If that is the case then schema&overlays probably won't play any role here (maybe except being use to prepare claim in first place). But for data which changes regularly like bank account balance, heartbeat or any continues stream of information sounds like overkill. I am not sure if my way of thinking about those stuff is correct but this how I would see it:
* User need to share information about his bank account to Third party company. He request from the bank that he would like to receive verifiable credential that he is their customer (MemberSince, InstitutionName - static fields) and that his AvarageBalance (dynamic fields) over months is always positive.
* Bank pull out schema (did:sov:1234) representing that verifiable credentials (here schema&overlays could come handy since they could have one schema with multiple overlays for different customers)
* Bank issue verifiable credential
* Now user login to Third Party company from where he received request to prove that his DID holds credential for schema (did:sov:1234) which is backed by bank. My understanding that the verifiable credential could be stored in agent or in bank directly where each time could be amended/updated for dynamic data, but it could be also stored within my Digital Wallet where can not be updated. But if we would use schema&overlays I could receive the request in my digital wallet where claim is stored and prove that without looking up anywhere. For example with ZKP I could prove that I own claim that I am a member of a bank longer then one year, with AvarageBalance - positive for last few months. Since everything would be tied to schema each piece of information can be proven (even those dynamic one - as we can trust the source of the data and by whom it would be signed)
Not sure if I am not over engineering anything here but putting schema&overlays as a universal language to talk about structure of data seems very handy when schema&overlays are identify via DID and stored in immutable storage. This gives possibility to make sure that the communication is easier and much secure within decentralize ecosystem.
mtfk (Mon, 03 Dec 2018 22:37:24 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=rZiPxEHqzE3b4c6mr) @swcurran @swcurran I think that Holder of the data/issuer of verifiable credential or holder of it (it could be an agent, data vault, smart contract with access to the data or authorize entity which keeps my data or myself). Of course your argument is valid that the credential could be updated and new credential could be issued. If that is the case then schema&overlays probably won't play any role here (maybe except being use to prepare claim in first place). But for data which changes regularly like bank account balance, heartbeat or any continues stream of information sounds like overkill. I am not sure if my way of thinking about those stuff is correct but this how I would see it:
* User need to share information about his bank account to Third party company. He request from the bank that he would like to receive verifiable credential that he is their customer (MemberSince, InstitutionName - static fields) and that his AvarageBalance (dynamic fields) over months is always positive.
* Bank pull out schema (did:sov:1234) representing that verifiable credentials (here schema&overlays could come handy since they could have one schema with multiple overlays for different customers)
* Bank issue verifiable credential
* Now user login to Third Party company from where he received request to prove that his DID holds credential for schema (did:sov:1234) which is backed by bank. My understanding that the verifiable credential could be stored in agent or in bank directly where each time could be amended/updated for dynamic data, but it could be also stored within my Digital Wallet where can not be updated. But if we would use schema&overlays I could receive the request in my digital wallet where claim is stored and prove that without looking up anywhere. For example with ZKP I could prove that I own claim that I am a member of a bank longer then one year, with AvarageBalance - positive for last few months. Since everything would be tied to schema each piece of information can be proven (even those dynamic one - as we can trust the source of the data and by whom it would be signed)
Not sure if I am not over engineering anything here but putting schema&overlays as a universal language to talk about structure of data seems very handy when schema&overlays are identify via DID and stored in immutable storage. This gives possibility to make sure that the communication is easier and much secure within decentralize ecosystem.
mtfk (Mon, 03 Dec 2018 22:37:24 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=rZiPxEHqzE3b4c6mr) @swcurran I think that Holder of the data/issuer of verifiable credential or holder of it (it could be an agent, data vault, smart contract with access to the data or authorize entity which keeps my data or myself). Of course your argument is valid that the credential could be updated and new credential could be issued. If that is the case then schema&overlays probably won't play any role here (maybe except being use to prepare claim in first place). But for data which changes regularly like bank account balance, heartbeat or any continues stream of information sounds like overkill. I am not sure if my way of thinking about those stuff is correct but this how I would see it:
* User need to share information about his bank account to Third party company. He request from the bank that he would like to receive verifiable credential that he is their customer (MemberSince, InstitutionName - static fields) and that his AvarageBalance (dynamic fields) over months is always positive.
* Bank pull out schema (did:sov:1234) representing that verifiable credentials (here schema&overlays could come handy since they could have one schema with multiple overlays for different customers)
* Bank issue verifiable credential
* Now user login to Third Party company from where he received request to prove that his DID holds credential for schema (did:sov:1234) which is backed by bank. My understanding that the verifiable credential could be stored in agent or in bank directly where each time could be amended/updated for dynamic data, but it could be also stored within my Digital Wallet where can not be updated. But if we would use schema&overlays I could receive the request in my digital wallet where claim is stored and prove that without looking up anywhere. For example with ZKP I could prove that I own claim that I am a member of a bank longer then one year, with AvarageBalance - positive for last few months. Since everything would be tied to schema each piece of information can be proven (even those dynamic one - as we can trust the source of the data and by whom it would be signed)
Not sure if I am not over engineering anything here but putting schema&overlays as a universal language to talk about structure of data seems very handy when schema&overlays are identify via DID and stored in immutable storage. This gives possibility to make sure that the communication is easier and much secure within decentralize ecosystem.
brentzundel (Tue, 04 Dec 2018 18:05:11 GMT):
is there a call today?
pknowles (Tue, 04 Dec 2018 20:04:36 GMT):
@brentzundel No. The call takes place bi-weekly, every other Tuesday. The next one is on December 11th.
brentzundel (Tue, 04 Dec 2018 20:06:02 GMT):
I figured it out eventually :)
pknowles (Wed, 05 Dec 2018 10:46:52 GMT):
We’re starting to get new use cases from members of the Hyperledger Indy community so, regarding the format of the biweekly *Semantics WG* calls, I thought we could concentrate on (i.) 1 x *advanced model presentation* (15 mins) and (ii.) 1 x *new use case* with input from the Schemas/Overlays team (approx. 10-15 mins) and the Verifiable Credentials team (approx. 10-15 mins). The 2nd of these items would be a 30 minute brainstorming session. When an advanced model presentation is not on the agenda, we may try to tackle two new use cases per call. I also think that we should increase the duration of these calls by 15 minutes (from 1 hour to 1 hour 15 minutes) so that we’re not pressed for time. Any further input regarding the format of these calls is most welcome.
pknowles (Wed, 05 Dec 2018 12:06:06 GMT):
I'm looking for a dedicated note taker to document discussions from the *Semantics WG* calls. Any takers?
pknowles (Wed, 05 Dec 2018 12:06:06 GMT):
I'm also looking for a dedicated note taker to document discussions from the *Semantics WG* calls. Any takers?
brentzundel (Wed, 05 Dec 2018 22:57:25 GMT):
After reflecting on the notion of dynamic data, I am very uncomfortable with the idea of a holder granting a verifier access to the issuer. This is a bad idea.
The holder would no longer be in control of what data the verifier may receive. This subverts self-sovereign identity.
Live access is not necessary, if a credential is no longer valid, the issuer should revoke it.
I've seen descriptions of this where the access token provided by the holder to the verifier contains the holder's DID that is pairwise with the issuer. This completely negates any correlation and issuer-holder collusion protection the pairwise DID is supposed to provide.
Even the capacity of the holder to revoke the verifier's access to the issuer is a matter of trusting the issuer.
This feels like it's going in the opposite direction we want, with the verifier and issuer retaining more control over the holder's data, and the verifier getting even more of the holder's data than was possible before.
Instead of a holder having control of his data independent of the issuer, and selectively disclosing it to whichever verifiers he wishes, this notion provides more control to the issuer, who will see every verifier that comes along and know exactly what data they've retrieved. The whole idea that the holder has a different "identity" with the issuer than he has with the verifier is completely lost here.
The worst part is that this new anti-pattern of over sharing comes with the "consent" of the holder.
pknowles (Thu, 06 Dec 2018 04:48:39 GMT):
@brentzundel I agree with you entirely. See my next post!
pknowles (Thu, 06 Dec 2018 04:51:01 GMT):
Going back to the credit union use case outlined by @darrell.odonnell , the individual is not an actor in the transaction. We need a verifiable credential that contains four variables, two static (MemberSince, InstitutionName) and two dynamic (AverageMonthlyBalance, GoodCustomerStanding). In this particular case, as these data points have been algorithmically generated by the credit union [CU1], they are the “Holder” and the “Verifier” of that data. The “Issuer” might be another credit union [CU2] who would be requesting verified data from the first credit union [CU1].
So …
CU2 issues a schema to CU1 containing …
MemberSince
InstitutionName
AverageMonthlyBalance
GoodCustomerStanding
CU1 (with their “Holder” hat on) determines whether or not they are happy to share that data and, if so, (with their “Verifier” hat on) sends the Verifiable Credential to CU2.
Going back to the Dynamic Overlay suggestion by @mtfk , the overlay (specifying DID references to the two dynamic variables) would go on top of the credential not the schema.
Does that seem reasonable?
[Cc: @swcurran , @mtfk , @darrell.odonnell , @brentzundel ]
swcurran (Thu, 06 Dec 2018 05:52:11 GMT):
@pknowles - I'm really confused. That does not make sense to me at all. How about we take this to a Google Doc and use that as a forum to make progress. Among the pieces that don't make sense - the concept of issuing a schema, and that it appears to be two Credit Unions exchanging data about a customer without the customer involved? That definitely doesn't see right.
swcurran (Thu, 06 Dec 2018 05:58:50 GMT):
@brentzundel - I think there may be use cases where the volume and frequency of data precludes the use of all data flowing from the Issuer to the Holder to the Verifier. The @darrell.odonnell example is one that is fine (monthly updates, two aggregate data values - monthly VerCred issuances). However, what about the case of Mint or QuickBooks services getting a feed of all bank account transactions for the client? I think that is one where the flow would be challenging. Again - it might be OK, but for a big organization with many transactions - it's tricky.
swcurran (Thu, 06 Dec 2018 06:17:19 GMT):
@brentzundel - I think there may be use cases where varying from the strict - Issuer to Holder to Verifier data flow may be useful. In @darrell.odonnell's case, perhaps not - it's just two values monthly, so a Verifiable Credential is fine. But look at the case of services like Mint and QuickBooks that need near-real time access to all bank account transactions? The volume increases with IoT devices. Does the pure Verifiable Creds flow model always work for those?
In that case (Bank, Client, Service), I had thought a model like this might work (which I think is what @harrihoo did - I haven't reread his paper though).
- the Bank gives the Client a unique token (a capability) in a verifiable credential
- the Client issues a Verifiable Credential to the Service with that token
- the Service proves that token to the Bank each time it requests data (including proving non-revocation).
- Aside - on first use, the Bank might confirm with the Client if there were possibilities of a Verifier sharing the token - not sure on the tech there.
- the Bank sends non-verifiable credential data (but likely signs the data) to the Service.
- the Client can revoke the VerfCred sent to the Service at any time.
The "pure VC" alternative is that same setup is done with VerfCreds and automated processing by the SSI Agents from the Bank -> Client -> Service, but the net effect is the same - the Client only gets involved when they want to change the automation - e.g. cut off the Service. The challenge with this approach is that there is a lot more overhead involved - lots of asynch communications. This might be the way to go, but at this stage, that seems more challenging.
pknowles (Thu, 06 Dec 2018 07:37:05 GMT):
@swcurran @brentzundel I do think we should figure out a one-size-fits-all model re dynamic data so that we have some solid guidelines to follow. Let me go through @harrihoo 's model in more detail and then we can start a Google Doc. It may be a two stage process to get consent from the customer in the first instance. Once that consent is given, I stand by my logic.
drummondreed (Fri, 07 Dec 2018 06:34:25 GMT):
Guys, FYI, @peacekeeper and the OASIS XDI Technical Committee members ran into this same pattern several years ago, just using different terminology. I think it's fairly common for a Verifier, when offering some service to a Holder, to want to establish a subscription to some data (or a proof of some data) about the Holder from an Issuer (bank balance being an example). At a high level there are two basic patterns:
1) *Direct Connection.* The Holder uses a VC to authorize a new direct connection between the Verifier and the Issuer. Done right, this connection has it's own pairwise pseudonymous DIDs between the Verifier and Issuer that are NOT the same as the pairs the Holder has with the Verifier and Issuer, respectively. So privacy can still be preserved. The Holder continues to control authorization of this connection for as long as the Holder wants the Verifier to have it (and the Issuer supports it). And this direct connection can either pull or push updates to the claim values.
2) *Proxy Connection*. The Holder uses a VC to authorize the Verifier to dynamically request the current claim value (e.g., a bank balance) from the Holder's cloud agent, who in turn proxies that request from the Holder directly back to the Issuer. The Issuer issues the updated claim value to the Holder's cloud agent, who then responds with the proof to the Veriifer. No additional pairwise pseudonymous DIDs need to be issued or shared; all privacy is preserved; and the Verifier now effectively has a pull-based subscription to the claim value. This same scenario can be set up for push as well. But for the proof to flow automatically, the Holder has to trust its cloud agent to produce the proof.
pknowles (Fri, 07 Dec 2018 07:51:01 GMT):
Thanks, @drummondreed ! That's super helpful. During our week in Basel, @mtfk and I will hash out a design to deal with dynamic variables using consent and dynamic overlays on credentials and/or schemas. Once we're close, I'll run it by experts like you, @swcurran , etc. for valued opinions.
swcurran (Fri, 07 Dec 2018 08:06:11 GMT):
That makes sense, @drummondreed - thanks for the overview. Sounds like we are in sync. We'll chat in Basel!
anttikettunen (Fri, 07 Dec 2018 08:09:30 GMT):
@pknowles & @swcurran et al. I'm also interested in joining this discussion. Our team (Tieto) did the company identity project (aka Mercury) which also did a very quick-n-dirty VC-solution, similar to what @harrihoo did. I also now have few cases on the table where different types of consent models and "key verification without connection" -pattern is needed.
swcurran (Fri, 07 Dec 2018 08:10:48 GMT):
@anttikettunen - if you are going to Basel, we can discuss there. If online (and perhaps as well) - perhaps create a google doc outlining the parameters of the use case?
anttikettunen (Fri, 07 Dec 2018 08:11:31 GMT):
Yeah, a doc would be good, as I'm unlikely to be in Basel due to multiple deadlines at work before holiday season... :(
anttikettunen (Fri, 07 Dec 2018 08:12:18 GMT):
Mercury VC model
anttikettunen (Fri, 07 Dec 2018 08:13:17 GMT):
This is essentially the same on high level as with @harrihoo's design.
pknowles (Fri, 07 Dec 2018 08:13:50 GMT):
I've started a document outlining the Credit Union use case. It has a few holes in it but we're off to the races. @mtfk will add his thoughts and then I'll Google Doc it and post in this channel for review.
anttikettunen (Fri, 07 Dec 2018 08:14:09 GMT):
I'm not yet familiar with the overlays and what it enables, so I need to dive deeper there first.
anttikettunen (Fri, 07 Dec 2018 08:14:42 GMT):
I will also have multiple use cases to add, but I need to flesh them out first with the customers.
pknowles (Fri, 07 Dec 2018 08:16:02 GMT):
@anttikettunen We're still pre-HIPE on Overlays but the best working document is *Overlays* - https://github.com/mitfik/overlays-demo/blob/master/SOD.md
pknowles (Fri, 07 Dec 2018 08:16:02 GMT):
@anttikettunen We're still pre-HIPE on *Overlays* but the best working document is https://github.com/mitfik/overlays-demo/blob/master/SOD.md
pknowles (Fri, 07 Dec 2018 08:16:02 GMT):
@anttikettunen We're still pre-HIPE on overlays but the best working document is https://github.com/mitfik/overlays-demo/blob/master/SOD.md
pknowles (Fri, 07 Dec 2018 08:19:24 GMT):
The next *Semantics WG* meeting will take place on *Tuesday, December 11th*. These calls provide an opportunity for Hyperledger Indy community members to discuss data capture and semantics initiatives. Anyone is welcome to join the call.
Here is the agenda and dial-in information for next Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 11th December, 2018
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• *Advanced model presentation*: Consent Receipt model (Presenter: @JanL ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• *Use case*: Working with dynamic variables (Member query: @darrell.odonnell ) - 30 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Fri, 07 Dec 2018 08:19:24 GMT):
The next *Semantics WG* meeting will take place on *Tuesday, December 11th*. These calls provide an opportunity for Hyperledger Indy community members to discuss data capture and semantics initiatives. Anyone is welcome to join the call.
Here is the agenda and dial-in information for next Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 11th December, 2018
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• *Advanced model presentation*: Consent Receipt model (Presenter: @janl ) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• *Use case*: Working with dynamic variables (Member query: @darrell.odonnell ) - 30 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
brentzundel (Fri, 07 Dec 2018 19:12:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=ehFfM6tTZiDGDvtDM) @swcurran In order for the Client to issue the verifiable credential (and have the ability to revoke it) it would need a DID on the ledger, and right now the plan is to not put DIDs on the ledger for pairwise connections. I'm think that requiring a bank account holder to become a public entity in order to enable a service live access to that holder's account is a bad idea.
But that is beside the point, allowing a service live access to my personal data is already a bad idea, unless a way can be come up with that gives the holder complete control. Granting live access to my personal data is an anti-pattern.
None of the suggested protocols I've seen seem to fit with the stated principles of self-sovereign identity, so from my perspective, the answer to the question, "can Sovrin support this use case?" is, "No"
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @JanL 5 ^^^ See @brentzundel 's comment above. This is totally in line with Jan's *Consent* work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel attendees are happy, we'll send it over to Jan to ensure that the proposal fits in with Jan's consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @JanL 5 ^^^ See @brentzundel 's comment above. This is totally in line with Jan's *consent* work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel attendees are happy, we'll send it over to Jan to ensure that the proposal fits in with his consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @JanL 5 , see @brentzundel 's comment above ^^^. This is totally in line with Jan's *consent* work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel attendees are happy, we'll send it over to Jan to ensure that the proposal fits in with his consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @JanL 5 , see @brentzundel 's comment above ^^^. This is totally in line with Jan's *consent* modelling work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel attendees are happy, we'll send it over to Jan to ensure that the proposal fits in with his consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @JanL 5 , see @brentzundel 's comment above ^^^. This is totally in line with Jan's *consent modelling* work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel attendees are happy, we'll send it over to Jan to ensure that the proposal fits in with his consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @JanL 5 , see @brentzundel 's comment above ^^^. This is totally in line with Jan's *consent modelling* work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @nage , @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel crew are happy, we'll send it over to Jan to ensure that the proposal fits in with his consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
pknowles (Sat, 08 Dec 2018 04:19:57 GMT):
@mtfk @janl , see @brentzundel 's comment above ^^^. This is totally in line with Jan's *consent modelling* work. Having spoken to Robert yesterday, we'll draft an overlays solution for dynamic data usage in Basel next week which we'll run past the likes of @nage , @swcurran and @drummondreed . Data revocation will be key to that proposed solution. Once the Basel crew are happy, we'll send it over to Jan to ensure that the proposal fits in with his consent piece. Brent - I'm guessing Robert and I will have verifiable credential-related queries as we deep dive this. I'll DM you next week to arrange a call. Onwards!
AndrewHughes3000 (Sun, 09 Dec 2018 17:13:07 GMT):
Has joined the channel.
harrihoo (Mon, 10 Dec 2018 18:22:32 GMT):
User User_42 added by harrihoo.
harrihoo (Mon, 10 Dec 2018 18:26:51 GMT):
Finally on this tool also (goodbye Sovrin Slack). I (@harrihoo) and @stuorini will be glad to follow this dynamic data access drafting closely also. We've also done our fair deal of consent modeling on our past research. Where's the current Consent Overlay material to be found at?
pknowles (Mon, 10 Dec 2018 19:42:34 GMT):
@harrihoo @stuorini Great to have you guys onboard! @JanL 5 's "consent" work is in progress. I would suggest that the best link is https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
pknowles (Mon, 10 Dec 2018 19:42:34 GMT):
@harrihoo @stuorini Great to have you guys onboard! @JanL 5 's "consent" work is still in draft form but would be a good place to start. https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
pknowles (Mon, 10 Dec 2018 19:42:34 GMT):
@harrihoo @stuorini Great to have you guys onboard! @JanL 5 's "consent" work is still in draft form but would be a good place to start. https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
pknowles (Mon, 10 Dec 2018 19:42:34 GMT):
@harrihoo @stuorini Great to have you guys onboard! @janl 's "consent" work is still in draft form but would be a good place to start. https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
janl (Mon, 10 Dec 2018 20:17:27 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=4F3LRB8vZaYeG6P8M) @harrihoo We will discuss it in tomorrow's call. Looking forward to hear about your research.
pknowles (Tue, 11 Dec 2018 17:52:32 GMT):
This week's *Semantics WG* call starts in 10 minutes. Agenda Doc: https://drive.google.com/drive/u/0/folders/1kN-INYUNYB-yA8teZR3EarxcwdMMmKrl?ogsrc=32
anttikettunen (Tue, 11 Dec 2018 19:06:23 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=H4iPXfbNBEe6Xu4NA) @pknowles darnit... first I was an hour early (7pm EET instead of CET) and now I'm an hour late (due to kids)... maybe next time again...
anttikettunen (Tue, 11 Dec 2018 19:07:01 GMT):
Btw @pknowles was the meeting link ok, or did you guys finish early? https://zoom.us/j/2157245727 was empty just 15 mins ago.
pknowles (Tue, 11 Dec 2018 19:13:13 GMT):
No problem, @anttikettunen ! We finished a little early this week. We'll be squeezing in another meeting before the Christmas break though. The next call will be next Tuesday, December 18th at the same time. We'll keep the deep dive going on the *Dynamic Variable* piece. The Hyperledger Global Forum in Basel this week will enable the semantics team to flesh it out further still.
pknowles (Tue, 11 Dec 2018 19:13:13 GMT):
No problem, @anttikettunen ! We finished a little early this week. We'll be squeezing in another meeting before the Christmas break though. The next call will be next *Tuesday, December 18th* at the same time. We'll keep the deep dive going on the *Dynamic Variable* piece. The Hyperledger Global Forum in Basel this week will enable the semantics team to flesh it out further still.
wombletron (Tue, 11 Dec 2018 20:09:34 GMT):
Has joined the channel.
pknowles (Tue, 11 Dec 2018 20:19:55 GMT):
The agenda, video, notes, etc. from today's *Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, December 18th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 11 Dec 2018 20:19:55 GMT):
The agenda, video, notes, etc. from today's *Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, December 18th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
dznz (Wed, 12 Dec 2018 01:40:26 GMT):
Has joined the channel.
yisheng (Wed, 12 Dec 2018 03:41:28 GMT):
Has joined the channel.
brentzundel (Wed, 12 Dec 2018 16:01:03 GMT):
I was unable to attend the meeting today, and will not be in Basel. Please keep Nathan George @nage in the loop on dynamic variables.
pknowles (Wed, 12 Dec 2018 22:04:54 GMT):
@brentzundel - @mtfk and I will be sitting down with @nage , @drummondreed and @swcurran on either Friday or Saturday to discuss dynamic variables. I'll keep you posted.
Rantwijk (Fri, 14 Dec 2018 09:49:11 GMT):
Has joined the channel.
danielhardman (Sat, 15 Dec 2018 11:15:34 GMT):
I have created a HIPE proposal that explains the theory and conventions associated with A2A decorators. As I was discussing with @pknowles yesterday, decorators have a huge amount in common with the notion of overlays, but I hadn't realized it until yesterday. There is a section of this document that acknowledges that overlap (see "Rationale and alternatives" near the end). Would love public comment: https://github.com/hyperledger/indy-hipe/pull/71
pknowles (Sun, 16 Dec 2018 10:46:43 GMT):
@janl Keep going on https://github.com/hyperledger/indy-hipe/pull/55 . This becomes hugely important when defining a static *Consent Schema Base*. It's very important work. I'll help where I can.
pknowles (Sun, 16 Dec 2018 10:46:43 GMT):
@janl Keep going on https://github.com/hyperledger/indy-hipe/pull/55 . This becomes hugely important when defining a static *Consent Schema Base*. If you need to bounce anything off me, just shout.
pknowles (Sun, 16 Dec 2018 10:46:43 GMT):
@janl Keep going on https://github.com/hyperledger/indy-hipe/pull/55 . This becomes hugely important when defining a static *Consent Schema Base*. If you need to run anything by me, just shout. Otherwise, do as he ( @danielhardman ) say.
pknowles (Sun, 16 Dec 2018 10:46:43 GMT):
@janl Keep going on https://github.com/hyperledger/indy-hipe/pull/55 . This becomes hugely important when defining a static *Consent Schema Base*. If you need to run anything by me, just shout. Otherwise, do as he ( i.e. @danielhardman ) say!
pknowles (Sun, 16 Dec 2018 10:46:43 GMT):
@janl Keep going on https://github.com/hyperledger/indy-hipe/pull/55 . This becomes hugely important when defining a static *Consent Schema Base*. If you need to run anything by me, just shout. Otherwise, follow the Technical Ambassador comments. That will steer you in the right direction.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Re dynamic variables, in our model, there is no such thing as dynamic. As a similar analogy, think of an analog wave form as a non-interpolated stream and a digitised version and an interpolated stream of data. In your use case re dynamic data, you can either tackle it from the Issuer side in a *collectionFrequency* attribute in a linked *Consent Schema* or you can put a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer, Holder, Verifier model. If I haven't answered your question, I'll look at it from a "claims and credentials perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Re dynamic variables, in our model, there is no such thing as dynamic. As a similar analogy, think of an analog wave form as a non-interpolated form and a digitised version as an interpolated stream of data. In your use case re dynamic data, you can either tackle it from the Issuer side in a *collectionFrequency* attribute in a linked *Consent Schema* or you can put a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer, Holder, Verifier model. If I haven't answered your question, I'll look at it from a "claims and credentials perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Re dynamic variables, in our model, there is no such thing as dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as an interpolated stream of data. In your use case re dynamic data, you can either tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) by using a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer/Holder/Verifier model. If I haven't answered your question, I'll also look at it from a "claims and credentials perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Within the Sovrin model there will be no such thing as truly dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as interpolated. In your use case re dynamic data, you can either tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) by using a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer/Holder/Verifier model. If I haven't answered your question, I'll also look at it from a "claims and credentials perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Within the Sovrin model there will be no such thing as truly dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as interpolated. In your use case re dynamic data, you can either tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) by using a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer/Holder/Verifier model. If I haven't answered your question, I'll also look at it from a "claims and credentials" perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Within the Sovrin model there will be no such thing as truly dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as interpolated. In your use case re dynamic data, you can tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) by using a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer/Holder/Verifier model. If I haven't answered your question, I'll also look at it from a "claims and credentials" perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Within the Sovrin model there will be no such thing as truly dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as interpolated. In your use case re dynamic data, you can tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) you can use a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. I need to better understand your use case in the Issuer/Holder/Verifier model. If I haven't answered your question, I'll also look at it from a "claims and credentials" perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Within the Sovrin model there will be no such thing as truly dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as interpolated. In your use case re dynamic data, you can tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) you can use a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. If that doesn't answer your question, I'll need to better understand your use case so that I can describe how that might look from a "claims and credentials" perspective. In any case, it's certainly not going to be an issue.
pknowles (Sun, 16 Dec 2018 11:06:06 GMT):
@darrell.odonnell Within the Sovrin model there is no such thing as truly dynamic. As a similar analogy, think of an analog wave form as non-interpolated and a digitised version as interpolated. In your use case re dynamic data, you can tackle it from the Issuer side by using either (i.) a *collectionFrequency* attribute in a linked *Consent Schema* or (ii.) you can use a *Source Overlay* on that attribute to point to an external dynamic variable. In both cases, we're dealing with interpolation which means you're covered from a "schemas and data capture" perspective. If that doesn't answer your question, I'll need to better understand your use case so that I can describe how that might look from a "claims and credentials" perspective. In any case, it's certainly not going to be an issue.
swcurran (Sun, 16 Dec 2018 21:23:10 GMT):
@pknowles - I'm not sure there is any need for either a consent schema or an overlay for @darrell.odonnell's scenario. The way that I understood we had agreed was that we would just use the normal - issuer/holder/verifier model, but the difference would be the automation of the claim flow to avoid constant manual intervention. Assuming each party has an configurable, automated (Cloud) Agent, likely flow (but others are possible) is the following:
* The Verifier (Third Party) requests a periodic credential from the Holder (CU Customer)
* The Holder requests a Proof from the Issuer (CU)
* The Holder Proves the Claims from the Proof
All three are automated, and if any of the three want to stop the flow of data - they just stop their Agent from participating. Of course, any of the three (and in particular - the CU Customer) could choose to not automate the process and get pinged for consent on every iteration.
With the agent infrastructure in place (which isn't available yet....), I think this can be done without any extra magic. Frequency would like be handled as part of the Agent Message Family used to setup the automated process.
pknowles (Sun, 16 Dec 2018 21:32:29 GMT):
@swcurran That's very cool!
pknowles (Sun, 16 Dec 2018 21:32:29 GMT):
@swcurran That's very cool!
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will be subsequently looking at are: (i.) a _pii_attributes_ *schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a sensitive overlay which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a consent schema which can then be coupled with any schema. The exact elements will be determined according to GDPR requirements along with those necessary for @janl 's consent receipt model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing the pieces align between the "schemas and data capture" team and the "claims and credentials" team will be awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will be subsequently looking at are: (i.) a pii_attributes *schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a sensitive overlay which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a consent schema which can then be coupled with any schema. The exact elements will be determined according to GDPR requirements along with those necessary for @janl 's consent receipt model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing the pieces align between the "schemas and data capture" team and the "claims and credentials" team will be awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a pii_attributes *schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a sensitive overlay which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a consent schema which can then be coupled with any schema. The exact elements will be determined according to GDPR requirements along with those necessary for @janl 's consent receipt model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing the pieces align between the "schemas and data capture" team and the "claims and credentials" team will be awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a pii_attributes *schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will be determined according to GDPR requirements along with those necessary for @janl 's consent receipt model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing these pieces align between the "schemas and data capture" experts and the "claims and credentials" experts will be awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a pii_attributes *schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will be determined according to GDPR requirements along with those necessary for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing these semantics pieces align will be truly awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will be determined according to GDPR requirements along with those necessary for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing these semantics pieces align will be truly awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will be determined by legal regulations along with those necessary for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing these semantics pieces align will be truly awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will be determined by legal/tech requirements and will include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ]. Things are starting to get very interesting. Seeing these semantics pieces align will be truly awesome to see.
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will ultimately be determined by legal/tech requirements and will include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to a particular schema base but rather to a sensitive data repository held off-ledger. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema base* which can then be coupled with any schema. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining the exact elements defined in a *consent schema* which can then become a coupling object. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining elements to be defined in a *consent schema* which can then become a coupling object. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
BTW, @mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of days for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining elements to be defined in a *data consent schema* which can then become a coupling object. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
@mtfk and I cracked the Overlays data architecture model early yesterday morning. The HIPE will be going in within the next couple of weeks for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining elements to be defined in a *data consent schema* which can then become a coupling object. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
@mtfk and I cracked the *Overlays* data architecture model early yesterday morning. The HIPE will be going in within the next couple of weeks for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining elements to be defined in a *data consent schema* which can then become a coupling object. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
@mtfk and I cracked the *Overlays* data architecture model early yesterday morning. The HIPE will be going in within the next couple of weeks for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining attributes to be defined in a *data consent schema* which can then become a coupling object. The exact elements will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:13:28 GMT):
@mtfk and I cracked the *Overlays* data architecture model early yesterday morning. The HIPE will be going in within the next couple of weeks for review. A couple of important pieces that we will subsequently be looking at are: (i.) a *pii_attributes schema object* to allow the issuer to flag sensitive data according to the *Blinding Identity Taxonomy (BIT)* as we start to onboard. That is the Issuer's tool for flagging sensitive schema elements. On the Holder side, sensitive data can be screened courtesy of a *sensitive overlay* which is not tied to any schema. (ii.) The second interesting piece will be determining attributes to be defined in a *data consent schema* which can then become a coupling object. The exact attributes will ultimately be determined by legal/tech requirements and will obviously include capture capability for @janl 's consent model to work. [ref. https://github.com/hyperledger/indy-hipe/pull/55 ].
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
BTW, that alignment question is happening in the # indy channel right now. Keep your eye on that discussion!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
BTW, that alignment question is happening in the #indy indy channel right now. Keep your eye on that discussion!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
BTW, that alignment question is happening in the #indy channel right now. Keep your eye on that discussion!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
BTW, that alignment discussion is happening in the #indy channel right now. @brentzundel and @kenebert , keep your eye on that one!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
That alignment discussion is happening in the #indy channel right now. @brentzundel and @kenebert , keep your eye on that one!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
The discussion happening in the #indy channel right now is an important handshake. @brentzundel and @kenebert , keep your eye on that one!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
The discussion happening in the #indy channel right now is an important handshake. @brentzundel and @kenebert , keep your eye on that one too!
pknowles (Sun, 16 Dec 2018 22:21:47 GMT):
The discussion happening in the #indy channel right now is an important handshake. @brentzundel and @kenebert , keep your eye on that discussion too!
pknowles (Tue, 18 Dec 2018 01:55:13 GMT):
The final *Semantics WG* meeting of the year will take place today, *Tuesday, December 18th*. Anyone is welcome to join the call.
The call provides an opportunity for Hyperledger Indy community members to discuss data capture and semantics.
Here is the agenda and dial-in information for today's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 18th December, 2018
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Takeaways from Hyperledger Global Forum - 10 mins
• Possibility of ZK-specific Overlays - 10 mins
* Tools to capture sensitive data - 10 mins
* When identity meets semantics - 10 mins
* Consent Schema Attributes - 10 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
* Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 18 Dec 2018 02:04:52 GMT):
The final *Semantics WG* meeting of the year will take place today, *Tuesday, December 18th*.
These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Here is the agenda and dial-in information for today's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 18th December, 2018
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Quick round of participant introductions (Open) - 5 mins
• Takeaways from Hyperledger Global Forum - 10 mins
* Overlays architecture - 10 mins
• Possibility of ZK-specific Overlays - 10 mins
* Tools to capture sensitive data - 10 mins
* When identity meets semantics - 10 mins
* Consent Schema attributes - 10 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
* Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 18 Dec 2018 19:56:09 GMT):
The agenda, video, notes, etc. from today's *Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, December 18th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 18 Dec 2018 19:56:56 GMT):
The agenda, video, notes, etc. from today's *Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, January 8th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
josh.hill (Wed, 19 Dec 2018 20:29:56 GMT):
Has joined the channel.
pknowles (Sat, 22 Dec 2018 06:45:49 GMT):
*Verifiable Credentials* overview deck is now stored in the HL Indy server as a Google Doc - https://drive.google.com/drive/u/0/folders/1UxLLugRQKuV8Mdvv_X9Y6ty4szSi5ZNU?ogsrc=32
pknowles (Sat, 22 Dec 2018 06:45:49 GMT):
*Verifiable Credentials* overview deck is now stored on the HL Indy server as a Google Doc - https://drive.google.com/drive/u/0/folders/1UxLLugRQKuV8Mdvv_X9Y6ty4szSi5ZNU?ogsrc=32
infominer33 (Sun, 23 Dec 2018 22:14:04 GMT):
Has joined the channel.
andrewtan (Wed, 26 Dec 2018 01:25:06 GMT):
Has joined the channel.
mahesh_rao (Thu, 27 Dec 2018 20:41:53 GMT):
Has joined the channel.
pknowles (Sat, 29 Dec 2018 13:57:16 GMT):
In order to receive *Semantics WG call* calendar invites, please add your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Sat, 29 Dec 2018 13:57:16 GMT):
In order to receive *Semantics WG call calendar invites*, please add your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Sat, 29 Dec 2018 13:59:17 GMT):
In order to receive *Indy Semantics WG call calendar invites*, please add your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Sat, 29 Dec 2018 13:59:49 GMT):
In order to receive *Indy Semantics WG call calendar invites*, please add your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Sat, 29 Dec 2018 13:59:49 GMT):
In order to receive *Indy Semantics WG calendar invites*, please add your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Mon, 31 Dec 2018 11:34:58 GMT):
I've been heavily researching *industry classification standards* for the past 14 months and have finally settled on a proposed implementation solution to better improve data object indexing and searchability within the Hyperledger Indy ecosystem. My proposal is to utilise two publicly available classification standards for: (i.) *Global Industries* and (ii.) *New Economies*. I've stored the two ontologies, *GICS* (Global Industry Classification Standard) and *NECS* (New Economy Classification Standard) in the following HL Indy shared area. This topic will be further discussed during the Semantics WG call on January 8th. https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
mwherman2000 (Mon, 31 Dec 2018 14:46:18 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=mCrp7aomq36xSLqqa) Perhaps these classifications will be useful classifying Actors and Things (https://hyperonomy.com/2018/12/21/decentralized-identifiers-dids-architecture-reference-model-arm/) for my proposed subledger feature (https://www.cliffsnotes.com/study-guides/accounting/accounting-principles-i/subsidiary-ledgers-and-special-journals/subsidiary-ledgers) in the Trusted Digital Assistant (https://www.linkedin.com/feed/update/urn:li:activity:6479972559323484162).
mwherman2000 (Mon, 31 Dec 2018 14:46:18 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=mCrp7aomq36xSLqqa) Perhaps these classifications will be useful for classifying Actors and Things (https://hyperonomy.com/2018/12/21/decentralized-identifiers-dids-architecture-reference-model-arm/) for my proposed subledger feature (https://www.cliffsnotes.com/study-guides/accounting/accounting-principles-i/subsidiary-ledgers-and-special-journals/subsidiary-ledgers) in the Trusted Digital Assistant (https://www.linkedin.com/feed/update/urn:li:activity:6479972559323484162).
mwherman2000 (Mon, 31 Dec 2018 14:46:18 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=mCrp7aomq36xSLqqa) Perhaps these classifications will be useful for classifying Actors and Things (https://hyperonomy.com/2018/12/21/decentralized-identifiers-dids-architecture-reference-model-arm/) for my proposed subledger feature (https://www.cliffsnotes.com/study-guides/accounting/accounting-principles-i/subsidiary-ledgers-and-special-journals/subsidiary-ledgers) in the Trusted Digital Assistant `(https://www.linkedin.com/feed/update/urn:li:activity:6479972559323484162)`.
mwherman2000 (Mon, 31 Dec 2018 14:46:18 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=mCrp7aomq36xSLqqa) Perhaps these classifications will be useful for classifying Actors and Things (https://hyperonomy.com/2018/12/21/decentralized-identifiers-dids-architecture-reference-model-arm/) for my proposed subledger feature (https://www.cliffsnotes.com/study-guides/accounting/accounting-principles-i/subsidiary-ledgers-and-special-journals/subsidiary-ledgers) in the [Trusted Digital Assistant](https://www.linkedin.com/feed/update/urn:li:activity:6479972559323484162).
mwherman2000 (Mon, 31 Dec 2018 14:46:18 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=mCrp7aomq36xSLqqa) Perhaps these classifications will be useful for classifying Actors and Things (https://hyperonomy.com/2018/12/21/decentralized-identifiers-dids-architecture-reference-model-arm/) for my proposed subledger feature (https://www.cliffsnotes.com/study-guides/accounting/accounting-principles-i/subsidiary-ledgers-and-special-journals/subsidiary-ledgers) in the [Trusted Digital Assistant](https://www.linkedin.com/feed/update/urn:li:activity:6479972559323484162). ([click](https://www.linkedin.com/feed/update/urn:li:activity:6479972559323484162))
mwherman2000 (Mon, 31 Dec 2018 15:01:32 GMT):
DID Logical Architecture v0.11.png
pknowles (Tue, 01 Jan 2019 09:11:20 GMT):
Following valuable input from @danielhardman, I've started early work on a *data consent schema* build proposal detailing the necessary attributes required for data retention/revocation transactions as described in @janl 's _Consent Receipt model_ [https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt] or that a person might rightly impose before they are willing to give consent for the use of requested data. I've stored the early drafts in the following HL Indy shared area. This topic will be further discussed during the Semantics WG call on January 8th. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Tue, 01 Jan 2019 09:11:20 GMT):
Following valuable input from @danielhardman, I've started early work on a *data consent schema* build proposal detailing the necessary attributes required for data retention/revocation transactions as described in @janl 's _Consent Receipt model_ [https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt ] or that a person might rightly impose before they are willing to give consent for the use of requested data. I've stored the early drafts in the following HL Indy shared area. This topic will be further discussed during the Semantics WG call on January 8th. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
ashokkj (Wed, 02 Jan 2019 02:46:54 GMT):
Has joined the channel.
xadhoom76 (Thu, 03 Jan 2019 11:18:56 GMT):
Has joined the channel.
pknowles (Thu, 03 Jan 2019 12:17:24 GMT):
Home for all Hyperledger Indy data capture and semantics discussions including schema bases and overlays
pknowles (Fri, 04 Jan 2019 11:22:06 GMT):
As of late last night, a couple of new elements have been added to the *Blinding Identity Taxonomy (BIT)*. Updated version via link. https://drive.google.com/drive/u/0/folders/1gSD1b70OySIUKNOQTSbQ7khq9oy1V8UP?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @TomWeiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent schema base* called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ we are only sharing it for specific use cases. _PII_ can't be shared with consent for "all use cases", only for specific ones. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @TomWeiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent schema base* called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ we are only sharing it for specific use cases. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @TomWeiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent schema base* called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ , we are only sharing it for specific use cases. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @TomWeiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent* schema base called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ , we are only sharing it for specific use cases. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @TomWeiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent* _schema base_ called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ , we are only sharing it for specific use cases. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @TomWeiss @tom_weiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent* _schema base_ called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ , we are only sharing it for specific use cases. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
pknowles (Fri, 04 Jan 2019 12:00:12 GMT):
Following initial review from @tom_weiss (Thanks, Tom!), we've added a new compulsory free form text attribute into the *Data Consent* _schema base_ called (for want of a better name) `Use-Case-Description`. The point here is that legally when we share our _PII_ , we are only sharing it for specific use cases. Under GDPR, consumers have to explicitly opt-in to each use case. It's a key part of consent. If we're clever, we might be able to do some machine learning on that free form text attribute to help categorise use cases in an upgraded version further down the road. For now, it certainly addresses the issue without overcomplicating. Updated version via link. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
tom_weiss (Fri, 04 Jan 2019 12:49:49 GMT):
This is my actually account
pknowles (Fri, 04 Jan 2019 12:56:32 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=mBt5hlx4LDl6SARJPw) @tom_weiss Cool. I've requested for @TomWeiss to be deleted.
pknowles (Sun, 06 Jan 2019 08:32:58 GMT):
The first *Indy Semantics WG* meeting of the year takes place on *Tuesday, January 8th*.
These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 8th January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• Industry classification standards - 35 mins
• Consent Schema attributes - 20 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
* Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Sun, 06 Jan 2019 08:39:16 GMT):
The first *Indy Semantics WG* meeting of 2019 takes place on *Tuesday, January 8th*.
These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Semantics Working Group
Date: Tuesday, 8th January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• Industry classification standards / GICS and NECS ontologies - 30 mins
- Reference - https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
• Consent Schema attributes - 20 mins
- Reference 1 - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
- Reference 2 - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Sun, 06 Jan 2019 08:39:16 GMT):
The first *Indy Semantics WG* meeting of 2019 takes place on *Tuesday, January 8th*.
These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Indy Semantics Working Group
Date: Tuesday, 8th January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• Industry classification standards / GICS and NECS ontologies - 30 mins
- Reference - https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
• Consent Schema attributes - 20 mins
- Reference 1 - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
- Reference 2 - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Sun, 06 Jan 2019 08:39:16 GMT):
The first *Indy Semantics WG* meeting of 2019 takes place on *Tuesday, January 8th*.
These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Here is the agenda and dial-in information for Tuesday's meeting ...
Meeting: Indy Semantics Working Group
Date: Tuesday, 8th January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• Industry classification standards / GICS and NECS ontologies - 30 mins
- Reference - https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
• Data Consent schema base attributes - 20 mins
- Reference 1 - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
- Reference 2 - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Sun, 06 Jan 2019 11:27:50 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=n8Fe2YBZqjmfp62ip) I just received the following message from @apoikola on the MyData Slack channel. Jogi's suggestions are always well thought through so we should consider the following comment during Tuesday's WG meeting …
"The name of Kantara’s group ”Consent *and* Information Sharing” has two sides. My practical understanding is that consent as *one of the legal bases* for data prosessing under GDPR is not very popular, organisations do everything possible to avoid consent.
*1#* One strategy is: ”let’s make consent so easy and smooth so that it becomes more popular”.
*2#* Other strategy would be to cover all legal bases in wider information sharing framework and hope that transparency and individual’s control over their data can be achieved also in cases when consent is not used.
Personally I used to be proponent on nr. 1, but lately I have been shifting more towards 2.
Therefore my suggestion would be to make the schema ”legal base agnostic” technical means to capture the attributes and conditions related to data sharing."
pknowles (Sun, 06 Jan 2019 11:27:50 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=n8Fe2YBZqjmfp62ip) I just received the following message from @apoikola on the MyData Slack channel. Jogi's suggestions are always well thought through so we should consider the following comment during Tuesday's WG call …
"The name of Kantara’s group ”Consent *and* Information Sharing” has two sides. My practical understanding is that consent as *one of the legal bases* for data prosessing under GDPR is not very popular, organisations do everything possible to avoid consent.
*1#* One strategy is: ”let’s make consent so easy and smooth so that it becomes more popular”.
*2#* Other strategy would be to cover all legal bases in wider information sharing framework and hope that transparency and individual’s control over their data can be achieved also in cases when consent is not used.
Personally I used to be proponent on nr. 1, but lately I have been shifting more towards 2.
Therefore my suggestion would be to make the schema ”legal base agnostic” technical means to capture the attributes and conditions related to data sharing."
pknowles (Sun, 06 Jan 2019 11:27:50 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=n8Fe2YBZqjmfp62ip) I just received the following message from @apoikola on the MyData Slack channel. Jogi's suggestions are always well conceived so we should consider the following comment during Tuesday's WG call …
"The name of Kantara’s group ”Consent *and* Information Sharing” has two sides. My practical understanding is that consent as *one of the legal bases* for data prosessing under GDPR is not very popular, organisations do everything possible to avoid consent.
*1#* One strategy is: ”let’s make consent so easy and smooth so that it becomes more popular”.
*2#* Other strategy would be to cover all legal bases in wider information sharing framework and hope that transparency and individual’s control over their data can be achieved also in cases when consent is not used.
Personally I used to be proponent on nr. 1, but lately I have been shifting more towards 2.
Therefore my suggestion would be to make the schema ”legal base agnostic” technical means to capture the attributes and conditions related to data sharing."
pknowles (Sun, 06 Jan 2019 11:27:50 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=n8Fe2YBZqjmfp62ip) I just received the following message from @apoikola on the MyData Slack channel. Jogi's suggestions are always well conceived so we should consider the following comment during Tuesday's WG call …
"The name of Kantara’s group ”Consent *and* Information Sharing” has two sides. My practical understanding is that consent as *one of the legal bases* for data processing under GDPR is not very popular, organisations do everything possible to avoid consent.
*1#* One strategy is: ”let’s make consent so easy and smooth so that it becomes more popular”.
*2#* Other strategy would be to cover all legal bases in wider information sharing framework and hope that transparency and individual’s control over their data can be achieved also in cases when consent is not used.
Personally I used to be proponent on nr. 1, but lately I have been shifting more towards 2.
Therefore my suggestion would be to make the schema ”legal base agnostic” technical means to capture the attributes and conditions related to data sharing."
pknowles (Sun, 06 Jan 2019 11:27:50 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=n8Fe2YBZqjmfp62ip) I just received the following message from @apoikola on the MyData Slack channel. Jogi's suggestions are always well-conceived so we should consider the following comment during Tuesday's WG call …
"The name of Kantara’s group ”Consent *and* Information Sharing” has two sides. My practical understanding is that consent as *one of the legal bases* for data processing under GDPR is not very popular, organisations do everything possible to avoid consent.
*1#* One strategy is: ”let’s make consent so easy and smooth so that it becomes more popular”.
*2#* Other strategy would be to cover all legal bases in wider information sharing framework and hope that transparency and individual’s control over their data can be achieved also in cases when consent is not used.
Personally I used to be proponent on nr. 1, but lately I have been shifting more towards 2.
Therefore my suggestion would be to make the schema ”legal base agnostic” technical means to capture the attributes and conditions related to data sharing."
pknowles (Mon, 07 Jan 2019 02:19:05 GMT):
In order to receive *Indy Semantics WG calendar invites*, make sure you've added your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
jakubkoci (Mon, 07 Jan 2019 17:54:37 GMT):
Has joined the channel.
AndrewHughes3000 (Mon, 07 Jan 2019 23:52:45 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=gvbAB54ayFjaJsSN4) @pknowles In the Kantara CIS WG our currently-published spec is the "Consent Receipt" for a variety historical of reasons. We are making the transition towards a more general "Receipt for Personal Data Processing" which captures record-keeping details for the service provider to keep and also for the individual to keep (if they wish) - and will be applicable to any of the GDPR legal basis categories. So we are all lined up to do #2 while already covering #! (or, at least all the 'consent management' product companies are covering it)
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I prefer the wording - "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like one of terms borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (something along those lines anyway). Let's bring this point up in today's Semantics WG. [Cc: @mtfk ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing" to "Consent Receipt". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like one of terms borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (something along those lines anyway). Let's bring this point up in today's Semantics WG. [Cc: @mtfk ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing" to "Consent Receipt". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like one of the terms borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (something along those lines anyway). Let's bring this point up in today's Semantics WG. [Cc: @mtfk ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing" over "Consent Receipt". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like one of the terms borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (something along those lines anyway). Let's bring this point up in today's Semantics WG. [Cc: @mtfk ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing" over "Consent Receipt". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like one of those terms borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (something along those lines anyway). Let's bring this point up in today's Semantics WG. [Cc: @mtfk ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (something along those lines anyway). Let's bring this point up in today's Semantics WG. [Cc: @mtfk ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable! On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics WG [Cc: @mtfk ].
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics WG [Cc: @mtfk ].
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics WG call. [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics call. [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more sociable. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics call [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more socially inviting. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics call [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that, since the Facebook/Cambridge Analytica fiasco, a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more socially inviting. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's bring this point up in today's Semantics call [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that, since the Facebook/Cambridge Analytica fiasco, a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more socially inviting. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's discuss this point in today's Semantics call [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 02:46:06 GMT):
@AndrewHughes3000 I definitely prefer the wording of "Receipt for Personal Data Processing". I was just expressing to @mwherman2000 that, since the Facebook/Cambridge Analytica fiasco, a number of startups had tended towards data reclusion rather than adopting a more sensible approach to data sharing. "Consent Receipt" sounds like a term borne out of that reclusive mindset. "Receipt for Personal Data Processing" feels much more socially inviting. On that note, I'd be inclined to change the name of the current *data consent schema* to *PDP schema* (or something along those lines). Let's discuss this in today's Semantics call [Cc: @mtfk @janl ]
pknowles (Tue, 08 Jan 2019 17:48:48 GMT):
This week's *Indy Semantics WG* call starts in 10 minutes. Zoom link: https://zoom.us/j/2157245727
pknowles (Tue, 08 Jan 2019 21:48:25 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, January 8th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 08 Jan 2019 21:49:48 GMT):
The agenda, video, notes, etc. from today's *Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, January 22nd. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
tuckerg (Thu, 10 Jan 2019 16:25:42 GMT):
Has joined the channel.
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion during Tuesday's *Semantics WG* call regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define a window of access for the intended data share, we're going to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call.
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion during Tuesday's *Semantics WG* call regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define a window of access for the intended data share, we're going to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. The difference lies in the subtlety of the wording. "Consent" has a connotation of ownership. "Processing" has a connotation of mechanics. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call.
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion in the _Hyperledger Indy Semantics WG_ call last week regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define an _access window_ for the intended data share, we've decided to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. The difference lies in the subtlety of the wording. "Consent" has a connotation of _ownership_ (dictated by the _Holder_). "Processing" has a connotation of mechanics (dictated by the _Issuer_). Thanks to @apoikola and @AndrewHughes3000 for your valuable input on this topic. We might rename it further still but, at least for now, we've isolated the piece that we wish to construct. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call.
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion in the *Semantics WG* call last week regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define an _access window_ for the intended data share, we've decided to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. The difference lies in the subtlety of the wording. "Consent" has a connotation of _ownership_ (dictated by the _Holder_). "Processing" has a connotation of mechanics (dictated by the _Issuer_). Thanks to @apoikola and @AndrewHughes3000 for your valuable input on this topic. We might rename it further still but, at least for now, we've isolated the piece that we wish to construct. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call.
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion in the *Semantics WG* call last week regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define an _access window_ for the intended data share, we've decided to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. The difference lies in the subtlety of the wording. "Consent" has a connotation of _ownership_ (dictated by the _Holder_). "Processing" has a connotation of mechanics (dictated by the _Issuer_). Thanks to @apoikola and @AndrewHughes3000 for your valuable input on this topic. We might rename it further still but, at least for now, we've isolated the piece that we wish to construct. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call. [Cc: @janl ]
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion in the *Semantics WG* call last week regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define an _access window_ for the intended data share, we've decided to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. The difference lies in the subtlety of the wording. "Consent" has a connotation of _ownership_ (dictated by the _Holder_). "Processing" has a connotation of mechanics (dictated by the _Issuer_). Thanks to @apoikola and @AndrewHughes3000 for your valuable input on this topic. We might rename it further still but, at least for now, we've isolated the piece that we wish to construct. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call. [Cc: @janl @harrihoo ]
pknowles (Fri, 11 Jan 2019 07:56:38 GMT):
Following a brief discussion in the *Semantics WG* call last week regarding the original *data consent schema* proposal to capture legally required attributes related to _data consent_ and the subsequent *PDP* _[Personal Data Processing]_ *schema* to capture attributes used to define an _access window_ for the intended data share, we've decided to prioritise the latter. The data capture provided by the *PDP schema* will allow algorithmic processes to be constructed so that data can be automatically revoked once the defined access window has been closed. It is not intended to be a construct for legal consent terms. The difference lies in the subtlety of the wording. "Consent" has a connotation of _ownership_ (dictated by the _Holder_). "Processing" has a connotation of _mechanics_ (dictated by the _Issuer_). Thanks to @apoikola and @AndrewHughes3000 for your valuable input on this topic. We might rename it further still but, at least for now, we've isolated the piece that we wish to construct. We'll deep dive this topic on Tuesday, January 22nd during the next Semantics call. [Cc: @janl @harrihoo ]
pknowles (Sat, 12 Jan 2019 04:06:51 GMT):
Re *industry classification codes*, CSV versions of the *GICS* _[Global Industry Classification Standard]_ and *NECS* *[New Economy Classification Standard]* ontologies have been uploaded to the following HL Indy shared area. https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
pknowles (Sat, 12 Jan 2019 04:06:51 GMT):
Re *industry classification codes*, CSV versions of the *GICS* _[Global Industry Classification Standard]_ and *NECS* _[New Economy Classification Standard]_ ontologies have been uploaded to the following HL Indy shared area. https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
ardagumusalan (Tue, 15 Jan 2019 21:20:55 GMT):
Has joined the channel.
ardagumusalan (Tue, 15 Jan 2019 21:24:20 GMT):
Hi everyone. Are the community meetings held fixed times every week? If so when will be the next one?
pknowles (Tue, 15 Jan 2019 22:07:46 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=y2GQ67SBy54YtqZa9) @ardagumusalan The *Indy Semantics WG* calls take place bi-weekly on Tuesdays at 6.00pm - 7.15pm GMT. The next one is on Tuesday, January 22nd. In order to receive *Semantics WG calendar invites*, please add your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Wed, 16 Jan 2019 22:56:16 GMT):
The *Indy Semantics WG* calls have now been added to the *Hyperledger community calendar* (Thanks, @Sean_Bohan !!!). Here is the :calendar: link. https://calendar.google.com/calendar/embed?mode=AGENDA&src=linuxfoundation.org_nf9u64g9k9rvd9f8vp4vur23b0%40group.calendar.google.com&ctz=UTC
pknowles (Tue, 22 Jan 2019 05:19:57 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* meeting.
These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• Industry classification standards / GICS and NECS ontologies - 10 mins
- Reference - https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV?ogsrc=32
• Data Consent schema base attributes - 20 mins
- Reference 1 - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb?ogsrc=32
- Reference 2 - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 05:32:13 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• @janl ’s “Consent Receipt” model (incl. data revocation) - 15 mins
• How PDP (Personal Data Processing) schema base attributes relate to that model - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Overlays required for data extraction (@wip-abramson ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 05:32:13 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: Paul Knowles
Agenda:
• Introductions (Open) - 5 mins
• @janl ’s “Consent Receipt” model (incl. data revocation) - 15 mins
• How PDP (Personal Data Processing) schema base attributes relate to that model - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Overlays required for data extraction ( @wip-abramson ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 05:32:13 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• @janl ’s “Consent Receipt” model (incl. data revocation) - 15 mins
• How PDP (Personal Data Processing) schema base attributes relate to that model - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Overlays required for data extraction ( @wip-abramson ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 10:41:08 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• @janl ’s “Consent Receipt” model (incl. data revocation) - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt (Note: Not the latest update)
• How PDP (Personal Data Processing) schema base attributes relate to that model - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Overlays required for data extraction ( @wip-abramson ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 10:41:08 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• @janl ’s data revocation (“Consent Receipt”) model - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt (Note: Not the latest update)
• How PDP (Personal Data Processing) schema base attributes relate to that model - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Overlays required for data extraction ( @wip-abramson ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 10:41:08 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 22nd January, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• @janl ’s data revocation / consent receipt model - 15 mins
- Reference - https://github.com/JanLin/indy-hipe/tree/master/text/consent_receipt (Note: Not the latest update)
• How PDP (Personal Data Processing) schema base attributes relate to that model - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Overlays required for data extraction ( @wip-abramson ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 22 Jan 2019 17:00:19 GMT):
This week's *Indy Semantics WG* call starts in 1 hour. Zoom link: https://zoom.us/j/2157245727
pknowles (Tue, 22 Jan 2019 21:55:44 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, February 5th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 22 Jan 2019 22:18:37 GMT):
The *Indy Semantics WG* is mentioned in this month's '_Keeping up with the Kantarians_', *Kantara Initiative*'s monthly newsletter, as we plan to align consent schemas to produce a generic Kantara-compliant "Consent Receipt" that can be deployed in both Distributed Ledger and traditional networks. https://t.e2ma.net/message/ziw27/nhnlvj
pknowles (Tue, 22 Jan 2019 22:18:37 GMT):
The *Indy Semantics WG* is mentioned in this month's " _Keeping up with the Kantarians_ ", *Kantara Initiative*'s monthly newsletter, as we plan to align consent schemas to produce a generic Kantara-compliant "Consent Receipt" that can be deployed in both Distributed Ledger and traditional networks. https://t.e2ma.net/message/ziw27/nhnlvj
drummondreed (Wed, 23 Jan 2019 13:20:55 GMT):
@pknowles You are relentless! Keep going!!
ardagumusalan (Fri, 25 Jan 2019 21:47:28 GMT):
At the end of this meeting: https://www.youtube.com/watch?time_continue=67&v=0Fga1_Fz7MI schema.org is mentioned. Does it mean, support for json-ld is also part of this effort?
ardagumusalan (Fri, 25 Jan 2019 21:47:28 GMT):
At the end of this meeting: https://www.youtube.com/watch?time_continue=67&v=0Fga1_Fz7MI schema.org is mentioned. Does it mean support for json-ld is also part of this effort
pknowles (Fri, 25 Jan 2019 22:20:31 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=FdocpRhRqYe824Di6) @ardagumusalan Yes, we'll be supporting JSON-LD for the development of all Schema bases and Overlays.
peter.danko (Mon, 28 Jan 2019 11:57:34 GMT):
Has joined the channel.
kdenhartog (Thu, 31 Jan 2019 17:02:32 GMT):
Has joined the channel.
pknowles (Thu, 31 Jan 2019 19:04:20 GMT):
An updated version of the *Overlays Data Capture Architecture* deck has been uploaded to the following HL Indy shared area. Feel free to touch base on this channel to discuss. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Thu, 31 Jan 2019 19:04:20 GMT):
An updated version of the *Overlays data capture architecture* deck has been uploaded to the following HL Indy shared area. Feel free to touch base on this channel to discuss contents of the document. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Thu, 31 Jan 2019 19:04:20 GMT):
An updated version of the *Overlays data capture architecture* deck has been uploaded to the following HL Indy shared area. Feel free to touch base on this channel to discuss any contents of the document. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Thu, 31 Jan 2019 19:04:20 GMT):
An updated version of the *Overlays data capture architecture* deck has been uploaded to the following HL Indy shared area. Feel free to touch base on this channel to discuss contents of the document. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Thu, 31 Jan 2019 19:04:20 GMT):
An updated version of the *Overlays data capture architecture* deck has been uploaded to the following HL Indy shared area. Feel free to touch base on this channel to discuss document contents. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Thu, 31 Jan 2019 19:04:20 GMT):
An updated version of the *Overlays data capture architecture* deck has been uploaded to the following HL Indy shared area. Feel free to touch base on this channel to discuss it's contents. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Tue, 05 Feb 2019 04:47:59 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 5th February, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Latest _Verifiable Credentials_ presentation ( @brentzundel / @kenebert ) - 15 mins
- Reference - https://drive.google.com/drive/u/0/folders/1WDIP8t829XhBX2hq-9xBN8u2IG5k5TCO
• How multi-layered schema constructs can enhance interoperability of Credential Definitions and ZKP requirements (Open) - 45 mins
- Reference - https://drive.google.com/drive/u/0/folders/1Y4-YOVJW65qVg9NJZaiwBmuTEUNMY6pp
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 05 Feb 2019 04:47:59 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 5th February, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Latest _Verifiable Credentials Schemas_ presentation ( @brentzundel / @kenebert ) - 15 mins
- Reference - https://drive.google.com/drive/u/0/folders/1WDIP8t829XhBX2hq-9xBN8u2IG5k5TCO
• How multi-layered schema constructs can enhance interoperability of Credential Definitions and ZKP requirements (Open) - 45 mins
- Reference - https://drive.google.com/drive/u/0/folders/1Y4-YOVJW65qVg9NJZaiwBmuTEUNMY6pp
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 05 Feb 2019 17:52:01 GMT):
This week's *Indy Semantics WG* call starts in 1 hour. Zoom link: https://zoom.us/j/2157245727
pknowles (Tue, 05 Feb 2019 17:52:21 GMT):
This week's *Indy Semantics WG* call starts in 10 minutes. Zoom link: https://zoom.us/j/2157245727
pknowles (Tue, 05 Feb 2019 20:24:53 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, February 5th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 05 Feb 2019 20:25:06 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, February 19th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
jleders (Wed, 13 Feb 2019 05:34:25 GMT):
Has joined the channel.
xaviervila (Wed, 13 Feb 2019 09:42:54 GMT):
Has joined the channel.
dklesev (Thu, 14 Feb 2019 11:34:53 GMT):
Has joined the channel.
pknowles (Fri, 15 Feb 2019 15:59:22 GMT):
The next *Indy Semantics WG* call is this coming Tuesday, February 19th @ 11am-12.15pm MT / 7pm-8.15pm CET
If you're planning to join the call, there is a bit of homework/research to be done beforehand ...
Following a number of calls with the technical team at *digi.me*, they're keen to investigate the possibility of integrating some of their core functionality with Hyperledger Indy. I have an integration review call with their tech team later this month and a Blockchain interoperability feasibility study site meeting in early March. For those of you in the *MyData* space, you’ll know that this could be a potentially powerful collaboration of technologies and mindsets. I’m keen to help facilitate these discussions. For an initial soft integration, I propose to approach this from a semantics perspective and then, if deemed appropriate, to delve deeper into the stack on an _as needed_ basis.
For any Indy community members planning to dial into next week’s semantics call, check out the following two links beforehand to better understand digi.me's backend services ...
(i.) A four part series ending with how digi.me do consent - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
(ii.) A further drill down at developers.digi.me
During Tuesday night's semantics call, we’ll be discussing …
1. Taking a code fragment that would allow digi.me backend to support 3 primary functions …
* Init connection (with appropriate credentials)
* Write block of data representing a Consent Access Receipt (according to some base CAR schema, topic, identity model)
* Read a block of Clinical Trial data according to the base Schema + (chosen) Overlay
2. Discussion on lowering the bar for digi.me team to perform integration
* They seek a fast track to demo implementation to release funding
3. Share digi.me view of how multiple overlays work and how they could normalise to a master ontology to support N x N interoperability
* Concepts
* Toolchain example
4. Constructing a mini Hyperledger Indy development team for potential interwork including a public demo
Have a fabulous weekend!!!
pknowles (Fri, 15 Feb 2019 15:59:22 GMT):
@all The next *Indy Semantics WG* call is this coming Tuesday, February 19th @ 11am-12.15pm MT / 7pm-8.15pm CET
If you're planning to join the call, there is a bit of homework/research to be done beforehand ...
Following a number of calls with the technical team at *digi.me*, they're keen to investigate the possibility of integrating some of their core functionality with Hyperledger Indy. I have an integration review call with their tech team later this month and a Blockchain interoperability feasibility study site meeting in early March. For those of you in the *MyData* space, you’ll know that this could be a potentially powerful collaboration of technologies and mindsets. I’m keen to help facilitate these discussions. For an initial soft integration, I propose to approach this from a semantics perspective and then, if deemed appropriate, to delve deeper into the stack on an _as needed_ basis.
For any Indy community members planning to dial into next week’s semantics call, check out the following two links beforehand to better understand digi.me's backend services ...
(i.) A four part series ending with how digi.me do consent - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
(ii.) A further drill down at developers.digi.me
During Tuesday night's semantics call, we’ll be discussing …
1. Taking a code fragment that would allow digi.me backend to support 3 primary functions …
* Init connection (with appropriate credentials)
* Write block of data representing a Consent Access Receipt (according to some base CAR schema, topic, identity model)
* Read a block of Clinical Trial data according to the base Schema + (chosen) Overlay
2. Discussion on lowering the bar for digi.me team to perform integration
* They seek a fast track to demo implementation to release funding
3. Share digi.me view of how multiple overlays work and how they could normalise to a master ontology to support N x N interoperability
* Concepts
* Toolchain example
4. Constructing a mini Hyperledger Indy development team for potential interwork including a public demo
Have a fabulous weekend!!!
pknowles (Fri, 15 Feb 2019 15:59:22 GMT):
@all The next *Indy Semantics WG* call is this coming Tuesday, February 19th @ 11am-12.15pm MT / 7pm-8.15pm CET
If you're planning to join the call, there is a bit of homework/research to be done beforehand ...
Following a number of calls with the technical team at *digi.me*, they're keen to investigate the possibility of integrating some of their core functionality with Hyperledger Indy. I have an integration review call with their tech team later this month and a Blockchain interoperability feasibility study site meeting in early March. For those of you in the *MyData* space [https://mydata.org ], you’ll know that this could be a potentially powerful collaboration of technologies and mindsets. I’m keen to help facilitate these discussions. For an initial soft integration, I propose to approach this from a semantics perspective and then, if deemed appropriate, to delve deeper into the stack on an _as needed_ basis.
For any Indy community members planning to dial into next week’s semantics call, check out the following two links beforehand to better understand digi.me's backend services ...
(i.) A four part series ending with how digi.me do consent - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
(ii.) A further drill down at developers.digi.me
During Tuesday night's semantics call, we’ll be discussing …
1. Taking a code fragment that would allow digi.me backend to support 3 primary functions …
* Init connection (with appropriate credentials)
* Write block of data representing a Consent Access Receipt (according to some base CAR schema, topic, identity model)
* Read a block of Clinical Trial data according to the base Schema + (chosen) Overlay
2. Discussion on lowering the bar for digi.me team to perform integration
* They seek a fast track to demo implementation to release funding
3. Share digi.me view of how multiple overlays work and how they could normalise to a master ontology to support N x N interoperability
* Concepts
* Toolchain example
4. Constructing a mini Hyperledger Indy development team for potential interwork including a public demo
Have a fabulous weekend!!!
pknowles (Fri, 15 Feb 2019 15:59:22 GMT):
@all The next *Indy Semantics WG* call is this coming Tuesday, February 19th @ 11am-12.15pm MT / 7pm-8.15pm CET
If you're planning to join the call, there is a bit of homework/research to be done beforehand ...
Following a number of calls with the technical team at *digi.me*, they're keen to investigate the possibility of integrating some of their core functionality with Hyperledger Indy. I have an integration review call with their tech team later this month and a Blockchain interoperability feasibility study site meeting in early March. For those of you in the *MyData* space [https://mydata.org ], you’ll know that this could be a potentially powerful collaboration of technologies and minds. I’m keen to help facilitate these discussions. For an initial soft integration, I propose to approach this from a semantics perspective and then, if deemed appropriate, to delve deeper into the stack on an _as needed_ basis.
For any Indy community members planning to dial into next week’s semantics call, check out the following two links beforehand to better understand digi.me's backend services ...
(i.) A four part series ending with how digi.me do consent - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
(ii.) A further drill down at developers.digi.me
During Tuesday night's semantics call, we’ll be discussing …
1. Taking a code fragment that would allow digi.me backend to support 3 primary functions …
* Init connection (with appropriate credentials)
* Write block of data representing a Consent Access Receipt (according to some base CAR schema, topic, identity model)
* Read a block of Clinical Trial data according to the base Schema + (chosen) Overlay
2. Discussion on lowering the bar for digi.me team to perform integration
* They seek a fast track to demo implementation to release funding
3. Share digi.me view of how multiple overlays work and how they could normalise to a master ontology to support N x N interoperability
* Concepts
* Toolchain example
4. Constructing a mini Hyperledger Indy development team for potential interwork including a public demo
Have a fabulous weekend!!!
pknowles (Fri, 15 Feb 2019 15:59:22 GMT):
@all The next *Indy Semantics WG* call is this coming Tuesday, February 19th @ 11am-12.15pm MT / 7pm-8.15pm CET
If you're planning to join the call, there is a bit of homework/research to be done beforehand ...
Following a number of calls with the technical team at *digi.me*, they're keen to investigate the possibility of integrating some of their core functionality with Hyperledger Indy. I have an integration review call with their tech team later this month and a Blockchain interoperability feasibility study site meeting in early March. For those of you in the *MyData* space [https://mydata.org ], you’ll know that this could be a potentially powerful collaboration of technologies and minds. I’m keen to help facilitate these discussions. For an initial soft integration, I propose to approach this from a semantics perspective and then, if deemed appropriate, to delve deeper into the stack on an _as needed_ basis.
For any Indy community members planning to dial into next week’s semantics call, check out the following two links beforehand to better understand digi.me's backend services ...
(i.) A four part series ending with how digi.me do consent - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
(ii.) A further drill down at developers.digi.me
During the call, we’ll be discussing …
1. Taking a code fragment that would allow digi.me backend to support 3 primary functions …
* Init connection (with appropriate credentials)
* Write block of data representing a Consent Access Receipt (according to some base CAR schema, topic, identity model)
* Read a block of Clinical Trial data according to the base Schema + (chosen) Overlay
2. Discussion on lowering the bar for digi.me team to perform integration
* They seek a fast track to demo implementation to release funding
3. Share digi.me view of how multiple overlays work and how they could normalise to a master ontology to support N x N interoperability
* Concepts
* Toolchain example
4. Constructing a mini Hyperledger Indy development team for potential interwork including a public demo
Have a fabulous weekend!!!
pknowles (Fri, 15 Feb 2019 15:59:22 GMT):
@all The next *Indy Semantics WG* call is this coming Tuesday, February 19th @ 11am-12.15pm MT / 7pm-8.15pm CET
If you're planning to join the call, there is a bit of homework/research to be done beforehand ...
Following a number of calls with the technical team at *digi.me*, they're keen to investigate the possibility of integrating some of their core functionality with Hyperledger Indy. I have an integration review call with their tech team later this month and a Blockchain interoperability feasibility study site meeting in early March. For those of you in the *MyData* space [https://mydata.org ], you’ll know that this could be a potentially powerful collaboration of technologies and minds. I’m keen to help facilitate these discussions. For an initial soft integration, I propose to approach this from a semantics perspective and then, if deemed appropriate, to delve deeper into the stack on an _as needed_ basis.
For any Indy community members planning to dial into next week’s semantics call, check out the following two links beforehand to better understand digi.me's backend services ...
(i.) A four part series ending with how digi.me do consent - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
(ii.) A further drill down at developers.digi.me
During the call, we’ll be discussing …
1. Taking a code fragment that would allow digi.me backend to support 3 primary functions …
* Init connection (with appropriate credentials)
* Write block of data representing a Consent Access Receipt (according to some base CAR schema, topic, identity model)
* Read a block of Clinical Trial data according to the base Schema + (chosen) Overlay
2. Discussion on lowering the bar for digi.me team to perform integration
* They seek a fast track to demo implementation to release funding
3. Share digi.me view of how multiple overlays work and how they could normalise to a master ontology to support N x N interoperability
* Concepts
* Toolchain example
4. Constructing a mini Hyperledger Indy development team for potential interwork including a public demo
Happy reading. Have a fabulous weekend!!!
pknowles (Fri, 15 Feb 2019 16:39:13 GMT):
@kdenhartog @swcurran @danielhardman @mtfk @janl @tom_weiss @nage @drummondreed @kenebert @brentzundel ^^^
nage (Mon, 18 Feb 2019 18:08:30 GMT):
@pknowles we will have some attendance difficulties, with so many folks participating in the connect-a-thon
nage (Mon, 18 Feb 2019 18:09:01 GMT):
I look forward to seeing what the group discovers
aronvanammers (Mon, 18 Feb 2019 21:06:47 GMT):
Has joined the channel.
pknowles (Tue, 19 Feb 2019 16:49:23 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 19th February, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• How multi-layered schema constructs can enhance interoperability of Credential Definitions and ZKP requirements ( @mtfk ) - 20 mins
- Reference - https://drive.google.com/drive/u/0/folders/1Y4-YOVJW65qVg9NJZaiwBmuTEUNMY6pp
• Investigating the possibility of integrating some of digi.me's core functionality with Hyperledger Indy ( @pknowles ) - 30 mins
- Reference - https://www.youtube.com/playlist?list=PLsg6XlZAq3AJVp_439UzcMkg7Pdakzw-9
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 19 Feb 2019 17:33:08 GMT):
This week's *Indy Semantics WG* call starts in 30 minutes. Zoom link: https://zoom.us/j/2157245727
pknowles (Tue, 19 Feb 2019 23:41:51 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. I've scheduled in an ad hoc *Indy Semantics WG* call for next Tuesday, February 26th so that we can slot in a missed agenda item: _How multi-layered schema constructs can enhance interoperability of Credential Definitions and ZKP requirements_ ( @mtfk ). https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
runiner (Fri, 22 Feb 2019 17:37:28 GMT):
Has joined the channel.
pknowles (Sun, 24 Feb 2019 10:33:26 GMT):
In order to receive *Indy Semantics WG calendar invites*, make sure you've added your contact details to the following distribution list. https://docs.google.com/document/d/1NL36ZIksk4DmquRNvxpyZugWyjqCYa6n20FMzUnf-fY/edit?usp=sharing
pknowles (Tue, 26 Feb 2019 17:30:00 GMT):
This week's ad hoc *Indy Semantics WG* call starts in 30 minutes. Zoom link: https://zoom.us/j/2157245727
mtfk (Tue, 26 Feb 2019 21:14:02 GMT):
Repo with tool which we are working on: https://github.com/THCLab/tool
Any contribution and feedback welcome. Open an issue directly on github if you have any concern/ideas or wishes. PR welcome :)
mwherman2000 (Tue, 26 Feb 2019 21:25:59 GMT):
Follow-up from this mornings Semantics WG call ....what do people think of this visualization... p.s. I had to guess where a few of the layers belong ...also did some rewording....
mwherman2000 (Tue, 26 Feb 2019 21:26:11 GMT):
Clipboard - February 26, 2019 2:26 PM
mwherman2000 (Tue, 26 Feb 2019 21:38:45 GMT):
Here's a linkable version: https://github.com/mwherman2000/indy-arm/blob/master/README.md#appendix-f---indy-overlays-architecture-reference-model-overlays-arm-
mwherman2000 (Tue, 26 Feb 2019 21:39:48 GMT):
The PowerPoint source can be found here: https://github.com/mwherman2000/indy-arm/tree/master/src
pknowles (Tue, 26 Feb 2019 22:06:24 GMT):
@mwherman2000 - I'll colour-coordinate the images in the latest *Overlays data capture architecture* deck to align with the Tech / App / Bus layers as defined. I envisage those images being used in various future HIPEs so it makes sense to get the colours to line up with the layers in the rest of your ARM work. Thanks, Michael.
mwherman2000 (Tue, 26 Feb 2019 22:08:01 GMT):
@pknowles Checkout some of the wording suggestions as well ...especially the smaller text on the right side of each card.
pknowles (Tue, 26 Feb 2019 22:10:57 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=ZxeYCPamJbHY3MhZu) @mwherman2000 I certainly will. There are a few tweaks to be made. I'll take a look with fresh eyes tomorrow morning. :sleeping:
mwherman2000 (Tue, 26 Feb 2019 22:12:35 GMT):
The order of the cards (from bottom to top) within each color range (architectural layer) is also important. The higher cards build or have a dependency on the ones below/
pknowles (Tue, 26 Feb 2019 22:25:06 GMT):
The agenda, video, notes, etc. from today's ad hoc *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be next Tuesday, March 5th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
mwherman2000 (Tue, 26 Feb 2019 23:55:05 GMT):
I documented the Principles I used to guide the creation of the Overlays ARM diagram: https://github.com/mwherman2000/indy-arm/blob/master/README.md#principles
pknowles (Wed, 27 Feb 2019 04:49:09 GMT):
@mwherman2000 - The following 7 overlays have been defined for "Issuer” use ...
*Source Overlay* => to point to an external source of predefined Schema attribute definitions (e.g. HL7 FHIR, Schema 2.0, etc.);
*Encode Overlay* => to define character encoding (e.g. UTF-8, ISO-8859-1, Windows-1251, Base58Check, etc.);
*Entry Overlay* => to add predefined field values to Schema attributes;
*Label Overlay* => to add labels to Schema attributes (incl. category labels);
*Format Overlay* => to add formats (incl. field lengths) to Schema attributes;
*Conditional Overlay* => to add simple conditional programming within a Schema;
*Subset Overlay* => to create a Schema subset
pknowles (Wed, 27 Feb 2019 04:51:54 GMT):
The only overlay defined for “Holder” use is ...
*Sensitive Overlay* => to enable a Holder to flag user-defined sensitive attributes
pknowles (Wed, 27 Feb 2019 04:54:52 GMT):
[Note that the _Sensitive Overlay_ is the only one not linked to a specific _Schema Base_ but rather to a _Data Vault_ within the Holder's personal device.]
pknowles (Wed, 27 Feb 2019 05:21:58 GMT):
@mwherman2000 - In @mtfk 's _Schema Base & Overlays_ tooling demo, a couple of redundant overlays made their way back in but they can be disregarded, namely the _Informational Overly_ and _Consent Overlay_
pknowles (Wed, 27 Feb 2019 05:21:58 GMT):
@mwherman2000 - In @mtfk 's _Schema Base & Overlays_ tooling demo, a couple of redundant overlays made their way back in but they can be disregarded, namely the _Informational Overly_ and _Consent Overlay_
pknowles (Wed, 27 Feb 2019 05:21:58 GMT):
@mwherman2000 - In @mtfk 's _Schema Base & Overlays_ tooling demo, a couple of redundant overlays made their way back in but they can be disregarded, namely the _Information Overly_ and _Consent Overlay_
pknowles (Wed, 27 Feb 2019 05:21:58 GMT):
@mwherman2000 - In @mtfk 's _Schema Base & Overlays_ tooling demo, a couple of redundant overlays made their way back in but they can be disregarded, namely the _Information Overlay_ and _Consent Overlay_
pknowles (Wed, 27 Feb 2019 05:21:58 GMT):
@mwherman2000 - In @mtfk 's _Schema Base & Overlays_ tooling demo, a couple of redundant overlays made their way back into the fray but they can be disregarded, namely the _Information Overlay_ and _Consent Overlay_
pknowles (Wed, 27 Feb 2019 05:21:58 GMT):
@mwherman2000 - In @mtfk 's _Schema Base & Overlays_ tooling demo, a couple of redundant overlays made their way back into the fray but they can be disregarded, namely the _Information Overlay_ and the _Consent Overlay_
pknowles (Wed, 27 Feb 2019 05:23:21 GMT):
@mtfk - Can you double-check the written definition of the _Source Overlay_ , I'm not sure if that is the correct purpose. If I've got that wrong, please suggest a new definition.
pknowles (Wed, 27 Feb 2019 05:23:21 GMT):
@mtfk - Can you double-check the written definition of the _Source Overlay_ ? I'm not sure if that is the correct purpose. If I've got that wrong, please suggest a new definition.
pknowles (Wed, 27 Feb 2019 05:23:21 GMT):
@mtfk - Can you double-check the written definition of the *Source Overlay* ? I'm not sure if that is the correct purpose. If I've got that wrong, please suggest a new definition.
mtfk (Wed, 27 Feb 2019 06:22:39 GMT):
While building the tool didn't thought much about semantics yet just copy pasted what had around but as soo as from feature point of view will have correct flow we can review one by one and kick out those which are ot needed.
pknowles (Wed, 27 Feb 2019 07:21:09 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=a08a324e-8d4a-4611-89be-aed60a0b7dc9) @mtfk I think we've done that already.
pknowles (Wed, 27 Feb 2019 08:17:13 GMT):
@mwherman2000 @mtfk - Looking at the Overlays ARM schematic, we may be able to remove the Business Layer from the card stack. Perhaps a description of the flow might shed some light on my thinking here. As I see it, the process of using Robert's middleware tool from an Ïssuer's point of view would go something like ...
(i.) According to the GICS / NECS ontologies [ https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV ], the Issuer would tag the current Schema building process with the lowest level GICS and/or NECS industry codes. These tags can be used for searchability purposes further downstream.;
(ii.) The Issuer then builds a plethora of pre-publish schema(s) incl. _Technology Layer_ and _Application Layer_ overlays.;
(iii.) The Issuer then hits a "Publish" button but, before the schemas are published, the build process for the _Business_ schemas (i.e. consent-related schemas) is triggered. The Schema build process for these Business schemas will allow the same level of overlay flexibility but I envisage the Schema Bases to already be locked in courtesy of an Issuer such as Kantara Initiative. The 3 consent-related schema constructs that we are/will be working on are a *PDP* (Personal Data Processing) schema, a *Generic Consent* schema and a *Specialized Consent* schema. Elements from each of these 3 constructs will ultimately be used to populate a standardized Consent Receipt (Kantara Initiative). Once the Issuer has defined these consent-related constructs, the entire suite of completed Schemas (i.e. the "plethora of pre-publish schema(s)" mentioned in point (i.)) can be published.
More information on the _PDP schema_ ... https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
These _Business Layer_ constructs would basically act as a wrapper encompassing the suite of Schemas to be published. Think of these constructs as containing metadata to define consent for all schemas contained in a .ZIP file.
mwherman2000 (Wed, 27 Feb 2019 13:46:34 GMT):
RE: Format Overlay* => to add formats (incl. field lengths) to Schema attributes;
Is this purpose of this overlay to:
a. control presentation the values of an attribute in the user experience? (Application layer)
b. storage/persistence of the values of an attribute? (Technology layer)
These are (usually) different.
mwherman2000 (Wed, 27 Feb 2019 13:51:33 GMT):
@pknowles RE: Perhaps a description of the flow might shed some light on my thinking here. As I see it, the process of using Robert's middleware tool from an Ïssuer's point of view would go something like ...
We need to separate the "how" from the "what". The process you described is the "how" but the card stack diagram is intended to be a description of the "what" ...the architecture of the Overlay card stack. There is an interplay between the two but they are different.
mwherman2000 (Wed, 27 Feb 2019 13:51:33 GMT):
@pknowles RE: Perhaps a description of the flow might shed some light on my thinking here. As I see it, the process of using Robert's middleware tool from an Ïssuer's point of view would go something like ...
We need to separate the "how" from the "what". The process you described is the "how" but the card stack diagram is intended to be a description of the "what" ...the architecture of the Overlays card stack. There is an interplay between the two but they are different.s
mwherman2000 (Wed, 27 Feb 2019 13:54:18 GMT):
@pknowles RE: These _Business Layer_ constructs would basically act as a wrapper encompassing the suite of Schemas to be published. Think of these constructs as containing metadata to define consent for all schemas contained in a .ZIP file.
This is consistent with the card stack model - the Application Layer is supposed to support needs of the Business layer. ...or alternatively, the business layer is an overarching concept for what appears in the Application and Technology layers.
mwherman2000 (Wed, 27 Feb 2019 14:21:34 GMT):
Here's a cleanup up v0.2: https://github.com/mwherman2000/indy-arm/blob/master/README.md#appendix-f---indy-overlays-architecture-reference-model-overlays-arm-
mwherman2000 (Wed, 27 Feb 2019 14:21:34 GMT):
Here's a cleaned up v0.2: https://github.com/mwherman2000/indy-arm/blob/master/README.md#appendix-f---indy-overlays-architecture-reference-model-overlays-arm-
pknowles (Wed, 27 Feb 2019 18:40:05 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=egRnmhThtwEbX3Crz) @mwherman2000 That definitely looks better. I'm still waiting to hear back from @mtfk re the correct definition for the *Source Transfer*. The only other tiny tweak is "Schema Base" rather than "Base Schema".
pknowles (Wed, 27 Feb 2019 18:40:05 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=egRnmhThtwEbX3Crz) @mwherman2000 That definitely looks better. I'm still waiting to hear back from @mtfk re the correct definition for *Source Overlay*. The only other tiny tweak is "Schema Base" rather than "Base Schema".
pknowles (Wed, 27 Feb 2019 18:40:05 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=egRnmhThtwEbX3Crz) @mwherman2000 That definitely looks better. I'm still waiting to hear back from @mtfk re correct definition of *Source Overlay*. The only other tiny tweak is "Schema Base" rather than "Base Schema".
pknowles (Wed, 27 Feb 2019 18:48:16 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=7YMrHCi3dZRDBtkAD) @mwherman2000 Application layer ... is the correct one.
mwherman2000 (Wed, 27 Feb 2019 19:04:37 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=dzBXf8ARhfjvMohJ3) @pknowles Fixed
pknowles (Tue, 05 Mar 2019 17:40:18 GMT):
This week's *Indy Semantics WG* call starts in 20 minutes. Zoom link: https://zoom.us/j/2157245727
pknowles (Tue, 05 Mar 2019 17:48:08 GMT):
Here is the agenda and dial-in information for the *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 5th March, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Including issuer-specified personal data processing and consent information to a schema set prior to publishing ( @pknowles / @mtfk / @janl ) - 45 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 05 Mar 2019 17:48:08 GMT):
Here is the agenda and dial-in information for the *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 5th March, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Including issuer-specified personal data processing and consent information to a schema set prior to publishing ( @pknowles / @mtfk ) - 45 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 05 Mar 2019 17:48:08 GMT):
Here is the agenda and dial-in information for the *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 5th March, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Including issuer-specified personal data processing and consent information to a schema set prior to publishing - 45 mins
- Reference - https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 05 Mar 2019 20:07:32 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, March 19th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I believe that Pharma will get behind it. HL Indy rides in on the coattails too. An added bonus!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I have great confidence that Pharma will get behind it. HL Indy rides in on the coattails too. An added bonus!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I have great confidence that Pharma will get behind it. HL Indy rides in on the coattails of course!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have great confidence that we'll get Pharma buy-in. HL Indy rides in on the coattails of course!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have great confidence re Pharma buy-in. HL Indy rides in on the coattails of course!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have great confidence that Pharma will adopt. HL Indy rides in on the coattails of course!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy is a strong part of the pitch!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy surfs the 🌊!
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy surfs the 🌊
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy is carried on that 🌊
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy obviously be carried on that 🌊
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The Overlays data capture architecture is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy will obviously be carried on that 🌊
pknowles (Thu, 07 Mar 2019 17:19:37 GMT):
The *Overlays data capture architecture* is making great headway within both Roche and Novartis. I'll give a brief update during the next Semantics WG call but I now have a strong inkling that Pharma will adopt. HL Indy will obviously be carried on that 🌊
pknowles (Sun, 17 Mar 2019 19:26:17 GMT):
Published article on the *Overlays data capture architecture* - https://www.dativa.com/introducing-overlays-data-capture-architecture/
pknowles (Mon, 18 Mar 2019 21:17:30 GMT):
Image-5.png
pknowles (Mon, 18 Mar 2019 21:17:48 GMT):
Image-6.png
pknowles (Mon, 18 Mar 2019 21:24:10 GMT):
Image-5.png
pknowles (Mon, 18 Mar 2019 21:24:22 GMT):
Image-6.png
pknowles (Tue, 19 Mar 2019 06:29:53 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 19th March, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
5pm-6.15pm GMT *
6pm-7.15pm CET *
* Note: Due to clock changes, the call time remains the same for US participants but is an hour earlier than usual for European participants!
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Agent Framework for .NET - Web and Mobile demo ( @tomislav ) - 20 mins
- Reference - https://agent-framework.readthedocs.io/en/latest/index.html
• Learnings from Helsinki: Sitra's IHAN Technical Workshop on Consent ( @mtfk / @janl ) - 10 mins
- Reference - https://www.sitra.fi/en/events/consent-management-workshop/
• Consent Management assigned to a Schema Family incl. ODCA middleware demo ( @mtfk ) - 20 mins
- Reference - https://github.com/THCLab/tool
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
tomislav (Tue, 19 Mar 2019 06:30:01 GMT):
Has joined the channel.
pieterp (Tue, 19 Mar 2019 08:49:47 GMT):
Has joined the channel.
pknowles (Tue, 19 Mar 2019 19:36:38 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, March 19th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 19 Mar 2019 19:37:12 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 2nd. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
mwherman2000 (Tue, 19 Mar 2019 22:09:07 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=nGb4hMpMaTR69DPLD) @pknowles Paul, what's the difference between the 2 video files? ...just the format? ...are they both video files?
pknowles (Wed, 20 Mar 2019 00:41:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=yMLWjj24N3P7bG2jf) @mwherman2000 The .mp4 file is a video file. The .m4a file is an audio file. Zoom provides both formats by default.
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @jan With the *Rich Schema* efforts gaining some focus now, I believe that it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that a few minor additions to the tool will also enable credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for people less technically minded and new to the community and I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe that it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that a few minor additions to the tool will also enable credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for people less technically minded and new to the community and I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe that it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that, with a few minor additions to the tool, we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for people less technically minded and new to the community and I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe that it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that, with a few minor additions to the tool, we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for people new to the community and less technically minded and, as such, strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe that it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for people new to the community and less technically minded and, as such, strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for people new to the community and less technically minded and, as such, strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for those new to the community or less technically minded and, as such, I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for those new to the community or less technically minded and, as such, I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? Note: _ODCA = Overlays data capture architecture_ [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for those new to the community or less technically minded and, as such, I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? Note: _ODCA = Overlays data capture architecture_ [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for those new to the community or less technically minded and, as such, I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. Robert can you suggest a good time for a closed demo/discussion with Ken and Brent so that we can ensure that everyone is pulling in the same direction? Perhaps next Tuesday at 11am MT on the usual Zoom link. Note: _ODCA = Overlays data capture architecture_ [Cc: @nage ]
pknowles (Thu, 21 Mar 2019 05:52:32 GMT):
@mtfk @brentzundel @kenebert @janl With the *Rich Schema* efforts gaining some focus now, I believe it'll be hugely valuable for Ken and Brent to see the _under-the-hood_ code being dynamically constructed by the *ODCA middleware tool*. Although Robert and I have been concentrating on the initial schema creation process up until this point, it's fairly obvious to me that with a few minor additions to the tool we'll also be able to handle credential schema issuance. Some of the HL Indy stack processes will be difficult to digest for those new to the community or less technically minded and, as such, I strongly believe that we can create this great piece of middleware tooling to help organisations and individuals better adopt. The ODCA tool will always be open source, free to use and without IP. May I suggest that we all hop on a Zoom call next Tuesday at 11am MT for a closed demo/discussion to ensure that everyone is pulling in the same direction? I'll send out the calendar invite. Note: _ODCA = Overlays data capture architecture_ [Cc: @nage ]
pknowles (Fri, 22 Mar 2019 11:17:07 GMT):
The _Global Access_ team at *Roche Diagnostics* will be putting together a use case proposal and white paper for the implementation of the *Overlays data capture architecture* which will then be pitched to all global function heads this summer. https://diagnostics.roche.com/global/en/article-listing/global-access-program.html
pknowles (Fri, 22 Mar 2019 11:17:07 GMT):
Newsflash: The _Global Access_ team at *Roche Diagnostics* will be putting together a use case proposal and white paper for the implementation of the *Overlays data capture architecture* which will then be pitched to all global function heads this summer. https://diagnostics.roche.com/global/en/article-listing/global-access-program.html
pknowles (Fri, 22 Mar 2019 11:17:07 GMT):
Newsflash: The _Global Access_ team at *Roche Diagnostics* will be putting together a use case proposal and white paper for the implementation of the *Overlays data capture architecture* which will then be pitched to all global function heads this summer. https://diagnostics.roche.com/global/en/article-listing/global-access-program.html
pknowles (Fri, 22 Mar 2019 11:17:07 GMT):
The _Global Access_ team at *Roche Diagnostics* will be putting together a use case proposal and white paper for the implementation of the *Overlays data capture architecture* which will then be pitched to all global function heads this summer. https://diagnostics.roche.com/global/en/article-listing/global-access-program.html
phoniks (Fri, 22 Mar 2019 19:51:21 GMT):
Has joined the channel.
phoniks (Fri, 22 Mar 2019 22:39:44 GMT):
@pknowles: I'm a fellow at the Insight Decentralized Consensus program here in San Francisco. I caught the SSI bug last year at IIW and even though I was new to the concept of DIDs I caught your (or someone else's) session on Overlays. The idea behind the Insight program is that we spend ~4 weeks working on a project and then demo it to potential employers at the end of the program. I'm really interested in carving out SSI as my niche in this space, and it feels like overlays could be a really big deal, so I was hoping that you might be able to point me to some aspect of the problem that I might be able to contribute something to. What would be the first step towards implementing overlays on a different blockchain - like Ethereum for instance. Or, following from your March 20th post, is there some way that I could help create some high level tools to make ODCA accessible to the less technically minded?
kenebert (Fri, 22 Mar 2019 22:41:11 GMT):
@pknowles I think such a review would be useful. Please arrange a meeting.
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is platform agnostic. In this new user-centric data economy that we are all striving to build, the OCDA architecture encourages both interoperability and reusability of data objects [_schema bases_ (base objects) and _overlays_] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope I can persuade you to work on in collaboration with us with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . Further reading: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [_schema bases_ (base objects) and _overlays_] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope I can persuade you to work on in collaboration with us with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . Further reading: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is indeed platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [_schema bases_ (base objects) and _overlays_] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope I can persuade you to work on in collaboration with us with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . Further reading: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is indeed platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope I can persuade you to work on in collaboration with us with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . Further reading: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is indeed platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope I can persuade you to work on in collaboration with us with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . Further reading: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is indeed platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . Further reading: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is indeed platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tags, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . ODCA blog post: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely affiliated to _Hyperledger Indy_, the architecture is indeed platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tagging, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . ODCA blog post: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely aligned to _Hyperledger Indy_, the architecture is actually platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tagging, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . ODCA blog post: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely aligned to _Hyperledger Indy_, the architecture is actually platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tagging, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . ODCA blog post: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk @kenebert ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely aligned with _Hyperledger Indy_, the tool is platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tagging, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to potential employers. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . ODCA blog post: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk @kenebert ]
pknowles (Sat, 23 Mar 2019 01:28:56 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=usxsDbDbT9ZiLfn7C) @phoniks Thanks for reaching out. Although the initial implementation for the *ODCA middleware tool* is closely aligned with _Hyperledger Indy_, the tool is platform agnostic. In this new user-centric data economy that we are all striving to build, the architecture encourages both interoperability and reusability of data objects [ _schema bases_ (base objects) and _overlays_ ] in an open economy. As all overlays contain their own ID, a link ID to a base object and industry sector tagging, they become searchable either in a repository or on a ledger. By tracking the number of times that the data objects are being utilised, the community of schema issuers effectively drive standardisation. We've started building the ODCA middleware tool in Dativa's innovation hub [https://www.dativa.com/innovation-hub/ ]. This is ultimately the project tool that I hope we can work on in collaboration with a view to demoing it to organisations. The code is totally open source. Nobody has any IP on it. Github repository - https://github.com/THCLab/tool . ODCA blog post: https://www.dativa.com/introducing-overlays-data-capture-architecture/ . Let's continue this discussion on a Zoom call. I'll set that up with you directly. [Cc: @mtfk @kenebert ]
pknowles (Sat, 23 Mar 2019 01:57:12 GMT):
The _Global Access_ team at *Roche Diagnostics* will be putting together a use case proposal and white paper for the implementation of the *Overlays data capture architecture* which will then be pitched to all global function heads this summer. https://diagnostics.roche.com/global/en/article-listing/global-access-program.html
pknowles (Sat, 23 Mar 2019 01:57:12 GMT):
The _Global Access_ team at *Roche Diagnostics* will be putting together a use case proposal and white paper for the implementation of the *Overlays data capture architecture* and middleware tooling which will then be pitched to all global function heads this summer. https://diagnostics.roche.com/global/en/article-listing/global-access-program.html
pyraman (Mon, 25 Mar 2019 09:41:37 GMT):
Has joined the channel.
pyraman (Mon, 25 Mar 2019 09:44:52 GMT):
hi all! After 4 months study Hyperledger Fabric - now we win a project require Indy :).
Stick with Indy today I found some awesome tools to make a testnet.
My question is! Does Indy offer a public network and smart contract engine so that I can deploy smart contract to the network and call API from client?
pknowles (Mon, 25 Mar 2019 12:36:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=TLQJGmrFRHw5WTe8T) @pyraman Repost your query to the #indy channel for a quicker response.
brentzundel (Mon, 25 Mar 2019 23:15:49 GMT):
looks like I've somehow ended up with two semantics group meetings tomorrow. Could anyone tell me which one is right?
Ryan2 (Tue, 26 Mar 2019 04:49:24 GMT):
Has joined the channel.
pknowles (Tue, 02 Apr 2019 05:45:56 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 2nd April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• 2019 Q1 DID Specifications Update ( @mwherman2000 ) - 10-15 mins
- Reference - https://w3c-ccg.github.io/did-wg-charter/
• 2019 Q1 Schema 2.0 Update ( @brentzundel / @kenebert ) - 10-15 mins
- Reference - https://github.com/WebOfTrustInfo/rwot8-barcelona/blob/master/topics-and-advance-readings/Using-Immutable-Data-Objects.md
• 2019 Q1 ODCA Pipeline Update ( @pknowles / @mtfk ) - 10-15 mins
- Reference - https://github.com/THCLab/tool
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 02 Apr 2019 05:45:56 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 2nd April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• 2019 Q1 DID Specifications Update ( @mwherman2000 ) - 10-15 mins
- Reference - https://w3c-ccg.github.io/did-wg-charter/
• 2019 Q1 Schema 2.0 Update ( @brentzundel / @kenebert ) - 10-15 mins
- Reference - https://github.com/WebOfTrustInfo/rwot8-barcelona/blob/master/topics-and-advance-readings/Using-Immutable-Data-Objects.md
• 2019 Q1 ODCA Pipeline Update ( @pknowles / @mtfk ) - 10-15 mins
- Reference - https://www.dativa.com/innovation-hub/
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 02 Apr 2019 18:57:03 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 16th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 03 Apr 2019 06:58:33 GMT):
@mwherman2000 has kindly put together a blog article detailing the *2019 Q1 DID Specifications Update* as presented during yesterday's *Indy Semantics WG* call. Thanks, Michael! https://hyperonomy.com/2019/04/03/2019-q1-update-did-specifications-efforts/
mwherman2000 (Wed, 03 Apr 2019 09:59:04 GMT):
Thank you to @kenebert for his helping spotting a couple errors in the grammar as well as a lot of general good advice.
mwherman2000 (Wed, 03 Apr 2019 09:59:04 GMT):
Thank you to @kenebert for his helping spotting a couple errors in the grammar examples as well as a lot of general good advice.
pknowles (Thu, 04 Apr 2019 04:14:06 GMT):
I have a clash with today's *Indy WG* call so won't be able to dial in. If @Sean_Bohan asks for a quick summary about the workings of the *Indy Semantics WG*, would perhaps @mwherman2000 or @kenebert be able to step up to the mic?
pknowles (Thu, 04 Apr 2019 04:14:06 GMT):
I have a clash with today's *Indy WG* call so won't be able to attend. If @Sean_Bohan asks for a quick summary about the workings of the *Indy Semantics WG*, would perhaps @mwherman2000 or @kenebert be able to step in?
pknowles (Thu, 04 Apr 2019 04:14:06 GMT):
I have a clash with today's *Indy WG* call so won't be able to dial in. If @Sean_Bohan asks for a quick summary about the workings of the *Indy Semantics WG*, would perhaps @mwherman2000 or @kenebert be able to step in?
pknowles (Fri, 05 Apr 2019 06:33:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=726PzsMZMqEHgSzn2) @mtfk Michael's blog article may help shed some light on proposed syntax for semantics pointers/identifiers.
pknowles (Fri, 05 Apr 2019 06:33:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=726PzsMZMqEHgSzn2) @mtfk Michael's blog article may help shed some light on proposed syntax for semantics pointers/identifiers. "Figure 1. DID Specifications Ecosystem" will be of particular interest.
pknowles (Fri, 05 Apr 2019 06:33:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=726PzsMZMqEHgSzn2) @mtfk Michael's blog article may help shed some light on proposed syntax for semantics pointers/identifiers. "_Figure 1. DID Specifications Ecosystem_" will be of particular interest.
pknowles (Fri, 05 Apr 2019 06:33:04 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=726PzsMZMqEHgSzn2) @mtfk Michael's blog article may help shed some light on proposed syntax for semantics pointers/identifiers. _Figure 1. DID Specifications Ecosystem_ will be of particular interest.
pknowles (Sun, 07 Apr 2019 06:32:40 GMT):
From @drummondreed : Paul, on this whole subject of addressing immutable content objects (like schema definitions) with DIDs, see the current state-of-play about how this will be done in the DID spec in these two Google docs. The first one describes the matrix parameters proposal: https://docs.google.com/document/d/1TctFY8euBH2wq7Z8c9KccICDZUGZplvhoqlHlFMahGk/edit?usp=sharing
The second one is for contributors to write up their own use cases for DID URLs in the 3 syntaxes under consideration. Should only take any W3C Credentials Community Group member 5 mins to write up your own examples: https://docs.google.com/document/d/1VpYPvUw2o-01e727bCy2V-0MUEe0_NB-EqX677scQbI/edit?usp=sharing
pknowles (Sun, 07 Apr 2019 06:32:40 GMT):
From @drummondreed : "Paul, on this whole subject of addressing immutable content objects (like schema definitions) with DIDs, see the current state-of-play about how this will be done in the DID spec in these two Google docs. The first one describes the matrix parameters proposal: https://docs.google.com/document/d/1TctFY8euBH2wq7Z8c9KccICDZUGZplvhoqlHlFMahGk/edit?usp=sharing "
The second one is for contributors to write up their own use cases for DID URLs in the 3 syntaxes under consideration. Should only take any W3C Credentials Community Group member 5 mins to write up your own examples: https://docs.google.com/document/d/1VpYPvUw2o-01e727bCy2V-0MUEe0_NB-EqX677scQbI/edit?usp=sharing
pknowles (Sun, 07 Apr 2019 06:32:40 GMT):
From @drummondreed : "Paul, on this whole subject of addressing immutable content objects (like schema definitions) with DIDs, see the current state-of-play about how this will be done in the DID spec in these two Google docs. The first one describes the matrix parameters proposal: https://docs.google.com/document/d/1TctFY8euBH2wq7Z8c9KccICDZUGZplvhoqlHlFMahGk/edit?usp=sharing
The second one is for contributors to write up their own use cases for DID URLs in the 3 syntaxes under consideration. Should only take any W3C Credentials Community Group member 5 mins to write up your own examples: https://docs.google.com/document/d/1VpYPvUw2o-01e727bCy2V-0MUEe0_NB-EqX677scQbI/edit?usp=sharing "
pknowles (Sun, 07 Apr 2019 06:34:38 GMT):
I'll add this as an agenda item for the next #indy-semantics WG call.
pknowles (Sun, 07 Apr 2019 06:34:38 GMT):
I'll add this as an agenda item for the next *Indy Semantics WG* call on April 16th.
drummondreed (Sun, 07 Apr 2019 19:24:28 GMT):
Paul, what time is the call on the 16th? I'll try to attend.
pknowles (Sun, 07 Apr 2019 20:38:48 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=rRPTWhYPZHnRNdGwn) @drummondreed 10am-11.15am PT
drummondreed (Sun, 07 Apr 2019 20:43:36 GMT):
Excellent—on the calendar now.
hamidm (Wed, 10 Apr 2019 11:20:04 GMT):
Has joined the channel.
mwherman2000 (Sat, 13 Apr 2019 14:58:33 GMT):
A bit off topic but does anyone have a schema definition for a DID Document? ...that is, a meta description/definition outlining the overall structure of a DID Document, the mandatory elements, provisions for optional elements, ...that sort of thing.Effectively, the spec text for a DID Document from the DID Spec (https://w3c-ccg.github.io/did-spec/#did-documents) expressing in some sort of schema definition language (e.g. JSON schema?)
mwherman2000 (Sat, 13 Apr 2019 14:58:33 GMT):
A bit off topic but does anyone have a schema definition for a DID Document? ...that is, a meta description/definition outlining the overall structure of a DID Document, the mandatory elements, provisions for optional elements, ...that sort of thing. Effectively, the spec text for a DID Document from the DID Spec (https://w3c-ccg.github.io/did-spec/#did-documents) expressing in some sort of schema definition language (e.g. JSON schema?)
mwherman2000 (Sat, 13 Apr 2019 14:58:33 GMT):
A bit off topic but does anyone have a schema definition for a DID Document? ...that is, a meta description/definition outlining the overall structure of a DID Document, the mandatory elements, provisions for optional elements, ...that sort of thing. Effectively, the spec text for a DID Document from the DID Spec (https://w3c-ccg.github.io/did-spec/#did-documents) expressed in some sort of schema definition language (e.g. JSON schema?)
mtfk (Mon, 15 Apr 2019 20:01:41 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=QNNfch4PA3ZEkrjJH) @mwherman2000 https://w3c-ccg.github.io/did-spec/contexts/did-v1.jsonld
like this?
pknowles (Tue, 16 Apr 2019 16:12:12 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 16th April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Decentralized Resource Identifier (DRI) - What is it and why do we need it? ( @mtfk ) - 40 mins
- Reference - https://docs.google.com/document/d/1VpYPvUw2o-01e727bCy2V-0MUEe0_NB-EqX677scQbI/edit#heading=h.lmn1hanjyyns
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 16 Apr 2019 16:12:12 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 16th April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Decentralized Resource Identifier (DRI) - What is it and why do we need it? ( @mtfk ) - 40 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 16 Apr 2019 16:30:24 GMT):
@peacekeeper @mwherman2000 @drummondreed @danielhardman :top:
mwherman2000 (Tue, 16 Apr 2019 16:39:37 GMT):
@pknowles I'm going to pass on this morning's call. I don't see the Hyperonomy Universal DID URI Specification (did-uri-spec) represented in any of the options listed in the Google doc. Let's arrange a specific Universal DID URI Specification (did-uri-spec) conversation for the next call.
helengarneau (Tue, 16 Apr 2019 16:52:54 GMT):
Has joined the channel.
mwherman2000 (Tue, 16 Apr 2019 16:53:32 GMT):
@mtfk I'm looking forward to your talk. The primary goal of the Hyperonomy Universal Decentralized Identifier URI Specification, its reason for being, is specifically to support every possible application of DIDs on the planet ...quite literally and demonstrably. A key feature is the concept of Domain-Specific DID Grammar (DSDG).
The overview webcast can be found here: https://www.youtube.com/watch?v=e3V5oRB5lYA&list=PLU-rWqHm5p45c9jFftlYcr4XIWcZb0yCv&index=2
mwherman2000 (Tue, 16 Apr 2019 16:53:32 GMT):
@mtfk I'm looking forward to your talk. The primary goal of the Hyperonomy *Universal *Decentralized Identifier URI Specification, its reason for being, is specifically to support every possible application of DIDs on the planet ...quite literally and demonstrably. A key feature is the concept of Domain-Specific DID Grammar (DSDG).
The overview webcast can be found here: https://www.youtube.com/watch?v=e3V5oRB5lYA&list=PLU-rWqHm5p45c9jFftlYcr4XIWcZb0yCv&index=2
mwherman2000 (Tue, 16 Apr 2019 16:53:32 GMT):
@mtfk I'm looking forward to your talk. The primary goal of the Hyperonomy *Universal *Decentralized Identifier URI Specification, its reason for being, is specifically to support every possible application of DIDs on the planet ...every possible application ...quite literally and demonstrably. A key feature is the concept of Domain-Specific DID Grammar (DSDG).
The overview webcast can be found here: https://www.youtube.com/watch?v=e3V5oRB5lYA&list=PLU-rWqHm5p45c9jFftlYcr4XIWcZb0yCv&index=2
mwherman2000 (Tue, 16 Apr 2019 16:54:33 GMT):
The DSDG webcast can be found here: https://www.youtube.com/watch?v=IdLm2jHuADg&list=PLU-rWqHm5p45c9jFftlYcr4XIWcZb0yCv&index=6&t=0s
brentzundel (Tue, 16 Apr 2019 17:56:04 GMT):
Please review the Rich Schema PR: https://github.com/hyperledger/indy-hipe/pull/119
drummondreed (Tue, 16 Apr 2019 18:07:45 GMT):
Here is the link to the Google doc that I showed on the call today that consolidates the DID spec syntax and matrix parameters proposal discussions into proposed text for the DID spec. Please do add comments/suggestions/questions so we can refine this into final proposed language that we will turn into a PR. https://mit.webex.com/mit/j.php?MTID=m4d2a5f07fd6efee504f1752a8a2a3965
drummondreed (Tue, 16 Apr 2019 18:07:45 GMT):
Here is the link to the Google doc that I showed on the call today that consolidates the DID spec syntax and matrix parameters proposal discussions into proposed text for the DID spec. Please do add comments/suggestions/questions so we can refine this into final proposed language that we will turn into a PR. https://docs.google.com/document/d/1qnDExIVjU5bYc601qUdLZIi9UAs1ojlHyKnVoz2zlLM/edit?usp=sharing
pknowles (Tue, 16 Apr 2019 18:43:07 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=bm9FjzMABGaAvqxig) @brentzundel @all - We are scheduling an ad-hoc *Indy Semantics WG* call next Tuesday, April 23rd at 11am-12.15pm MT (7pm-8.15pm CET) to discuss this important hipe. Please review and add your comments to the document before the call.
pknowles (Tue, 16 Apr 2019 18:43:07 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=bm9FjzMABGaAvqxig) @brentzundel @all - We are scheduling an ad-hoc *Indy Semantics WG* call next Tuesday, April 23rd at 11am-12.15pm MT (7pm-8.15pm CET) to discuss this important hipe. Please review and add your comments to the document before then.
pknowles (Tue, 16 Apr 2019 18:43:07 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=bm9FjzMABGaAvqxig) @brentzundel @all - We are scheduling an ad-hoc *Indy Semantics WG* call for next Tuesday, April 23rd at 11am-12.15pm MT (7pm-8.15pm CET) to discuss this important hipe. Please review and add your comments to the document before then.
pknowles (Tue, 16 Apr 2019 18:43:07 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=bm9FjzMABGaAvqxig) @brentzundel @all - We are scheduling an ad-hoc *Indy Semantics WG* call for next Tuesday, April 23rd at 11am-12.15pm MT (7pm-8.15pm CET) to discuss this important HIPE. Please review and add your comments to the document before then.
drummondreed (Tue, 16 Apr 2019 19:03:43 GMT):
Note that I posted the wrong link to the DID spec syntax and matrix parameters proposal in my last message above. I have fixed it. Again, the correct link is: https://docs.google.com/document/d/1qnDExIVjU5bYc601qUdLZIi9UAs1ojlHyKnVoz2zlLM/edit?usp=sharing
pknowles (Tue, 16 Apr 2019 19:04:34 GMT):
Noted. Thanks, @drummondreed
pknowles (Tue, 16 Apr 2019 20:02:36 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 23td. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 16 Apr 2019 20:02:36 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 23rd. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
rangak (Thu, 18 Apr 2019 23:09:34 GMT):
Has joined the channel.
pknowles (Mon, 22 Apr 2019 10:22:35 GMT):
There is an ad hoc *Indy Semantics WG* call tomorrow to discuss the new *Rich Schema* PR prior to the HIPE being submitted. Please review prior to the call. Anyone is welcome to join.
Rich Schema PR :
https://github.com/hyperledger/indy-hipe/pull/119
Meeting: Indy Semantics Working Group
Date: Tuesday, 23rd April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Review and discuss Rich Schema PR prior to HIPE submission ( @brentzundel ) - 45 mins
- Reference - https://github.com/hyperledger/indy-hipe/pull/119
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Mon, 22 Apr 2019 10:22:35 GMT):
There is an ad hoc *Indy Semantics WG* call tomorrow to discuss the new *Rich Schema* PR prior to the HIPE being submitted. Please review prior to the call. Anyone is welcome to join.
Rich Schema PR :
https://github.com/hyperledger/indy-hipe/blob/2c3a264963183237e5dfa962fbfd97c8d8da780f/text/rich-schemas/README.md
Meeting: Indy Semantics Working Group
Date: Tuesday, 23rd April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Review and discuss Rich Schema PR prior to HIPE submission ( @brentzundel ) - 45 mins
- Reference - https://github.com/hyperledger/indy-hipe/pull/119
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 23 Apr 2019 20:34:32 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 30th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
SethiSaab (Wed, 24 Apr 2019 15:53:30 GMT):
Has joined the channel.
mtfk (Thu, 25 Apr 2019 20:48:27 GMT):
We moved tool presenting ODCA concept from github into bitbucket where we would continue work. We already created tickets there to let others contribute and follow the progress. if you have any wishes or ideas for features or issues please feel free to create new ticket or drop us message here.
The bitbucket would allow us to connect repo to pipelines and soon the tool should be available under domain where people can take a look on the tool without need to fetch the code.
Stay tuned!
https://bitbucket.org/dativa4data/odcatool/
phoniks (Thu, 25 Apr 2019 22:37:02 GMT):
@mtfk I'm super excited to tackle the IPFS integration! Can you explain a bit more this concept of the DRI being used to access different layers? I think example would be particularly helpful for me.
mtfk (Fri, 26 Apr 2019 04:14:47 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=9sLHA3TuSizAKXWMp) @phoniks I would suggest to start here: https://drive.google.com/drive/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP
I talked about that concept on one of our calls. Basically DRI could be implement in different ways for example magnet link is pretty good one. CID and multihash is as well quite good. The idea of DRI to have it cross network and not only IPFS or swarm.
mtfk (Fri, 26 Apr 2019 04:15:57 GMT):
Another approach would be to use DID and latest spec with content id. the spec is still in progress but sound like it could fit into our vision of DRI
mtfk (Fri, 26 Apr 2019 04:16:25 GMT):
For know to keep it simple IPFS sounds like a good shoot to try it out.
mtfk (Fri, 26 Apr 2019 04:16:58 GMT):
so we need simple JS API which allow us to publish and fetch JSON-LD files ( and structures) to/from IPFS
mtfk (Fri, 26 Apr 2019 04:25:55 GMT):
Here you would find some materials: https://github.com/THCLab/DRI/
phoniks (Fri, 26 Apr 2019 04:39:44 GMT):
Awesome. Thanks Robert!
phoniks (Fri, 26 Apr 2019 04:40:49 GMT):
I'll take a deep dive into this material over the weekend and see if I can take some first steps...
pknowles (Fri, 26 Apr 2019 11:18:36 GMT):
@phoniks @mtfk I've just uploaded the latest ODCA paper and deck to the following shared area. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Fri, 26 Apr 2019 15:43:32 GMT):
First draft of paper: "Overlays Data Capture Architecture (ODCA): Providing a standardized global solution for data capture and exchange". Constructive feedback welcome. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
VipinB (Fri, 26 Apr 2019 20:57:24 GMT):
Has joined the channel.
troyronda (Sat, 27 Apr 2019 17:52:09 GMT):
Has joined the channel.
pknowles (Sun, 28 Apr 2019 04:31:10 GMT):
@VipinB [cont. from #indy channel] A schema base provides a standard base from which to decentralize data and, as such, all PII attributes have to be flagged in that base object. If, for example, an issuer were to publish a schema base having failed to flag a PII attribute, a new version would have to be created in order to flag that attribute as sensitive and that new version would inevitably become the standard. In other words, that refinement would not be done via an overlay. Other than that, you're spot on. Attribute names and types from a referenced source such as schema.org can be embedded into a schema base. I'd love to see schema.org flagging PII attributes at their end but that might be a tough sell. In any case, the PII schema object will remain an integral part of schema base functionality. There are also some neat catches that we can provide to a schema issuer. For instance, you'll notice that "Free-Form Text Fields / Unstructured Data" is a BIT element. That allows us to apply some deep logic in the foundational code to warn the issuer of any attributes that will be treated as unstructured data fields prior to publishing. Here, if an attribute has a data type of "Text" defined in the schema base and a linked entry overlay has not been used to add predefined field values to that attribute, it would be treated as a "Free-Form Text Field" and subsequently flagged as a PII attribute. If we were to let that slide, there would be a privacy risk as an end user would be able to potentially enter PII information into that text field (I reckon a "Ban all free-form text fields!" working group would be oversubscribed! 🙂). Although there is nothing stopping a schema issuer from publishing a schema base as a stand alone object, I would strongly advocate that, at the very least, an entry overlay be constructed to accompany that object at the time of initial publish. [Cc: @mtfk ]
pknowles (Sun, 28 Apr 2019 04:31:10 GMT):
@VipinB [cont. from #indy channel] A schema base provides a standard base from which to decentralize data and, as such, all PII attributes have to be flagged in that base object. If, for example, an issuer were to publish a schema base having failed to flag a PII attribute, a new version would have to be created in order to flag that attribute as sensitive and that new version would inevitably become the standard. In other words, that refinement would not be done via an overlay. Other than that, you're spot on. Attribute names and types from a referenced source such as schema.org can be embedded into a schema base. I'd love to see schema.org flagging PII attributes at their end but that might be a tough sell. In any case, the PII schema object will remain an integral part of schema base functionality. There are also some neat catches that we can provide to a schema issuer. For instance, you'll notice that "Free-Form Text Fields / Unstructured Data" is a BIT element. That allows us to apply some deep logic in the foundational code to warn the issuer of any attributes that will be treated as unstructured data fields prior to publishing. Here, if an attribute has a data type of "Text" defined in the schema base and a linked entry overlay has not been used to add predefined field values to that attribute, it would be treated as a "Free-Form Text Field" and subsequently flagged as a PII attribute. If we were to let that slide, there would be a privacy risk as an end user would be able to potentially enter PII information into that text field. Although there is nothing stopping a schema issuer from publishing a schema base as a stand alone object, I would strongly advocate that, at the very least, an entry overlay be constructed to accompany that object at the time of initial publish. [Cc: @mtfk ]
stone-ch (Sun, 28 Apr 2019 06:00:33 GMT):
Has joined the channel.
VipinB (Sun, 28 Apr 2019 10:38:53 GMT):
@pknowles are there any implementations of this? Or is it just a proposal? The BIT comes from the Kanatara Initiative? Are there known schemas currently used in the Enterprise for Identity capture, Authentication, Authorization other than what comes from Schema.org (Person) that refer to those PII-Attributes? Do you have any references for these? Thanks for moving discussion here.
VipinB (Sun, 28 Apr 2019 10:38:53 GMT):
@pknowles are there any implementations of this? Or is it just a proposal? The BIT comes from the Kanatara Initiative. Do they have schemas for Identity, Identity scoring etc. Are there known schemas currently used in the Enterprise for Identity capture, Authentication, Authorization other than what comes from Schema.org (Person) that we could qualify using pii-attributes? Do you have any references for these? Thanks for moving discussion here.
pknowles (Sun, 28 Apr 2019 12:51:50 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=zPDg4Fi3YGBG5vfYa) @VipinB We performed a command line "Overlays" demo at IIW back in May 2018 to some great feedback. Following detailed input from the Hyperledger Indy Semantics WG and the Hyperledger Technical Ambassadors, we are now in the process of developing the ODCA middleware tooling in the Dativa Innovation Hub [ https://www.dativa.com/innovation-hub/ ]. The final tool will be white labelled, open source, free to use with no IP. It looks like we'll be working with Roche Pharmaceuticals and Roche Diagnostics for the the first two pilots. We're also applying for grants to help fund the ODCA initiative. It feels like we're beyond the conceptual phase now and into the early pilot phase although there is still a lot of coding to be done. I spearheaded the BIT initiative following lengthy discussions with Elizabeth Renieris at the same edition of IIW. The first version of the BIT was published in early September [ https://www.dativa.com/blinding-identity-taxonomy/ ] and, soon after, I donated it to Kantara Initiative. The latest version of the BIT is housed with the Consent & Information Sharing WG at Kantara Initiative as a work in progress. The BIT has remained stable for the past 3 months but it is not an official standard yet. Regarding Kantara, I'll check with @AndrewHughes3000 to see if they have (or know of any) schemas for Identity, Identity scoring, Identity capture, Authentication or Authorization that we could qualify using pii-attributes. I'll get back to you once I have an answer. In the meantime, here is a nice quote from Colin Wallis, Kantara's Executive Director, regarding the BIT: " _The BIT is one of those critical pieces of behind-the-scenes plumbing that is expected to fundamentally improve data protection of personal data as deployment rates in both traditional and distributed ledger technology (DLT) domains rise._ "
VipinB (Sun, 28 Apr 2019 13:07:57 GMT):
@pknowles thanks for the detailed answer. I am poking around https://bitbucket.org/dativa4data/odcatool/. Elizabeth Reneiris is a friend (at least I like to think so), and I have appreciated her clear thinking around privacy topics. I have also written on medium (https://medium.com/@vipinsun/security-privacy-in-the-age-of-surveillance-6a0fbeae97d4) on the subject of Privacy, more from a 4th Amendment point of view, but I look at some remedies (Combination Therapy) and appropriate technology is definitely one of the tools needed in Combination Therapy. I think BIT is very important- I assume you are going to be at this year's IIW. I wont be there, but will be hosting Drummond and possibly Nathan on May 1st at the Hyperledger Identity Working Group call for a recap. #identity-wg ... Looking forward to hearing from you. I am reading some of the docs from Kantara Initiative on the topic as well. Any pointers on commonly used schemas (not just from kanatara) for Identity related work will be appreciated. We are writing a paper in HL IDWG on Identity and the Blockchain with specific reference to DLTs. As a cross-platform initiative, this is more like a survey of the field with references for a deeper dive targeted to generalists who are interested in Identity.
atomeel (Mon, 29 Apr 2019 01:53:48 GMT):
Has joined the channel.
Unni_1994 (Mon, 29 Apr 2019 10:23:46 GMT):
Has joined the channel.
pknowles (Tue, 30 Apr 2019 16:12:05 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 30th April, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• ID Proofing ( @mtfk ) - 40 mins
• ODCA update ( @pknowles ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
VipinB (Tue, 30 Apr 2019 17:31:53 GMT):
@mtfk Are you suggesting that during Authorization, we do this decentralized surety (i.e. Authentication) every time we get granted. To be practical, we need some way to expose this to the relying party
VipinB (Tue, 30 Apr 2019 17:33:37 GMT):
@mtfk for mobile, you use the different phone only to contact the bad guy from a random address. The phone will be turned off with no battery during other times.
VipinB (Tue, 30 Apr 2019 17:41:48 GMT):
@mtfk fascinating thought experiment
VipinB (Tue, 30 Apr 2019 17:48:05 GMT):
@mtfk accumulators. ZKP of that private data etc. can be used instead of granular
VipinB (Tue, 30 Apr 2019 17:48:51 GMT):
Accumulators like you mentioned ....
VipinB (Tue, 30 Apr 2019 17:49:14 GMT):
Negative is already happening like @mtfk
VipinB (Tue, 30 Apr 2019 17:49:18 GMT):
said
VipinB (Tue, 30 Apr 2019 17:51:00 GMT):
Multifactor taken to polyfactor... great job @mfk
mtfk (Tue, 30 Apr 2019 18:49:47 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=vAh5p2i7uqAmXh6ug) There is no need to do the whole process each time. You can imagine that you have to provide proofs (randomly choose by versifier) from yesterday, last week and 5 months ago. You digital wallet could store those proofs in a form of verifiable credentials of some sort. So it would be quite simple and fast process.
pknowles (Tue, 30 Apr 2019 18:49:49 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, May 14th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
mtfk (Tue, 30 Apr 2019 18:51:22 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=d3TQMRpRuawGuaNK2) @VipinB of course in that case would be hard to track it as there won't be correlation but if you calling to same guy all the time they can find out who is this guy (if he does not do as you do) if he does you have a problem of exchanging phone numbers anyway). But yes there are some cases where you could hide if you know how.
mtfk (Tue, 30 Apr 2019 18:56:17 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=ZsXB7yH9Zuoi6EsTT) The point here is that more signals you have stronger identity you posses. - more trustworthy you are. That is where this decentralized identity comes handy as the artifacts are distributed quite well and you can be quite secure.
pknowles (Tue, 30 Apr 2019 19:42:49 GMT):
For any *Indy Semantics WG* folks out at *IIW* this week ... Please reach out to @phoniks who will be presenting the ODCA tomorrow. [My much older brother, @darrell.odonnell is definitely out there!]
pknowles (Tue, 30 Apr 2019 19:42:49 GMT):
For any *Indy Semantics WG* folks out at *IIW* this week, please reach out to @phoniks who will be presenting the ODCA tomorrow. [My much older brother, @darrell.odonnell is definitely out there!]
pknowles (Tue, 30 Apr 2019 19:42:49 GMT):
For any *Indy Semantics WG* folks out at *IIW* this week, please reach out to @phoniks who will be presenting the *ODCA* tomorrow. [My much older brother, @darrell.odonnell is definitely out there!]
pknowles (Tue, 30 Apr 2019 19:42:49 GMT):
For any *Indy Semantics WG* folks out at *IIW* this week, please reach out to @phoniks who will be presenting *ODCA* tomorrow. [My much older brother, @darrell.odonnell is definitely out there!]
pknowles (Tue, 30 Apr 2019 19:42:49 GMT):
For any *Indy Semantics WG* folks out at *IIW* this week, please reach out to @phoniks who will be presenting *ODCA* tomorrow. [My much older brother @darrell.odonnell is definitely out there!]
richzhao (Tue, 30 Apr 2019 22:07:47 GMT):
Has joined the channel.
phoniks (Wed, 01 May 2019 19:00:36 GMT):
There's discussion going on here at IIW about using DIDs in git, which feels like it has an application in storing overlays in a secure. Also, @darrell.odonnell come find me! I'm wearing a dark side of the moon t-shirt.
phoniks (Wed, 01 May 2019 19:00:36 GMT):
There's discussion going on here at IIW about using DIDs in git, which feels like it has an application in storing overlays in a secure and audit-able manner. Also, @darrell.odonnell come find me! I'm wearing a dark side of the moon t-shirt.
pknowles (Wed, 01 May 2019 19:29:42 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=sjFFK9sH7afwwywb7) @phoniks Thanks for the update. If you can find out as much information as possible regarding that application, that would be great. Perhaps you can then give a short presentation during an upcoming *Indy Semantics WG*. You're my eyes and ears at IIW this year!
pknowles (Wed, 01 May 2019 19:29:42 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=sjFFK9sH7afwwywb7) @phoniks Thanks for the update. If you can find out as much information as you can regarding that proposed application, that would be great. Perhaps you can give a short presentation during an upcoming *Indy Semantics WG*. You're my eyes and ears at IIW this year!
pknowles (Wed, 01 May 2019 19:29:42 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=sjFFK9sH7afwwywb7) @phoniks Thanks for the update. If you can find out as much information as you can regarding that proposed application, that would be great. Perhaps you can give a short presentation during an upcoming *Indy Semantics WG*. You're my eyes and ears at *IIW* this year!
phoniks (Wed, 01 May 2019 21:22:25 GMT):
@pknowles There's a board up for people to post info on working groups. When are the Indy Semantics WG calls held (both so I can post it on the board, and also so I can jump on them).
pknowles (Wed, 01 May 2019 21:41:26 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=SnkM4LFPrPESMXer9) @phoniks Every other Tuesday at 10am-11.15am PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. The next one is on Tuesday, May 14th.
nage (Fri, 03 May 2019 01:42:30 GMT):
A note about the Hyperledger Aries launch, since this group spans ledger and protocol you may be wondering which project will host this effort. Because Aries is ledger agnostic, it can support alternative data models, meaning this effort will stay inside Indy with effort in Aries for protocol support. I expect it will stay an Indy effort and coordinate with Aries.
phoniks (Wed, 08 May 2019 15:19:11 GMT):
So, one of the most exciting things to come out of IIW this year was the 1st draft spec for a did:git method. The idea is basically to use the git repository as a source of truth about its contents, and its contributors. Interestingly, it also includes support for a governance file that would define the rules for how maintainers could be added, and how releases were issued (with multi sig). Now, maybe I'm getting a bit ahead of myself - I'll admit to not fully understanding either overlays, or this DID method completely yet - but I wonder if anyone else sees this as an ideal way to manage overlays. My thinking is that if a consortium of businesses wishes to maintain a common set of overlays they could decide on a governance scheme and then collectively manage a git repo using this method. So I'm curious, do people see value in this application of the did:git method? Is it the sort of thing that the ODCA tool should include? @mtfk - I'm particularly interested in your take.
phoniks (Wed, 08 May 2019 15:24:29 GMT):
here's a link to the repo: https://github.com/dhuseby/did-git-spec
Silona (Wed, 08 May 2019 15:50:15 GMT):
@dhuseby
dhuseby (Wed, 08 May 2019 15:50:15 GMT):
Has joined the channel.
Silona (Wed, 08 May 2019 15:51:02 GMT):
So @dhuseby is on vacation so no internet but he'll love this when he gets back for now @nage ?
pknowles (Wed, 08 May 2019 16:20:04 GMT):
@silona @dhuseby Thanks for joining the #indy-semantics channel. If you both DM your email addresses to me, I'll add you to the *Indy Semantics WG* calendar invites. We would love David to talk about the /did:git/ method on a WG call soon. In the meantime, I've stored the *ODCA paper* in the following HL shared area. I'm excited to see what sort of traction there is here. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Wed, 08 May 2019 16:20:04 GMT):
@Silona @dhuseby Thanks for joining the #indy-semantics channel. If you both DM your email addresses to me, I'll add you to the *Indy Semantics WG* calendar invites. We would love David to talk about the /did:git/ method on a WG call soon. In the meantime, I've stored the *ODCA paper* in the following HL shared area. I'm excited to see what sort of traction there is here. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Wed, 08 May 2019 16:20:04 GMT):
@Silona @dhuseby Thanks for joining the #indy-semantics channel. If you both DM your email addresses to me, I'll add you to the *Indy Semantics WG* calendar invites. We would love David to talk about the `did:git` method on a WG call soon. In the meantime, I've stored the *ODCA paper* in the following HL shared area. I'm excited to see what sort of traction there is here. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Wed, 08 May 2019 16:20:04 GMT):
@Silona @dhuseby Thanks for joining the #indy-semantics channel. If you both DM your email addresses to me, I'll add you to the *Indy Semantics WG* calendar invites. We would love David to talk about the `did:git` method on an upcoming semantics call. In the meantime, I've stored the *ODCA paper* in the following HL shared area. I'm excited to see what sort of traction there is here. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
pknowles (Wed, 08 May 2019 16:20:04 GMT):
@Silona @dhuseby Thanks for joining the #indy-semantics channel. If you both DM your email addresses to me, I'll add you to the *Indy Semantics WG* calendar invites. We would love David to talk about the `did:git` method during an upcoming semantics call. In the meantime, I've stored the *ODCA paper* in the following HL shared area. I'm excited to see what sort of traction there is here. https://drive.google.com/drive/u/0/folders/1-Q3CBSYXlRNEvTu7XQfGo-6W5H_yyOA3
phoniks (Wed, 08 May 2019 19:05:34 GMT):
@Silona & @dhuseby I'm prepping a PR against the `did:git` spec right now adding this as a possible motivation.
mtfk (Wed, 08 May 2019 19:32:58 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=BcE35DgAYbWG4nv5F) How are you planning to resolve DID on git?
mtfk (Wed, 08 May 2019 19:37:06 GMT):
Another issue which could be problematical is that actually git is not immutable. You can easily override the history of the git and then you depend how many honest copies are on the network. Or you go "centralized" path and say that github account holding this repo is the only place of truth.
mtfk (Wed, 08 May 2019 19:38:13 GMT):
Of course the commit ID is immutable (almost impossible to get collision) but it means that if someone (even accidentally override the git history) you won't be able to resolve that specific commit anymore.
mtfk (Wed, 08 May 2019 19:40:37 GMT):
Because of above I would prefer solutions like IPFS and IPID for ODCA where you can create local swarm and connect everyone from consortium or just use public network to give access to anyone.
george.aristy (Wed, 08 May 2019 19:41:19 GMT):
Has joined the channel.
mtfk (Wed, 08 May 2019 19:42:01 GMT):
The only missing part of the IPID is the connection with verified identity which is publishing that bit of content.
mtfk (Wed, 08 May 2019 19:44:09 GMT):
This what for example sovrin offering or in git spec --signoff feature.
mtfk (Wed, 08 May 2019 19:44:58 GMT):
There is interesting work done on DID spec where actually you could combine any did compatible method with CID like ipfs hash or magnet link
mtfk (Wed, 08 May 2019 19:45:58 GMT):
Of course my favorite is DRI - decentralize resource identifier :) but not sure yet how this would be connected to verified identity.
pknowles (Wed, 08 May 2019 20:04:30 GMT):
I've just published the *ODCA paper* on medium.com for public consumption - https://medium.com/@paul.knowles_52509/overlays-data-capture-architecture-odca-providing-a-standardized-global-solution-for-data-caeb1679137a
phoniks (Thu, 09 May 2019 18:57:16 GMT):
So the identity info is stored in-band. Essentially you'd have a `/repo/.git/dids` where you would store the DID docs.
mtfk (Thu, 09 May 2019 18:58:37 GMT):
but where is the repo? Is it on github? Is it on my private server? How people can find this repo if they do not have it?
mtfk (Thu, 09 May 2019 18:59:10 GMT):
Currently if you want to share git with someone you need to give him access to the machine where it is (by hosting it or just give the access to the file system)
phoniks (Thu, 09 May 2019 19:03:48 GMT):
I think it's good to be flexible. so maybe you have a private git server or maybe you host it on IPFS, or maybe you do host it on github.
phoniks (Thu, 09 May 2019 19:05:28 GMT):
I think the tool could pretty easily accommodate any of those options
mtfk (Thu, 09 May 2019 19:07:02 GMT):
Yes but how the did would resolve to specific DID doc if you do not know my address but just commit ID ?
phoniks (Thu, 09 May 2019 19:08:08 GMT):
ahhh, I see. they're mapped in the dids directory
phoniks (Thu, 09 May 2019 19:08:28 GMT):
so you have a genesis commit
phoniks (Thu, 09 May 2019 19:08:40 GMT):
after which you treat the repo as immutable
phoniks (Thu, 09 May 2019 19:08:51 GMT):
and sign the commits according to your governance plan
mtfk (Thu, 09 May 2019 19:08:54 GMT):
where this did directory is stored?
mtfk (Thu, 09 May 2019 19:08:54 GMT):
where this did directory is stored/hosted?
phoniks (Thu, 09 May 2019 19:10:12 GMT):
it's part of the repo itself. So where ever you host your repo.
phoniks (Thu, 09 May 2019 19:11:15 GMT):
and the files are named as the PK of the DID
mtfk (Thu, 09 May 2019 19:12:45 GMT):
ok another way here is example of the DID:
`did:git:abcde12345` Which I shared with you
mtfk (Thu, 09 May 2019 19:12:50 GMT):
how you would get did document?
phoniks (Thu, 09 May 2019 19:18:14 GMT):
"The git did read operation will "resolve" the "id" by looking up the SHA1 hash of the commit that added the DID document to the repo and dynamically add the "id" member to what is rendered to the user."
phoniks (Thu, 09 May 2019 19:18:20 GMT):
from the spec
mtfk (Thu, 09 May 2019 19:19:08 GMT):
Yes but how you would look up the SHA1 hash if you do not know where repo is?
mtfk (Thu, 09 May 2019 19:20:22 GMT):
for example if I have did:ipid:asdfgh1234 I know that I have to go to IPFS network and look up hash on the IPFS network
if I have did:git:sha1 I have no idea where to check right? Or am I missing something?
phoniks (Thu, 09 May 2019 19:21:51 GMT):
No I'm sure I'm the one that's missing something haha
phoniks (Thu, 09 May 2019 19:23:28 GMT):
Screen Shot 2019-05-09 at 12.22.54 PM 1.png
mtfk (Thu, 09 May 2019 19:24:07 GMT):
The idea of the DID spec is that when you adding new method it explain how the did can be resolved. So where to look it up to get the did document.
Some methods basically points you to specific network on which you can resolve the hash form did to a did document. For `sov` is sovrin network for `ipid` is IPFS for uport is the string it self.
The question is where I should look for this commit ID from `did:git` in order to get the did document
mtfk (Thu, 09 May 2019 19:24:54 GMT):
In many cases I could create my own repository and host it but then only myself is able to resolve it as I know where the git is stored.
mtfk (Thu, 09 May 2019 19:25:13 GMT):
If I would like to share that repo with others I would need to share with them DID and the location of the repository
mtfk (Thu, 09 May 2019 19:25:29 GMT):
which makes it quite centralized solution and error prone
mtfk (Thu, 09 May 2019 19:25:47 GMT):
of course you could always choose github which is public repository which anybody can use to resolve it
mtfk (Thu, 09 May 2019 19:26:00 GMT):
but then it should not be called `did:git` but `did:github`
phoniks (Thu, 09 May 2019 19:26:37 GMT):
`did:github` exists I believe
mtfk (Thu, 09 May 2019 19:27:45 GMT):
https://w3c-ccg.github.io/did-method-registry/
mtfk (Thu, 09 May 2019 19:27:50 GMT):
for sure not here
mtfk (Thu, 09 May 2019 19:28:31 GMT):
of course git spec would make sens for some specific use cases like company base did repository or something
mtfk (Thu, 09 May 2019 19:28:43 GMT):
but this needs to be clear from the beginning how and where it is hosted
mtfk (Thu, 09 May 2019 19:29:13 GMT):
because that way it won't be much different from DNS base one as you would always need to use some domains to point to the server
mtfk (Thu, 09 May 2019 19:29:39 GMT):
you would just get extra features of git how to actually store and track did document
phoniks (Thu, 09 May 2019 19:31:18 GMT):
Right, so the usecase I'm thinking of is a consortium where presumably you do agree on that in advance
phoniks (Thu, 09 May 2019 19:31:55 GMT):
and the benefit I think is the ability to add a lightweight governance mechanism to the management of shared overlays
kdenhartog (Thu, 09 May 2019 19:38:07 GMT):
@dhuseby will be able to highlight this approach better when he's back from vacation. I believe the intent is to operate in a p2p fashion and would therefore not define a discovery mechanisms like other DID methods. This is similar to how the DID:peer method is working. A DID method is not required to be discoverable. As an example, a 10.0.* IP address is not globally resolvable. I can only discover it when I'm on a local network. Another example is if I host a local intranet domain and let my local DNS server handle the resolving I can discover it (which would likely resolve to a local IP). However, if I operate on a different network outside the local network, I cannot resolve the domain, and therefore cannot find the IP.
phoniks (Thu, 09 May 2019 19:41:33 GMT):
thanks. I was just about to mention did peer, but that explanation is very illuminating, for me at least.
mtfk (Thu, 09 May 2019 19:58:26 GMT):
Even if you operate with p2p fashion you still need to define how to resolve it. If you assume that it is local repository or local ip, dns what ever it would be need to be part of the spec. The good example of resolution process is this what the guys from uport did with their DID. You can compose did document directly from the string within DID so you don't have to reach any server, place, location. Just build it from there. Of course it is very limiting but it shows how flexible did spec is.
Here in case of p2p communication fashion you could do similar things all depends how you would like to design it. If you assume that it is always localhost, would be fine as well.
But this part needs to be clearly specify in the spec. Because if you assume that anyone can define their own location then it should be part of the DID (e.g. encoded within the string SHA1(SHA1+location) or something like that. Does that make any sense?
mtfk (Thu, 09 May 2019 19:59:45 GMT):
And back to the main question if this would make sens for ODCA, it could if there is close repository of ODCA and nobody from outside can use it.
mtfk (Thu, 09 May 2019 20:01:25 GMT):
I always try to think about ODCA objects in a way that they have two properties:
- immutable (like ipfs hash)
- source verifiable (verify who issued it if I can trust it - like DID)
kdenhartog (Thu, 09 May 2019 20:01:27 GMT):
In the method spec it says "The git did read operation will "resolve" the "id" by looking up the SHA1 hash of the commit that added the DID document to the repo and dynamically add the "id" member to what is rendered to the user."
mtfk (Thu, 09 May 2019 20:02:34 GMT):
Yep, how I could know where the repo is? Is it part of the spec somewhere?
mtfk (Thu, 09 May 2019 20:03:06 GMT):
For example I could have multiple repositories (each for department)
kdenhartog (Thu, 09 May 2019 20:03:16 GMT):
No knowing the location is relevant to discovery. Knowing how to resolve is orthogonal. I do think resolution will require better detail though.
kdenhartog (Thu, 09 May 2019 20:04:42 GMT):
By that I mean, I can go through the resolution algorithm, but because I don't have access to the location of the DID Doc I cannot discover it.
kdenhartog (Thu, 09 May 2019 20:05:00 GMT):
Similar to how I can know the domain of the intranet domain, but not able to access the server.
mtfk (Thu, 09 May 2019 20:06:21 GMT):
You are right the resolution process is clearly defined. The question is how base on this description someone could implement it e.g. in Digital Wallet.
mtfk (Thu, 09 May 2019 20:07:00 GMT):
There would be good to have clear specification about the discovery process and how to transport information about it together with DID
mtfk (Thu, 09 May 2019 20:07:00 GMT):
It would be good to have clear specification about the discovery process and how to transport information about it together with DID
mtfk (Thu, 09 May 2019 20:07:00 GMT):
It would be good to have clear specification about the discovery process and how to transport information about where to look for it together with DID
kdenhartog (Thu, 09 May 2019 20:08:56 GMT):
I'm not sure discovery is relevant. Similar to how the peer did method spec doesn't specify how to cache, and lookup in cache to resolve a DID Doc.
kdenhartog (Thu, 09 May 2019 20:09:27 GMT):
It's up to the implementers to define these aspects I believe. @dhuseb
kdenhartog (Thu, 09 May 2019 20:09:27 GMT):
It's up to the implementers to define these aspects I believe. @dhuseby may have other ideas though.
kdenhartog (Thu, 09 May 2019 20:11:05 GMT):
The closest the peer DID method spec comes to defining this is "by sending a state_request message from one peer to another"
kdenhartog (Thu, 09 May 2019 20:11:40 GMT):
However this doesn't mean that if I send this message to a random server that they must send me back a DID Doc. The resolution would fail instead.
kdenhartog (Thu, 09 May 2019 20:12:04 GMT):
Similar to if I send a DNS request to a random web server, I shouldn't expect it to send a proper reply back.
mtfk (Thu, 09 May 2019 20:13:27 GMT):
Don't you think that leaving that part to the implementer won't introduce any problems?
With my understanding is similar to the example where I could take `did:sov` and implement it in a way that it always resolve against my own test sovrin network. Means that if someone would take it would not be able to resolve it unless they use my implementation.
kdenhartog (Thu, 09 May 2019 20:14:19 GMT):
yeah that's how it works right now. This is with good intention, it allows for extensibility.
kdenhartog (Thu, 09 May 2019 20:17:05 GMT):
For example in a network of networks design, I may want to support many networks that have different DSTF. In this case, I would likely resolve to the genesis_txn_file I have on hand a gensis txn file for a specific network (defined as did:sov:network:id) and then I would resolve the ID from that specific network.
kdenhartog (Thu, 09 May 2019 20:18:45 GMT):
The only network I've heard that specifies to a specific ledger is the sidetree did method for BTC and that's so that it can specify to a certain fork. If another fork occurs, they plan to update which fork the method should resolve to.
mtfk (Thu, 09 May 2019 20:20:04 GMT):
So following that lead it could be something like
did:git:SHA1?location=localhost
or
did:git:SHA1?location=github.com/did/repo
mtfk (Thu, 09 May 2019 20:20:24 GMT):
just skip the syntax as it is not correct probably with that what is so far used in the did spec
mtfk (Thu, 09 May 2019 20:20:52 GMT):
the point is that did through params could help you out to find out where to look on it
kdenhartog (Thu, 09 May 2019 20:21:16 GMT):
I don't think specifying location is necessary. Rather I need to know which resolver to ask so that I can discover it.
kdenhartog (Thu, 09 May 2019 20:21:36 GMT):
By specifying to a specific location how do I know which localhost you're referring to?
kdenhartog (Thu, 09 May 2019 20:21:43 GMT):
as it my localhost or yours?
mtfk (Thu, 09 May 2019 20:22:47 GMT):
the point is that params helping you out to find it if that would be through resolver or direct path that could be open to the debate
mtfk (Thu, 09 May 2019 20:23:15 GMT):
but you are right context is quite important as location does not work if you loose the location
mtfk (Thu, 09 May 2019 20:23:15 GMT):
but you are right context is quite important as location does not work if you loose the context
mtfk (Thu, 09 May 2019 20:23:46 GMT):
having just relative path should work as soon as you are aware of that you should have that git repo with you
mtfk (Thu, 09 May 2019 20:24:02 GMT):
So you could imagine that within the company each digital wallet by default fetch did directory
kdenhartog (Thu, 09 May 2019 20:24:11 GMT):
We may store the exact same git repo locally, but that doesn't mean that my version is the same as your version. Just that they once were based on the same probabilistically. (I say that because sha1 isn't believe to be perfectly collision resistant anymore.)
mtfk (Thu, 09 May 2019 20:24:13 GMT):
and then in p2p manner everyone can resolve each did within the company
kdenhartog (Thu, 09 May 2019 20:24:34 GMT):
yup, this is in line with what I'm thinking.
kdenhartog (Thu, 09 May 2019 20:24:59 GMT):
However it's not the location that's relevant. It's which resolver that you ask that is.
kdenhartog (Thu, 09 May 2019 20:25:23 GMT):
Similarly, if I live in China and type in a banned website it doesn't resolve.
kdenhartog (Thu, 09 May 2019 20:25:41 GMT):
That resolvablility isn
kdenhartog (Thu, 09 May 2019 20:25:41 GMT):
That resolvability isn't because the domain doesn't exist, but rather because the dns doesn't have a record to resolve to an IP.
kdenhartog (Thu, 09 May 2019 20:26:57 GMT):
China may not be the best example because I think they ban on IP rather than dns lookup, but they may do both.
mtfk (Thu, 09 May 2019 20:27:46 GMT):
yep, you are right, for me right now in my mind location = place where I can get what I need (in that case did doc) if that would be done through resolver mechanism or just pointing it directly either way should be fine.
mtfk (Thu, 09 May 2019 20:28:23 GMT):
For example you could host your git on IPFS :) and point to the ipfs://asd910jd912jd91jd192 d which would be ipns
kdenhartog (Thu, 09 May 2019 20:28:41 GMT):
Yeah, that nuance took me awhile to discover. Again Dave may have other thoughts about it, but this is how I've thought about it because it's how the peer method spec works.
kdenhartog (Thu, 09 May 2019 20:29:08 GMT):
yup, I actually like the idea of hosting git repos on ipfs too.
phoniks (Thu, 09 May 2019 20:31:26 GMT):
I think that's a pretty exciting possibility as well
mtfk (Thu, 09 May 2019 20:33:24 GMT):
again instead of IPFS I would love to use something like DRI :) Which could support any decentralized storage but that another long discussion :)
mtfk (Thu, 09 May 2019 20:33:49 GMT):
Guys in did spec WG discussion about content_id parameter which actually could server that purpose so maybe DID would have that build in automatically
kdenhartog (Thu, 09 May 2019 20:34:07 GMT):
I haven't heard of DRI. do you have a link to more details about this?
phoniks (Thu, 09 May 2019 20:34:13 GMT):
actually I'm curious about that. would you consider a DRI a type of multiaddress?
mtfk (Thu, 09 May 2019 20:36:14 GMT):
DRI is a Decentralized Resource Identifier - it is my attempt to address need to be able to use content identifiers across different decentralize networks (like swarm, ipfs, torrent etc..) similar what magnet link is doing with mutlihashes
kdenhartog (Thu, 09 May 2019 20:36:39 GMT):
Got a spec I can read?
mtfk (Thu, 09 May 2019 20:37:17 GMT):
There is presentation which I did recently on semantic call, let me fetch the link
mtfk (Thu, 09 May 2019 20:38:10 GMT):
Here some materials with the deck which I used for presentation: https://github.com/THCLab/DRI/
mtfk (Thu, 09 May 2019 20:39:24 GMT):
https://drive.google.com/drive/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP
mtfk (Thu, 09 May 2019 20:39:31 GMT):
and here the recording from the call
mtfk (Thu, 09 May 2019 20:43:43 GMT):
and in the context did p2p I think you could be interested as well into ID proofing - https://drive.google.com/drive/folders/1Deb8JZ0VoMpYqXMEWpRKomWYbADqp86j
we are trying to work out on the new approach to the identity in truly decentralize manner by monitoring signals and impact within environment instead of looking on specific issued credentials.
phoniks (Thu, 09 May 2019 21:31:35 GMT):
@mtfk can you draw a distinction between DRIs and multiaddresses? https://multiformats.io/multiaddr/
mtfk (Thu, 09 May 2019 21:43:26 GMT):
I would say that multiaddress sits layer above DRI, DRI is much more closer to the CID/Multihash from IPFS (if not same thing). basically DRI is just an attempt to trigger discussion how to solve problem of different content addresses formats. And important part here is that we are operating here only within the space of Content Base network. So we are looking for content not the location.
mtfk (Thu, 09 May 2019 21:45:12 GMT):
The idea is to have CID for each ODCA object which then can be served on multiple decentralized networks which is not controlled by anyone. Same like with IPFS object as soon as there is someone willing to host the file it never disappear. It comes to this notion of UNIT of LANGUAGE. Which we discussed couple of times. Nobody should control the language and schema base object and overlays are meta language for data.
phoniks (Fri, 10 May 2019 01:36:12 GMT):
Okay I think I'm starting to understand.
pknowles (Tue, 14 May 2019 15:44:15 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 14th May, 2019
Note that there have been some clock changes around the globe. Here are the times for this week:
11am-12.15am PT
12pm-13.15pm MT
1pm-2.15pm CT
2pm-3.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @kenebert
Agenda:
• Introductions (Open) - 5 mins
• Breaking down an Informed Consent Form (ICF) into ODCA consent schema constructs
( @janl ) - 35 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/7391019238
Or iPhone one-tap : US: +16465588665,,7391019238# or +14086380986,,7391019238#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 7391019238
pknowles (Tue, 14 May 2019 15:44:15 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 14th May, 2019
Note that there have been some clock changes around the globe. Here are the times for this week:
11am-12.15am PT
12pm-13.15pm MT
1pm-2.15pm CT
2pm-3.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @kenebert
Agenda:
• Introductions (Open) - 5 mins
• Breaking down an Informed Consent Form (ICF) into ODCA consent schema constructs ( @janl ) - 35 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/7391019238
Or iPhone one-tap : US: +16465588665,,7391019238# or +14086380986,,7391019238#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 7391019238
pknowles (Tue, 14 May 2019 15:44:15 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 14th May, 2019
Note that there have been some clock changes around the globe. Here are the times for this week:
11am-12.15pm PT
12pm-13.15pm MT
1pm-2.15pm CT
2pm-3.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @kenebert
Agenda:
• Introductions (Open) - 5 mins
• Breaking down an Informed Consent Form (ICF) into ODCA consent schema constructs ( @janl ) - 35 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/7391019238
Or iPhone one-tap : US: +16465588665,,7391019238# or +14086380986,,7391019238#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 7391019238
nage (Tue, 14 May 2019 19:17:41 GMT):
Wow, I have really fallen behind on this thread. My idea was that the identifier would be based on the commit hash and that the DID Doc itself could contain the main public location of the repository as the service endpoint. That way a repo could be self contained and tools could deal with permissioning or "transaction validation" locally. This makes a git repo effectively into a full blockchain system with the main DID doc acting like the genesis or constitution block that can be used to process subsequent transactions
pknowles (Sat, 18 May 2019 06:57:06 GMT):
New members of this channel would probably benefit from introductory presentations of the two main semantics initiatives currently being worked on by members of the _Indy Semantics WG_ , namely: (i.) the *Rich Schemas* work (Spearheaded by @kenebert / @brentzundel ) and the *Overlays data capture architecture* (ODCA) (Spearheaded by @pknowles / @mtfk ). Hit the :thumbsup: emoji if you agree with that proposal. If it looks like there is substantial interest, I'll schedule in two 1O1 sessions so that newbies can be brought up to speed.
pknowles (Sat, 18 May 2019 06:57:06 GMT):
New members of this channel would probably benefit from introductory presentations of the two main semantics initiatives currently being worked on by members of the _Indy Semantics WG_ , namely: (i.) the *Rich Schemas* work (Spearheaded by @kenebert / @brentzundel ) and (ii.) the *Overlays data capture architecture* (ODCA) (Spearheaded by @pknowles / @mtfk ). Hit the :thumbsup: emoji if you agree with that proposal. If it looks like there is substantial interest, I'll schedule in two 1O1 sessions so that newbies can be brought up to speed.
pknowles (Sat, 18 May 2019 06:57:06 GMT):
New members of this channel may benefit from introductory presentations of the two main semantics initiatives currently being worked on by members of the _Indy Semantics WG_ , namely: (i.) the *Rich Schemas* work (Spearheaded by @kenebert / @brentzundel ) and (ii.) the *Overlays data capture architecture* (ODCA) (Spearheaded by @pknowles / @mtfk ). Hit the :thumbsup: emoji if you agree with that proposal. If it looks like there is substantial interest, I'll schedule in two 1O1 sessions so that newbies can be brought up to speed.
circlespainter (Sat, 18 May 2019 07:36:48 GMT):
Has joined the channel.
jwow (Sat, 18 May 2019 23:03:15 GMT):
Has joined the channel.
jwow (Sat, 18 May 2019 23:07:39 GMT):
If you mean an interactive zoom session, I’m in Sydney (GMT+10) so time can be an issue.
jwow (Sun, 19 May 2019 06:57:06 GMT):
Thanks for that. I think I've a good understanding of what you're trying to accomplish but I still believe there are omissions that are critical for this to proceed. My background comes from XBRL, a framework for exchanging financial or business information (XML based) utilised by many government agencies around the world. Overall it is very similar to what you've described using the term "linkbase" rather than "overlay". E.g. Linkbases for Label, Calculations, Definitions, Presentation.
jwow (Sun, 19 May 2019 07:24:16 GMT):
The critical difference is that XBRL is concerned with the 'facts' or as they refer to them 'concepts' . Concepts are like object classes, while Items are object instances. Concepts are typically given a particular code "
jwow (Sun, 19 May 2019 07:24:44 GMT):
Sorry problems with desktop Rocket.
jwow (Sun, 19 May 2019 07:31:10 GMT):
Concepts are typically given a code, much like passport fields, that avoids the biases of language (to some degree).
So a field '5F2B' has a semantic meaning of 'date of birth'. Using a Label link base this can then be presented as 'Birth Date', 'Date of Birth', 'Date de Naisance', '生日' or whatever while still preserving its meaning. This provides much greater interoperability across languages. Of course you could standardise on Romanised Latin alphabet with Arabic numerals but I think that is to much of a western bias.
jwow (Sun, 19 May 2019 07:35:39 GMT):
Similarly acceptable values can be given for one language then overlayed with another, extended for one country's specific use or remapped for another's. E.g. in Australia gender is typically one of 5 choices: 'Male', 'Female', 'Neither', 'Unknown', 'Declined'. Each of these values would have an associated identifier, so they could be easily translated to another language.
jwow (Sun, 19 May 2019 07:38:56 GMT):
Finally, in defining the 'facts', we need to acknowledge that some require a specific 'as at' date, while the others require 'period' dates. For example, a 'Balance' field is useless unless you know the 'as at' date. While an 'Income' field is pointless if there is not period (FY2019) associated with it.
jwow (Sun, 19 May 2019 07:44:07 GMT):
Lest you think these are traits associated only with finance, consider the 'address' field of a driver's license. Generally it means an 'as at' but for other credentials (say police criminal check) it may be for a period, i.e. at 10 Xyz Street from 1-Jan-2010 to 31-Dec-2013.
jwow (Sun, 19 May 2019 07:45:20 GMT):
Another omission is that that a concept or collection of concepts may have a 'dimension'. This may be values over a number of months/years or across a number of places.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular parts of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one shared roof. If you go to https://github.com/THCLab/schema-cake and read the README.md file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") can also be coded.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular parts of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one shared roof. If you go to https://github.com/THCLab/schema-cake and read the README.md file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") have a DID reference to help drive standardisation.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular parts of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one roof. If you go to https://github.com/THCLab/schema-cake and read the README.md file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") have a DID reference to help drive standardisation.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular parts of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one roof. If you go to https://github.com/THCLab/schema-cake and read the README.md file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") can have a DID reference to help drive standardisation.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular parts of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one roof. If you go to https://github.com/THCLab/schema-cake and read the README.md file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") can have their own unique DID reference to help drive standardisation.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular aspects of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one roof. If you go to https://github.com/THCLab/schema-cake and read the README.md file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") can have their own unique DID reference to help drive standardisation.
pknowles (Sun, 19 May 2019 07:59:50 GMT):
@jwow Thanks for your input and brief overview of XBRL. I'm tagging in @mtfk , the lead ODCA software architect. He'll be interested in any technical differences between the architectures. As I mentioned previously, the initial published paper doesn't go too deep into some of the more granular aspects of the architecture. It was written so that people could better understand the overall concept. We still need to bring all aspects together under one roof. If you go to https://github.com/THCLab/schema-cake and read the README file, you'll see that, much like "Concepts" in XBRL, "Schema Elements" (which we should probably rename "Schema Base Elements") can have their own unique DID reference to help drive standardisation.
pknowles (Sun, 19 May 2019 08:36:00 GMT):
There are a number of aspects of ODCA that address fundamental issues that XBRL doesn't appear to address: (i.) a built in schema object for flagging PII attributes [check BIT - ref. https://drive.google.com/drive/u/0/folders/1gSD1b70OySIUKNOQTSbQ7khq9oy1V8UP ]; (ii.) the separation of personal data processing, generic consent and specialised consent to enable better consent management throughout the data lifecycle [check PDP - ref. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ] and (iii.) Industry classification code tagging for data object searchability [check GICS/NECS - ref. https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV ]
pknowles (Sun, 19 May 2019 08:36:00 GMT):
There are a number of aspects of ODCA that address fundamental issues that XBRL doesn't appear to address: (i.) a built in schema object for flagging PII attributes [check BIT - ref. https://drive.google.com/drive/u/0/folders/1gSD1b70OySIUKNOQTSbQ7khq9oy1V8UP ]; (ii.) the separation of personal data processing, generic consent and specialised consent to enable better consent management throughout the data lifecycle [check PDP - ref. https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ] and (iii.) Industry classification code tagging for data object searchability [check GICS/NECS - ref. https://drive.google.com/drive/u/0/folders/1uRBKIPT1DA838wTGStYhfj0CKqBKq1rV ]. These are all fundamental for a new decentralised data economy to be actualised.
pknowles (Sun, 19 May 2019 08:51:36 GMT):
@mtfk From the ongoing discussion with @jwow , this is the only aspect that I wanted to double-check with you. I think that this is covered by a combination of a *source overlay* (which deals with dynamic variables) and attributes captured in a linked *PDP schema* (which define parameters for data access). I'd love to hear your thoughts on this point.
pknowles (Sun, 19 May 2019 08:51:36 GMT):
@mtfk From the ongoing discussion with @jwow , this is the only aspect that I wanted to double-check with you is the XBRL concept of 'dimension'. I think that this is covered by a combination of *source overlay* (which deals with dynamic variables) and attributes captured in a linked *PDP schema* (which define parameters for data access and processing). I'd love to hear your thoughts on this.
pknowles (Sun, 19 May 2019 08:51:36 GMT):
@mtfk From the ongoing discussion with @jwow , the only aspect that I wanted to double-check with you is the XBRL concept of 'dimension'. I think this is covered by a combination of *source overlay* (which deals with dynamic variables) and attributes captured in a linked *PDP schema* (which define parameters for data access and processing). I'd love to hear your thoughts on this point.
pknowles (Sun, 19 May 2019 08:51:36 GMT):
@mtfk From the ongoing discussion with @jwow , the only aspect that I wanted to double-check with you is the XBRL concept of 'dimension'. I think this is covered by a combination of *source overlay* (which deals with dynamic variables) and attributes captured in a linked *PDP schema* (which define parameters for data access and processing). I'd love to hear your thoughts on this to ensure that we've got it covered.
pknowles (Sun, 19 May 2019 08:51:36 GMT):
@mtfk From the ongoing discussion with @jwow , the only aspect that I wanted to double-check with you is the XBRL concept of 'dimension'. I think this is covered by a combination of *source overlay* (which deals with dynamic variables) and attributes captured in a linked *PDP schema* (which define parameters for data access and processing). I'd love to hear your thoughts on this though to ensure that we've got it covered.
pknowles (Sun, 19 May 2019 08:51:36 GMT):
@mtfk From the ongoing discussion with @jwow , the only aspect that I wanted to double-check with you is the XBRL concept of 'dimension'. I think this is covered by a combination of *source overlay* (which deals with dynamic variables) and attributes captured in a linked *PDP schema* (which define parameters for data access and processing). I'd love to hear your thoughts on this though to ensure that we've got it covered. [Cc: @janl ]
pknowles (Sun, 19 May 2019 09:12:54 GMT):
I also like the idea of putting a unique DID reference on pre-defined field entries. We haven't gone that granular with ODCA [Cc: @mtfk ]. @jwow - Thanks for bringing that to my attention.
pknowles (Sun, 19 May 2019 09:12:54 GMT):
Missed one. I also like the idea of putting a unique DID reference on pre-defined field entries. We haven't gone that granular with ODCA [Cc: @mtfk ]. @jwow - Thanks for bringing that to my attention.
mtfk (Sun, 19 May 2019 11:15:38 GMT):
@jwow I am not familiar with XBRL but for OCDA some of the most important properties are:
- immutable
- discoverable
- uniquely identifiable
- context aware
For sure you can find some similarities between ODCA and XBRL. ODCA define just the meta language and rules how all stuff should be build. It is not forcing anyone to name field specifically. Standards and most popular schema base objects and overlays would come directly from community and experts from fields. But still it would provide interoperability across different sectors.
mtfk (Sun, 19 May 2019 11:28:33 GMT):
The problem which ODCA is trying to solve is to provide unify data language across any sectors. E.g. XBRL is suited for business reporting. Probably won't fit very well into health care or ecommerce. The future is all about data. We need to find a away to connect different worlds where data are generated, hold or stored. This would be crucial to get data economy possible. You can imagine that business report which you generated with XBRL someone would like to sell on open market or store in his digital wallet. To make that happen ODCA create set of rules which are level higher then any data language like XBRL.
jwow (Mon, 20 May 2019 02:42:10 GMT):
XBRL is indeed focussed on business, but the solution itself is a design (IMHO) that is equally applicable to Credentials & Claims. For example, every concept (fact) has a periodType attribute: typically 'instant' or 'duration' (occasionally 'forever'). This is useful to distinguish the 'fact' from the 'fact attribute' to better understand a claim: is this address, for example, at an instant of time or for a period of time? Of course, a 'context' is needed to determine these. The 'context' gives understanding to the facts in which they are being used. A context 'period' element communicates that period the 'fact' relates to, e.g., the issue date and the expiry date. So the context can be associated with the credential, while the individual claim 'vehicle class licensed to drive = 5' is bound in that context.
jwow (Mon, 20 May 2019 03:22:58 GMT):
I'm not proposing that XBRL should be used for Credentials and Claims. Just that we should adopt the same or similar underlying principles. These include extensibility, interoperability and multilingual.
mtfk (Thu, 23 May 2019 07:41:55 GMT):
What about doing a short presentation about XBRL during our next Semantic Call? I would love to learn a bit more about that topic and see how ODCA could enrich already existing solutions or even just use them.
@pknowles do we have free slot for such presentation for next call?
jwow (Thu, 23 May 2019 07:48:27 GMT):
Timing for East Coast Australia is difficult. What TZ are you in?
pknowles (Thu, 23 May 2019 07:59:04 GMT):
@jwow The bi-weekly Indy Semantics WG calls are every other Tuesday at 3am AEST so we'll forgive you for not attending those calls! I'll reach out to by DM to see if we can arrange an ad-hoc conference call for a XBRL/ODCA discussion. Would you be up for presenting the architecture to me and @mtfk at a date/time that suits you well? Our timezone is CET.
jwow (Thu, 23 May 2019 08:05:39 GMT):
Sure. Maybe like a 6am here. At a function at moment. I'll think about it and outline more later.
TelegramSam (Mon, 27 May 2019 16:36:24 GMT):
Has left the channel.
jwow (Tue, 28 May 2019 05:41:51 GMT):
Sorry for not getting back sooner. Just started a new job, so pretty snowed under with the induction. Should be okay for a conference call next week, maybe early Tuesday or Saturday morning (AEST). Will prepare brief overview of XBRL, an example live site, & JSON XBRL. Let me know
pknowles (Tue, 28 May 2019 15:57:41 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Note that there have been some clock changes around the globe. Here are the times for this week:
Meeting: Indy Semantics Working Group
Date: Tuesday, 28th May, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• DID specification update (Part 2) ( @drummondreed ) - 35 mins
[Ref.: https://docs.google.com/document/d/1qnDExIVjU5bYc601qUdLZIi9UAs1ojlHyKnVoz2zlLM/edit#heading=h.itkracbrxg7m ]
• SSI-related Blinding Identity Taxonomy (BIT) elements ( @pknowles ) - 10 mins
[Ref.: https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 28 May 2019 18:58:05 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, May 14th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 28 May 2019 18:58:05 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, June 11th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
jwow (Wed, 29 May 2019 04:59:02 GMT):
In regard to the structure of requests from verifier our experience in Australia may be relevant: the “100 point check” (see Wikipedia) requires holders to submit a wide variety of credentials, each with different values or weighting, until at least 100 points is reached. This may be passport or birth certificate (70 points) down to drivers license (40 points), mortgage doc (35) or credit card or auto club membership (25). So the user must submit between 2 and 4 credentials.
At APRA, we designed and created or own Domain Specific Language utilising XBRL within a specific Taxonomy. Using short tokens, say PT304, for “Name”, and ADF603 for the form/credential, we could easily write a rule to assign a weight to a credential and add the weight. We could also ensure specific claims such as name, address and dob were consistent across all forms/credentials, or suitable change of address/name credentials were also provided.
The evaluation of the DSL was done on the edge device, so no data strictly needed to be transferred.
Does this help?
mtfk (Wed, 29 May 2019 15:43:45 GMT):
Sound very interesting, I am evaluating possibility to use signals and artifacts for identification where base on different weight of attributes you can identify a person or a thing. Would love to learn more about this "100 point check" and the way how XBRL could actually support such that flow. I was thinking about similar approach for ODCA where you by preserving context and weight you could answer same question using different data and schema. E.g. to prove that you are above 18 years old you could: show passport, driving license, monthly ticket for last 2 years (for adult), diploma from university or simply other data which are some how related with adult person.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is the BIT link ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on the two contained elements that are integral to SSI that I had been entered on the list at conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that the SSI technology is more mature, I believe that those elements can be removed and the following two elements should be added …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear the thoughts of the community on this matter.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on the two contained elements that are integral to SSI that I had been entered on the list at conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that the SSI technology is more mature, I believe that those elements can be removed and the following two elements should be added …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear the thoughts of the community on this matter.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on the two contained elements that are integral to SSI that had been entered at conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that the SSI technology is more mature, I believe that those elements can be removed and the following two elements should be added …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear the thoughts of the community on this matter.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on the two contained elements that are integral to SSI that had been entered in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that the SSI technology is more mature, I believe that those elements can be removed and the following two elements should be added …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear the thoughts of the community on this matter.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on the two contained elements that are integral to SSI that had been entered in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear the thoughts of the community on this matter.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on the two contained elements that are integral to SSI that had been entered in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been entered in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Hyperledger Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version of the BIT ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. That may be considered in future versions as correlation patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. Correlation may be considered in future versions as patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_. Here is a link to the latest version ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. Correlation may be considered in future versions as patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_ ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts of this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. Correlation may be considered in future versions as patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_ ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the above keys would actually constitute PII.
I'm keen to hear people's thoughts on this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. Correlation may be considered in future versions as patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_ ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private keys / master keys_
- _Public keys / symmetric keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the keys actually constitute PII.
I'm keen to hear people's thoughts on this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. Correlation may be considered in future versions as patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_ ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private Keys / Master Keys_
- _Public Keys / Symmetric Keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the keys actually constitute PII.
I'm keen to hear people's thoughts on this.
pknowles (Thu, 30 May 2019 05:11:00 GMT):
The *Blinding Identity Taxonomy* (BIT) aims to provide a needed common standards to help protect the privacy of _personally identifiable information_ (PII) about people, organizations, or things. Note that the current version of the BIT does not identify correlation patterns. Correlation may be considered in future versions as patterns emerge.
The latest version of the BIT resides with Kantara Initiative’s _Consent & Information Sharing WG_ ... https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
During this week’s *Indy Semantics WG* call, I put the spotlight on two contained elements that are integral to SSI that had been included in the taxonomy at the time of conception. Namely, …
- _Self-sovereign Key Identifiers_
- _Decentralised Identifiers (DIDs)_
Now that SSI technology is more mature, I believe that those elements can be removed and replaced by the following two elements …
- _Private Keys / Master Keys_
- _Public Keys / Symmetric Keys_
I had mentioned various DID types and DID Docs as potential BIT elements during the call but, on closer revision, I would suggest that only the _keys_ actually constitute PII.
I'm keen to hear people's thoughts on this.
SethiSaab (Thu, 30 May 2019 11:28:14 GMT):
has Anyone customized universal resolver ?
pknowles (Thu, 30 May 2019 16:12:19 GMT):
Courtesy of some valuable input from @MALodder , a new version of the *BIT* has been submitted and subsequently accepted by Kantara Initiative's _Consent & Information Sharing WG_. The new version has been uploaded to the following HL Indy shared drive: https://drive.google.com/drive/u/0/folders/1gSD1b70OySIUKNOQTSbQ7khq9oy1V8UP
pknowles (Thu, 30 May 2019 16:12:19 GMT):
Courtesy of some valuable input from @MALodder , a new version of the *BIT* has been submitted to (and subsequently accepted by) Kantara Initiative's _Consent & Information Sharing WG_. The new version has been uploaded to the following HL Indy shared drive: https://drive.google.com/drive/u/0/folders/1gSD1b70OySIUKNOQTSbQ7khq9oy1V8UP
MALodder (Thu, 30 May 2019 16:12:19 GMT):
Has joined the channel.
pknowles (Thu, 30 May 2019 17:56:14 GMT):
@peacekeeper :top:
peacekeeper (Thu, 30 May 2019 22:35:21 GMT):
For contributing a driver for a new DID method to the Universal Resolver, see this doc: https://github.com/decentralized-identity/universal-resolver/blob/master/docs/driver-development.md, also feel free to msg me or @creatornader
SethiSaab (Fri, 31 May 2019 04:10:30 GMT):
Thansk @MALodder and @pknowles
ardagumusalan (Tue, 04 Jun 2019 18:10:31 GMT):
Hi everyone. I came across this link https://github.com/sovrin-foundation/protocol/tree/master/themis and wanted to see if this is supported/what is the current status?
ardagumusalan (Tue, 04 Jun 2019 18:10:31 GMT):
Hi everyone. I came across this link https://github.com/sovrin-foundation/protocol/tree/master/themis and wanted to see if this is supported/what is the current status? Does anyone know?
pknowles (Tue, 04 Jun 2019 18:53:30 GMT):
@kdenhartog :top:
kdenhartog (Tue, 04 Jun 2019 19:07:47 GMT):
This is the earliest thinking of agent to agent protocol. In it's current form it's pretty stale at this point, but there was excellent thinking that went into that work.
ardagumusalan (Tue, 04 Jun 2019 20:07:02 GMT):
Got it, thanks
pknowles (Tue, 11 Jun 2019 15:58:20 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Note that there have been some clock changes around the globe. Here are the times for this week:
Meeting: Indy Semantics Working Group
Date: Tuesday, 11th June, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Open Notice (OPN) Network tool (Mark Lizar from OpenConsent) - 45 mins
[Ref.: https://openconsent.com ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 11 Jun 2019 19:45:36 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, June 25th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
SethiSaab (Wed, 12 Jun 2019 06:40:56 GMT):
Hi Team i have question
please help me to get more knowledge on this
Suppose a DID document of a device is there
and this device also have verifiable credentials
Now questions is ---->
What kind of service does a service end point of that device offers
and if a verifier has to check the authneticity of the device using service endpoint
how will he because the verifiable credentials are already available and it can easily verify those by comparing signatures
what additional information we can get from service end point about authenticity of anything even when we have verifiable credentials available for that
rchristman (Thu, 13 Jun 2019 15:15:09 GMT):
Has joined the channel.
drummondreed (Fri, 14 Jun 2019 04:23:59 GMT):
@SethiSaab I believe the short answer is that, if the device has a DID document including an agent service endpoint but the device does not actually host its own agent—rather the agent lives in the cloud—then you could only authenticate the agent for the device, not the device itself.
drummondreed (Fri, 14 Jun 2019 04:24:21 GMT):
In order to authentication the device itself, it must have its own wallet and agent, however minimal.
SethiSaab (Fri, 14 Jun 2019 05:10:30 GMT):
@drummondreed Thanks for the explanation
SethiSaab (Fri, 14 Jun 2019 05:11:03 GMT):
and this will done with the concept of DID -AUTH or something similar to that
SethiSaab (Fri, 14 Jun 2019 05:11:05 GMT):
right?
drummondreed (Fri, 14 Jun 2019 05:12:50 GMT):
Yes. As the DID Comm protocol is proceeding, the easiest option is simply sending a message using authenticated encryption using the DID Comm protocol.
SethiSaab (Fri, 14 Jun 2019 05:14:48 GMT):
Hi Guys I have a question .
As per my knowledge . when we create a DID document it gets saved in parts ... in case of Uport and BItcoin and we get block id and transaction ID . to fetch complete DID Document
but I am confused ... like when we search a DID Document using DID... .how will that work
?
SethiSaab (Fri, 14 Jun 2019 05:19:31 GMT):
I have seen that in case of DID based on bctr . it actually uses the 3rd part (xxxx-xxxx-xxxx) of did did:bctr:xxxx-xxxx-xxxx to reach at the correct block and transaction
SethiSaab (Fri, 14 Jun 2019 05:19:43 GMT):
and that is how it gets the complete document
SethiSaab (Fri, 14 Jun 2019 05:19:53 GMT):
but how does that works in INDY
SethiSaab (Fri, 14 Jun 2019 12:31:04 GMT):
Hi Guys ,
SethiSaab (Fri, 14 Jun 2019 12:32:25 GMT):
I have a question regarding construction of DID documents. I have seen that on some platform did documents are getting generated by extracting data from multiple transactions. like in BTCR did method and in uport did method. Could someone help to understand that how is this working?
drummondreed (Sat, 15 Jun 2019 21:22:03 GMT):
@SethiSaab It is similar on Indy. The NYM transaction stores the actual DID and public key; ATTRIB transactions are used for other DID document properties like service endpoints. A DID resolver such as the DIF Universal Resolver will request all these transactions from an Indy ledger and then compose them into the DID document (if that is the DID resolution result requested).
SethiSaab (Sun, 16 Jun 2019 05:59:39 GMT):
@drummondreed so there will be multiple transanactions and did resolver will combine multipe transactions and extract the data from Attrib transactions merge them and construct a document. Am i right ?
SethiSaab (Sun, 16 Jun 2019 06:00:00 GMT):
as of now i have seen that uport and btcr are saving DID document off chain
SethiSaab (Sun, 16 Jun 2019 06:00:07 GMT):
which is kinda following centralized model
SethiSaab (Sun, 16 Jun 2019 06:00:27 GMT):
but wouldn't saving data on blockchain affect scalability and performance
drummondreed (Sun, 16 Jun 2019 16:10:46 GMT):
@SethiSaab Yes, you are right. uPort and BTCR are using IPFS to save the raw DID document. With Indy, the individual properties of the DID document are stored directly on the ledger. They are small, and Indy ledgers are needed only for public DIDs (the vast majority of DIDs will be peer DIDs that are not stored on a public ledger), so scalability and performance should not be an issue.
drummondreed (Sun, 16 Jun 2019 16:11:17 GMT):
If you haven't read the Peer DID spec, you should. https://dhh1128.github.io/peer-did-method-spec/index.html
SethiSaab (Mon, 17 Jun 2019 05:54:18 GMT):
@drummondreed Thanks , i was not aware of this document . Let me explore this
pknowles (Wed, 19 Jun 2019 14:39:50 GMT):
In January, I wrote a submission to the UK Parliament's Human Rights Committee inquiry on The Right to Privacy ( Article 8 ) and the Digital Revolution. The submission explained how the *Blinding Identity Taxonomy* (BIT) initiative would provide a common standards to help protect the privacy of personally identifiable information (PII) about people, organisations, or things. I've just been informed by the Committee Assistant that the submission has been published. More information on the BIT - https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
pknowles (Wed, 19 Jun 2019 14:39:50 GMT):
In January, I wrote a submission to the UK Parliament's Human Rights Committee inquiry on The Right to Privacy ( Article 8 ) and the Digital Revolution. The submission explained how the *Blinding Identity Taxonomy* (BIT) initiative would provide a common standards to help protect the privacy of personally identifiable information (PII) about people, organisations, or things. I've just been informed by the Committee Assistant that the submission has been published. More information on the BIT via the following Kantara link - https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
drummondreed (Wed, 19 Jun 2019 18:11:34 GMT):
Congrats, Paul! That's awesome news.
pknowles (Wed, 19 Jun 2019 23:03:25 GMT):
Thanks, @drummondreed ... Here is " _The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_ " page [UK Parliament: Joint Committee on Human Rights]. Look for "Dativa - written evidence" in the "Latest evidence" section. https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:03:25 GMT):
Thanks, @drummondreed . Here is "_The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_" page - https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:03:25 GMT):
Thanks, @drummondreed . Here is _The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_ page - https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:03:25 GMT):
Thanks, @drummondreed . Here is " _The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_ " page - https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:03:25 GMT):
Thanks, @drummondreed . Here is " _The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_ " page [UK Parliament: Joint Committee on Human Rights]. Look for "Dativa - written evidence" in the "Latest evidence" section - https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:03:25 GMT):
Thanks, @drummondreed ... Here is " _The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_ " page [UK Parliament: Joint Committee on Human Rights]. Look for "Dativa - written evidence" in the "Latest evidence" section - https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:31:49 GMT):
... and video link to the parliamentary session. https://parliamentlive.tv/event/index/8e8eaaf7-c6cf-43c8-b1ac-5cc8c0273e62
pknowles (Wed, 19 Jun 2019 23:39:49 GMT):
Here is " _The Right to Privacy ( Article 8 ) and the Digital Revolution inquiry_ " page [UK Parliament: Joint Committee on Human Rights]. Look for "Dativa - written evidence" in the "Latest evidence" section. https://www.parliament.uk/business/committees/committees-a-z/joint-select/human-rights-committee/inquiries/parliament-2017/right-to-privacy-digital-revolution-inquiry-17-19/
pknowles (Wed, 19 Jun 2019 23:40:14 GMT):
... and video link to the parliamentary session. https://parliamentlive.tv/event/index/8e8eaaf7-c6cf-43c8-b1ac-5cc8c0273e62
pknowles (Wed, 19 Jun 2019 23:40:14 GMT):
... and a video link to the parliamentary session. https://parliamentlive.tv/event/index/8e8eaaf7-c6cf-43c8-b1ac-5cc8c0273e62
pknowles (Thu, 20 Jun 2019 15:40:43 GMT):
A question to put to all active members of this channel. There have been a number of offline discussions regarding the potential migration of the *Indy Semantics WG* over to Aries (i.e. *Aries Semantics WG* ). Regarding the ODCA work, that is a no-brainer as that architecture is platform agnostic. The question is whether the Rich Schema work can follow suit. I think we should but it to a non-formal vote to start with. Either click on the :thumbsup: or :thumbsdown: emojis to show your preference. We can do a more formal vote on a future WG call. For now, click an emoji!
pknowles (Thu, 20 Jun 2019 15:40:43 GMT):
A question to put to all active members of this channel. There have been a number of offline discussions regarding the potential migration of the *Indy Semantics WG* over to Aries (i.e. *Aries Semantics WG* ). Regarding the ODCA work, that is a no-brainer as that architecture is platform agnostic. The question is whether the Rich Schema work can follow suit. I think we should put it to a non-formal vote to start with. Either click on the :thumbsup: or :thumbsdown: emojis to show your preference. We can do a more formal vote on a future WG call. For now, click an emoji!
pknowles (Thu, 20 Jun 2019 15:40:43 GMT):
A question to put to all active members of this channel. There have been a number of offline discussions regarding the potential migration of the *Indy Semantics WG* over to Aries (i.e. *Aries Semantics WG* ). Regarding the ODCA work, that is a no-brainer as that architecture is platform agnostic. The question is whether the Rich Schema work can follow suit. I think we should put it to a non-formal vote to start with. Either click on the :thumbsup: or :thumbsdown: emojis to show your preference. We can do a more formal vote on a future WG call. For now, click on your preferred emoji to indicate migrating the WG to Aries!
pknowles (Thu, 20 Jun 2019 15:40:43 GMT):
A question to put to all active members of this channel. There have been a number of offline discussions regarding the potential migration of the *Indy Semantics WG* over to Aries (i.e. *Aries Semantics WG* ). Regarding the ODCA work, that is a no-brainer as that architecture is platform agnostic. The question is whether the Rich Schema work can follow suit. I think we should put it to a non-formal vote to start with. Either click on the :thumbsup: or :thumbsdown: emojis to show your preference. We can do a more formal vote on a future WG call. For now, click on your preferred emoji to indicate whether or not we should migrate the WG to Aries!
kenebert (Thu, 20 Jun 2019 17:07:06 GMT):
As the Rich Schema work matures and it becomes ready for integration, it might be a good idea to migrate the work to Aries, in my opinion.
pknowles (Thu, 20 Jun 2019 17:37:15 GMT):
@all - The next *Indy Semantics WG* call is on Tuesday, June 25th at 11am-12.15pm MT (7pm-8.15pm CET) where we will be discussing a proposed HIPE for the context objects as part of the rich schema work that @kenebert and @brentzundel have been spearheading. The proposed HIPE has just been published. Please review and add your comments to this important document before then so that we can have a valuable discussion during the WG call. Thanks, all. https://github.com/hyperledger/indy-hipe/tree/master/text/0138-rich-schema-context
danielhardman (Thu, 20 Jun 2019 17:45:39 GMT):
Regarding Paul Knowles' rich schema question: The crux of the decision, I think, is whether the rich schema work is broader than Indy. Is it our intention that all Aries people should be exposed to and hopefully adopt the rich schema work? If yes, then appropriate location is Aries. If no, then appropriate location is Indy. Specs for Indy's unique approach to credentials belong in Indy, not Aries--that seems clear. I'm less sure about the rich schema stuff.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics * and *Aries Semantics* WG calls on weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics * and *Aries Semantics WG* calls on weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics * and *Aries Semantics WG* calls on weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics * and *Aries Semantics WG* calls on weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work. Keen to hear your thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics * and *Aries Semantics WG* calls on a weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work. Keen to hear your thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics WG* and *Aries Semantics WG* calls on a weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work. Keen to hear your thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to alternate between *Indy Semantics WG* and *Aries Semantics WG* calls on a weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work. Keen to hear everybody's thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to go weekly and alternate between *Indy Semantics WG* and *Aries Semantics WG* calls on a weekly rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work. Keen to hear everybody's thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to go weekly and alternate between *Indy Semantics WG* and *Aries Semantics WG* calls on rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. That might work. Keen to hear everybody's thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to go weekly and alternate between *Indy Semantics WG* and *Aries Semantics WG* calls on rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. Could that work? Keen to hear everybody's thoughts.
pknowles (Thu, 20 Jun 2019 18:01:13 GMT):
@danielhardman - As the Indy Semantics WG calls are bi-weekly, there might be an opportunity to go weekly and alternate between *Indy Semantics WG* and *Aries Semantics WG* calls on rotation. If we were to do that, I would suggest that @kenebert become the new chair of the Indy Semantics WG and I step into a vice role. We could then set up a new Aries Semantics WG which I would happily chair and Ken could step into a vice role for that group. This would enable us to maintain synergy between the two semantics WGs as we progress. Could that work? Keen to hear people's thoughts.
pknowles (Fri, 21 Jun 2019 07:27:47 GMT):
@nage :top:
drummondreed (Sun, 23 Jun 2019 22:36:25 GMT):
@pknowles That makes sense to me. I look at it this way: Indy architecture currently represents one credential format and exchange protocol, the primitives for which are supported on the Indy ledger. Aries is now separating out the P2P DID connection and credential exchange layers so that they can work with any ledger that wants to support them. So I see "Indy credential semantics" slowly converging with "Aries credential semantics", and starting with these two calls is a good way to move along that path.
pknowles (Mon, 24 Jun 2019 16:55:51 GMT):
@mtfk - @phoniks is keen to create a React (Front-end framework) Form Generator for ODCA. Something along the lines of https://react.rocks/tag/FormGenerator . Can you point him to some overlay examples that he can use to template from?
pknowles (Mon, 24 Jun 2019 16:55:51 GMT):
@mtfk ... @phoniks is keen to create a React (Front-end framework) Form Generator for ODCA. Something along the lines of https://react.rocks/tag/FormGenerator . Can you point him to some overlay examples that he can use to template from?
pknowles (Mon, 24 Jun 2019 16:55:51 GMT):
@mtfk ... @phoniks is keen to create a React (Front-end framework) Form Generator for ODCA. Something along the lines of https://react.rocks/tag/FormGenerator . Can you point him to some overlay examples that he can use as templates?
pknowles (Mon, 24 Jun 2019 17:14:05 GMT):
I'll put this down as an agenda item for tomorrow's Indy Semantics WG call. Thanks for your input.
mtfk (Tue, 25 Jun 2019 07:54:52 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=kgppmodjSLyNPtQ22) @phoniks I will prepare new schema base example + overlays this week and share here. I am planning to use similar approach with vue: https://github.com/vue-generators/vue-form-generator for existing project https://github.com/THCLab/tool . Basically the schema base and overlays would have definition file which you can take an use to validate against newly created ones. If you can't wait to start you can take existing examples from https://github.com/THCLab/schema-cake which gives you good start. We need to update this repo with some minor changes but overall it should work for you. If you would have any questions just let me know here.
pknowles (Tue, 25 Jun 2019 15:55:00 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 25th June, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• HIPE review: Contexts for Rich Schema Objects ( @kenebert / @brentzundel ) - 35 mins
[Ref.: https://github.com/hyperledger/indy-hipe/tree/master/text/0138-rich-schema-context ]
• Discussion: Indy Semantics WG vs. Aries Semantics WG ( @pknowles ) - 25 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 25 Jun 2019 18:33:56 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, July 9th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 25 Jun 2019 18:37:37 GMT):
If anyone has any queries regarding the _Contexts for Rich Schema Objects_ HIPE that @kenebert presented in the WG call, please reach out directly to either Ken or @brentzundel . The link to the HIPE - https://github.com/hyperledger/indy-hipe/tree/master/text/0138-rich-schema-context
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV defined attributes in 2 ODCA-constructed schemas, namely: (i.) _Personal Data Processing_ (PDP) schema and (ii.) _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags in section 4 of the spec with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPV spec. https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV defined attributes in 2 ODCA-constructed schemas, namely: (i.) _Personal Data Processing_ (PDP) schema and (ii.) _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags to be implemented into section 4 of the spec with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPV spec. https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV defined attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary spec. https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary spec. https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary specification. It is really great work! https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary specification. It really is marvellous work! https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema [https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ] and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary specification. It really is marvellous work! https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema [https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ] and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary specification. It really is a marvellous piece of work! https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema [https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ] and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 (Personal Data Categories) of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary specification. It really is a marvellous piece of work! https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema [https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb] and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 (Personal Data Categories) of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy]. Here is the link to the DPVCG Vocabulary specification. It really is a marvellous piece of work! https://www.w3.org/ns/dpv
pknowles (Tue, 25 Jun 2019 20:21:17 GMT):
During todays WG call, I mentioned the *DPVCG Vocabulary* specification [W3C: Data Privacy Vocabularies and Controls Community Group] which comes hot off the press. The Dativa Innovation team are looking to use DPV named attributes in 2 ODCA-constructed schemas, namely: (i.) a _Personal Data Processing_ (PDP) schema [https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ] and (ii.) a _Generic Consent_ schema. We're also discussing _personally identifiable information_ (PII) flags which would be implemented into section 4 (Personal Data Categories) of the specification document with reference to the _Blinding Identity Taxonomy_ (BIT) [https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]. Here is the link to the DPVCG Vocabulary specification. It really is a marvellous piece of work! https://www.w3.org/ns/dpv
pknowles (Wed, 26 Jun 2019 13:14:18 GMT):
Harshvardhan "Harsh" Pandit, one of the chief editors of the *DPVCG Vocabulary* specification will be presenting the report to the *Indy Semantics WG* on Tuesday, July 9th.
pknowles (Wed, 26 Jun 2019 13:14:18 GMT):
Harshvardhan "Harsh" Pandit, one of the chief editors of the *DPVCG Vocabulary* specification will be presenting the report during the *Indy Semantics WG* call on Tuesday, July 9th.
pknowles (Wed, 26 Jun 2019 13:14:18 GMT):
Harshvardhan "Harsh" Pandit, chief editor of the *DPVCG Vocabulary* specification, will be presenting the report during the next *Indy Semantics WG* call on Tuesday, July 9th. https://www.w3.org/ns/dpv
pknowles (Wed, 26 Jun 2019 15:49:06 GMT):
Has anybody come across BigID before? If so, any feedback? https://bigid.com
pknowles (Wed, 26 Jun 2019 15:49:06 GMT):
Has anybody come across *BigID* before? If so, any feedback? https://bigid.com
MarcoPasotti (Wed, 26 Jun 2019 16:29:59 GMT):
Has joined the channel.
drummondreed (Wed, 26 Jun 2019 19:18:39 GMT):
Very cool
pknowles (Thu, 04 Jul 2019 04:50:40 GMT):
During the next *Indy Semantics WG* call (Tuesday, July 9th), @janl will be presenting a preliminary demo on *consent lifecycle using Hyperledger Indy*. The demo goes through the automated steps of setting up the ledger, exchange of PDP (personal data processing) requirements, creating a consent receipt certificate, performing a proof that a consent was given and taking down the ledger. Alice, Bob, Acme and Faber are our volunteer actors once again!
pknowles (Thu, 04 Jul 2019 04:50:40 GMT):
During the next *Indy Semantics WG* call (Tuesday, July 9th), @janl will also be presenting a preliminary demo on *consent lifecycle using Hyperledger Indy*. The demo goes through the automated steps of setting up the ledger, exchange of PDP (personal data processing) requirements, creating a consent receipt certificate, performing a proof that a consent was given and taking down the ledger. Alice, Bob, Acme and Faber are our volunteer actors once again!
VipinB (Sun, 07 Jul 2019 15:34:23 GMT):
@pknowles there was a presentation during Identity Working group call on June 12 of the India consent layer by Ajay Jadhav- details available on the IDWG meeting notes. https://wiki.hyperledger.org/display/IWG/2019-06-12-Notes
pknowles (Mon, 08 Jul 2019 09:53:30 GMT):
Thanks, @VipinB . @janl :top:
pknowles (Mon, 08 Jul 2019 09:53:30 GMT):
Thanks, @VipinB . @janl :top: check out the link.
pknowles (Tue, 09 Jul 2019 15:54:25 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 9th July, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• DPVCG Vocabulary specification [Data Privacy Vocabulary] (H. Pandit) - 25 mins
[Ref.: https://www.w3.org/ns/dpv ]
• Demo: Consent lifecycle using Hyperledger Indy ( @janl ) - 30 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 09 Jul 2019 19:47:49 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, July 23rd. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
drummondreed (Thu, 11 Jul 2019 06:51:55 GMT):
@pknowles For those of us who were not able to attend, could you post a few bullets of highlights from the calls?
iamtxena (Fri, 12 Jul 2019 09:01:41 GMT):
Has joined the channel.
VipinB (Fri, 12 Jul 2019 18:56:34 GMT):
I was on the call. Will try to summarize what I remember
1. DPV by Harsh was about Data Protection Vocabulary developed in a w3C community group: https://docs.google.com/presentation/d/1qQIdIxpkPdldS_RR7x8L2ZAq3plse9yd-WxcFZgBjY0/edit#slide=id.gc6f9e470d_0_126```
2. It is expressed in RDF, it is a collection of vocabularies covering multiple dimensions and highly focused on GDPR themes (like data controllers and the like)
3. The dimensions include data subject, purpose (including legal basis), consent, and a host of others (more details in the slides- look at 3,4 etc)
4. Follow on by a demo of consent lifecycle
```
VipinB (Fri, 12 Jul 2019 18:56:34 GMT):
I was on the call. Will try to summarize what I remember
1. DPV by Harsh was about Data Protection Vocabulary developed in a w3C community group: https://docs.google.com/presentation/d/1qQIdIxpkPdldS_RR7x8L2ZAq3plse9yd-WxcFZgBjY0/edit#slide=id.gc6f9e470d_0_126
2. It is expressed in RDF, it is a collection of vocabularies covering multiple dimensions and highly focused on GDPR themes (like data controllers and the like)
3. The dimensions include data subject, purpose (including legal basis), consent, and a host of others (more details in the slides- look at 3,4 etc)
4. Follow on by a demo of consent lifecycle by janl implemented thru Hyperledger Indy.
VipinB (Fri, 12 Jul 2019 18:56:34 GMT):
I was on the call. Will try to summarize what I remember
1. DPV by Harshvardhan was about Data Protection Vocabulary developed in a w3C community group: https://docs.google.com/presentation/d/1qQIdIxpkPdldS_RR7x8L2ZAq3plse9yd-WxcFZgBjY0/edit#slide=id.gc6f9e470d_0_126
2. It is expressed in RDF, it is a collection of vocabularies covering multiple dimensions and highly focused on GDPR themes (like data controllers and the like)
3. The dimensions include data subject, purpose (including legal basis), consent, and a host of others (more details in the slides- look at 3,4 etc)
4. Follow on by a demo of consent lifecycle by janl implemented thru Hyperledger Indy.
5. @janl and Harsh Pandit will collaborate, @janl will normalize the vocabulary and types based on the DPV document
pknowles (Fri, 12 Jul 2019 19:31:56 GMT):
Thanks, @VipinB . Nicely summarised!
drummondreed (Fri, 12 Jul 2019 23:57:57 GMT):
Thanks, @VipinB !
pknowles (Sat, 13 Jul 2019 04:01:03 GMT):
@drummondreed - The call was recorded. https://drive.google.com/drive/u/0/folders/159vc1HsnAsgb8hOh-LFtp8u9spP5iL1I . The DPV talk by Harsh Pandit starts at 4mins. The consent lifecycle demo by @janl starts at 40mins 30secs.
ravip (Sat, 13 Jul 2019 19:40:04 GMT):
Has joined the channel.
ravip (Sat, 13 Jul 2019 19:40:05 GMT):
Hello everyone, is there a way to send some data when sending a proof request?
I mean, let's say a data controller (DC) is asking gov attested address to a data subject (DS) in a proof request and wants to specify the reason for the ask as well. So is it possible to send that data in the form of key value pair in a proof request
ravip (Sat, 13 Jul 2019 19:40:10 GMT):
*request?
ravip (Sat, 13 Jul 2019 19:51:31 GMT):
Also, is there some kind of explorer for microledger between entities wherein a data subject could see what they have consented to and for how long to data controllers?
ravip (Sun, 14 Jul 2019 21:59:04 GMT):
consent-flow
swcurran (Mon, 15 Jul 2019 02:12:44 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=RsKdfHe2hRyXvZFZq) The fun answer is perhaps :-). Technically, yes it can be done. The challenge is that the Holder must know what that extra data is about - why it is there and what to do with it. To achieve interoperability, we are building up versioned protocols that define the interactions between agents indepdently implemented. **There is a current specification for the "Present Proof" process that describes protocol here - https://github.com/hyperledger/aries-rfcs/tree/master/features/0037-present-proof
In theory, you could use the "comment" field for that, but again, the Holder is likely to just display that to the Holder/Prover.
swcurran (Mon, 15 Jul 2019 02:17:41 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=onAgSi6k6u6FZDg5k) The implementation of the "microledger" has evolved to be more of a set of related records in a data store. There is a connection object (the relationship between the entities that swapped pairwise, private DIDs) and there is data collected about the connection. All of that is stored in secured storage ("wallet" in Indy), and can be manipulated by the agent code as necessary. It is not implemented as ledger in the blockchain sense (distributed data store with consensus, etc.). You can look at the code in https://github.com/hyperledger/aries-cloudagent-python for an implementation.
ravip (Mon, 15 Jul 2019 06:37:02 GMT):
Thank you @swcurran for sharing your knowledge and pointers on the topic.
ravip (Mon, 15 Jul 2019 06:45:44 GMT):
I was trying to build a consent application using hyperledget indy and I was thinking how would one implement the process of 'revoking consent'?
I listened to the recorded call and got an idea that granting consent could be implemented interms of Data controller (DC) issuing a Verifiable Credential (VC) to Data Subject (DS) thereby giving a consent receipt to DS, later on a verifier could request a proof from the DS for the same.
But lets say, if DS wants to revoke the consent that he has already provided, then how would that work?
ravip (Mon, 15 Jul 2019 06:54:25 GMT):
Will DC keep on continuously checking if DS has revoked the consent or not and if he has, then invalidate the claim?
jadhavajay (Mon, 15 Jul 2019 13:44:13 GMT):
Has joined the channel.
pknowles (Mon, 15 Jul 2019 14:02:34 GMT):
@ravip , @janl is the man to chat to re consent lifecycle.
pknowles (Mon, 15 Jul 2019 14:02:34 GMT):
Hi @ravip - @janl is the man to chat to re consent lifecycle on HL Indy.
pknowles (Mon, 15 Jul 2019 14:02:34 GMT):
Hi @ravip - @janl is the man to chat to re consent lifecycle using HL Indy.
janl (Mon, 15 Jul 2019 14:19:58 GMT):
Good questions @ravip. You seem to have several, but will answer the revoking consent first. Planned to use the consent receipt certificate revocation. The DS has to inform DC to revoke consent which triggers the revocation by the DC. Due to the fact you cannot trust the DC the DS controls the verification (proof request) from a 3rd party (subDC) and basically make assertions that fail the proof. The verifier may have difficulty to discern a consent revocation since proof is a simple check of assertions. Need to work out how this best can be achieved.
janl (Mon, 15 Jul 2019 14:19:58 GMT):
Good questions @ravip . You seem to have several, but will answer the revoking consent first. Planned to use the consent receipt certificate revocation. The DS has to inform DC to revoke consent which triggers the revocation by the DC. Due to the fact you cannot trust the DC the DS controls the verification (proof request) from a 3rd party (subDC) and basically make assertions that fail the proof. The verifier may have difficulty to discern a consent revocation since proof is a simple check of assertions. Need to work out how this best can be achieved.
troyronda (Tue, 16 Jul 2019 13:25:21 GMT):
@janl do you have plans to create an Aries RFC for consent receipts?
troyronda (Tue, 16 Jul 2019 13:25:21 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, August 6th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
janl (Tue, 16 Jul 2019 13:43:29 GMT):
Correct. The old HIPE will become an Aries RFC. What may not be completely clear is in which form will the RFC look like. Goal is to create a best practices and guidance of how to setup consent receipt.
smithsamuelm (Mon, 22 Jul 2019 21:35:23 GMT):
Has joined the channel.
pknowles (Tue, 23 Jul 2019 16:23:46 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 23rd July, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Novartis pilots utilizing ODCA ( @pknowles ) - 15 mins
• Abbreviated PSCI SAQ & Audit Report Template for Service Providers & General Manufacturers ( @pknowles ) - 15 mins
[Ref.: https://pscinitiative.org/resource?resource=318 ]
• Global Decentralized Data Economy ( @mtfk ) - 15 mins
[Ref.: https://docs.google.com/document/d/19ewSzXM4TUPzj8S9pGMCxBY4CkQxQ1kL1kiOQ6y8ANg/edit?ts=5d322608 ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 23 Jul 2019 19:57:48 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, August 6th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 06 Aug 2019 16:11:48 GMT):
Due to a meeting clash, today's Indy Semantics WG call will be postponed to next Tuesday, August 13th. Apologies for the inconvenience. Look forward to catching up next week. Best. Paul
pknowles (Tue, 13 Aug 2019 16:14:48 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 13th August, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Rich Schema demo ( @kenebert ) - 30 mins
• Update: TPRM project utilizing ODCA [Novartis] ( @pknowles ) - 20 mins
[Ref.: https://pscinitiative.org/resource?resource=318 ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 13 Aug 2019 16:17:04 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 13th August, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Rich Schema demo ( @kenebert ) - 30 mins
• Update: TPRM project utilizing ODCA [Novartis] ( @pknowles ) - 20 mins
[Ref.: https://pscinitiative.org/resource?resource=318 ]
• Update: Consent Lifecycle RFC ( @janl ) - 10 mins
[Ref.: https://github.com/hyperledger/indy-hipe/pull/55 ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 13 Aug 2019 16:17:04 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 13th August, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Rich Schema demo ( @kenebert ) - 30 mins
• Update: TPRM project utilizing ODCA [Novartis] ( @pknowles ) - 20 mins
[Ref.: https://pscinitiative.org/resource?resource=318 ]
• Update: Consent Lifecycle RFC ( @janl ) - 10 mins
[Ref.: https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 13 Aug 2019 16:17:04 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 13th August, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Rich Schema demo ( @kenebert ) - 30 mins
• Update: TPRM project utilizing ODCA [Novartis] ( @pknowles ) - 20 mins
[Ref.: https://pscinitiative.org/resource?resource=318 ]
• Update: Data Consent Lifecycle RFC ( @janl ) - 10 mins
[Ref.: https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 20 Aug 2019 09:04:31 GMT):
The agenda, video, notes, etc. from last week's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be today at 11am MT / 7pm CET. Agenda to follow. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 20 Aug 2019 15:51:07 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 20th August, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Semantics-related RFC update: Data Consent Lifecycle RFC ( @janl ) - 10 mins
[Ref.: https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md ]
• Personal Data Processing (PDP) schema in ODCA format ( @pknowles ) - 15 mins
[Ref.: https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ]
• Open discussion on pending/upcoming projects - 25 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 20 Aug 2019 15:51:07 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 20th August, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Semantics-related RFC updates: Data Consent Lifecycle RFC ( @janl ) - 10 mins
[Ref.: https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md ]
• Personal Data Processing (PDP) schema in ODCA format ( @pknowles ) - 15 mins
[Ref.: https://drive.google.com/drive/u/0/folders/1FFU47tCTu7XbNnpD2oZlbgglrKiTh5yb ]
• Open discussion on pending/upcoming projects or events - 25 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 20 Aug 2019 18:57:03 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, September 3rd. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 03 Sep 2019 16:11:02 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 3rd September, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Schema Bases, PII flagging and a proposed Masking Overlay ( @janl / @pknowles ) - 10 mins
[Ref.: https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]
• ODCA: What has been built so far? ( @mtfk ) - 15 mins
[Ref.: https://github.com/THCLab/schema-cake ]
• Hashlinks for ODCA: A discussion with Manu Sporny ( @mtfk ) - 10 mins
• Sitra Service WG ( @mtfk ) - 10 mins
[Ref. https://www.sitra.fi/en/ ]
• Vienna Identify meetup ( @mtfk ) - 10 mins
[Ref. https://www.meetup.com/Vienna-Digital-Identity-Meetup/events/262359964/ ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 03 Sep 2019 16:11:02 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 3rd September, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Schema Bases, PII flagging and a proposed Masking Overlay ( @janl / @pknowles ) - 10 mins
[Ref.: https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy ]
• ODCA: What has been built so far? ( @mtfk ) - 15 mins
[Ref.: https://github.com/THCLab/schema-cake ]
• Hashlinks for ODCA: A discussion with Manu Sporny ( @mtfk ) - 10 mins
[Ref.: https://tools.ietf.org/html/draft-sporny-hashlink-00 ]
• Sitra Service WG ( @mtfk ) - 10 mins
[Ref. https://www.sitra.fi/en/ ]
• Vienna Digital Identify meetup ( @mtfk ) - 10 mins
[Ref. https://www.meetup.com/Vienna-Digital-Identity-Meetup/events/262359964/ ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Wed, 04 Sep 2019 05:09:47 GMT):
The agenda, video, notes, etc. from yesterday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, September 17th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Mon, 16 Sep 2019 14:36:48 GMT):
There are a number of Hyperledger Indy/Aries community members attending the MyData conference in Helsinki next week. If anyone in this community will be presenting at the conference and would like to do a trial run to a familiar audience, we can accommodate two 15 minute presentations during tomorrow's HL Indy Semantics WG call. DM me if you would like to reserve one of those presentation slots.
pknowles (Mon, 16 Sep 2019 14:36:48 GMT):
There are a number of Hyperledger Indy/Aries community members attending the MyData conference in Helsinki next week. If anyone in this community will be presenting at the conference and would like to do a trial run to a familiar audience, we can accommodate two 15 minute presentations during tomorrow's HL Indy Semantics WG call. DM me if you would like to reserve one of those slots.
pknowles (Mon, 16 Sep 2019 14:36:48 GMT):
There are a number of Hyperledger Indy/Aries community members attending the MyData conference in Helsinki next week. If anyone in this community will be presenting at the conference and would like to try it out on a familiar audience, we can accommodate two 15 minute presentations during tomorrow's HL Indy Semantics WG call. DM me if you would like to reserve one of those slots.
pknowles (Mon, 16 Sep 2019 14:36:48 GMT):
There are a number of Hyperledger Indy/Aries community members attending the MyData conference in Helsinki next week. If anyone in this community will be presenting at the conference and would like to try it out on a familiar audience beforehand, we can accommodate two 15 minute presentations during tomorrow's HL Indy Semantics WG call. DM me if you would like to reserve a slot.
pknowles (Tue, 17 Sep 2019 16:17:02 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 17th September, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• DNS over HTTPS ( @mtfk ) - 10 mins
[Ref.: https://www.eff.org/deeplinks/2019/09/encrypted-dns-could-help-close-biggest-privacy-gap-internet-why-are-some-groups ]
• Machine-readable ODCA specification ( @pknowles ) - 10 mins
• Overlay metadata attributes: Discuss ( @mtfk ) - 10 mins
• MyData 2019 ( @pknowles ) - 10 mins
[Ref. https://mydata2019.org ]
• Internet Identity Workshop [IIW] ( @pknowles ) - 10 mins
[Ref. https://internetidentityworkshop.com ]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Wed, 18 Sep 2019 01:30:59 GMT):
The agenda, video, notes, etc. from yesterday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, October 1st. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
mwherman2000 (Wed, 18 Sep 2019 02:21:43 GMT):
Hi guys, it's purely by accident that I dropped in to watch today recording. Thank you @pknowles for noting the article on DNS. My particular interest is that I've built a Universal DID Server based entirely on DNS procotols and structures using the DnsServer open source project as a basis. It's working and working very well ...still early but it's working. Here's a screenshot....
mwherman2000 (Wed, 18 Sep 2019 02:21:43 GMT):
Hi guys, it's purely by accident that I dropped in to watch today's recording. Thank you @pknowles for noting the article on DNS. My particular interest is that I've built a Universal DID Server based entirely on DNS procotols and structures using the DnsServer open source project as a basis. It's working and working very well ...still early but it's working. Here's a screenshot....
mwherman2000 (Wed, 18 Sep 2019 02:22:17 GMT):
Clipboard - September 17, 2019 8:22 PM
mwherman2000 (Wed, 18 Sep 2019 02:24:12 GMT):
The `Name` column is the Subject's DID in the `did:neonation` DID method space.
mwherman2000 (Wed, 18 Sep 2019 02:24:43 GMT):
It's very cool.
mwherman2000 (Wed, 18 Sep 2019 02:27:54 GMT):
Here's a sample Universal DID Document ...which leverages the DNS over HTTPS proctocol...
mwherman2000 (Wed, 18 Sep 2019 02:28:01 GMT):
Clipboard - September 17, 2019 8:27 PM
pknowles (Wed, 18 Sep 2019 15:34:21 GMT):
@mwherman2000 Do you fancy running through a Universal DID Server demo during the next HL Indy Semantics call on Oct.1st?
mwherman2000 (Wed, 18 Sep 2019 15:41:04 GMT):
Oct. 15 or 116th would be better Paul
pknowles (Wed, 18 Sep 2019 15:43:01 GMT):
Oct.15th. Noted.
mwherman2000 (Thu, 19 Sep 2019 00:13:24 GMT):
Note: https://github.com/TechnitiumSoftware/DnsServer/issues/87
Alexi (Tue, 24 Sep 2019 16:58:00 GMT):
Has joined the channel.
drummondreed (Wed, 25 Sep 2019 12:17:00 GMT):
Guardianship Task Force white paper draft—please review if you are able as we will be using this to hold a session at Internet Identity Workshop next week: https://docs.google.com/document/d/1d1I3f4sBlc9nLt_TAtsXvi-EKSzECaQObKZPL0Zx_9U/edit?usp=sharing
janl (Sun, 29 Sep 2019 16:17:53 GMT):
Interesting read. Would this be a special form of consent? For example a court may assign guardianship to an individual. This would be down by having the court "consent" to a guardian to represent the individual.
janl (Mon, 30 Sep 2019 21:02:32 GMT):
Hi,
I have an update to my rfc: 167, data consent lifecycle, which may be of general interest. I have given several demos of how indy-sdk can be used can used for creating consent receipt and performing proof request without revealing any private information. The demo is based on getting-started and is now available as a reference implementation for anybody to check out. Once Aries is ready the plan is to adapt it over. The next step for the reference implementation is to add revocation example which is on the works. Welcome to come with feedback.
https://github.com/JanLin/aries-rfcs/tree/master/concepts/0167-data-consent-lifecycle
Best regards,
Jan
Note the new reference implementation is in a Pull Request #238 to hyperledger:master.
pknowles (Tue, 01 Oct 2019 11:28:49 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 19th February, 2019
Time:
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Attendee register:
https://docs.google.com/document/d/1ayXu4JLznvi1-qM0mRRN24EPuAWpAeV4f1f6DqSKG5c/edit
Agenda:
• Introductions (Open) - 5 mins
• Aries RFC 0167: Data Consent Lifecycle - Status update with reference implementation ( @janl ) - 10 mins
- Reference: https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
• Proposed white paper: “Decentralized Identity for Human Beings” - Creating a blue print for the building blocks of a human-centric data economy ( @pknowles ) - 10 mins
• New global ontologies required to fulfil the promise of a decentralized data economy ( @pknowles ) - 10 mins
• Novartis TPRM project update ( @pknowles ) - 10 mins
• MyData 2019 summary ( @pknowles / @mtfk ) - 10 mins
- Reference: https://mydata2019.org
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 01 Oct 2019 22:58:25 GMT):
The agenda, video, notes, etc. from yesterday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, October 15th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
PaulA (Tue, 08 Oct 2019 16:12:06 GMT):
Has joined the channel.
pknowles (Wed, 09 Oct 2019 21:49:43 GMT):
The Blinding Identity Taxonomy (BIT) is a list of 47 elements that could potentially unblind the identity of an organisation, a person or a thing. https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
A 48th element will soon be added to the BIT ... "Link Secrets"
*Link Secret*
An item of Private Data used by a Prover to link a Credential uniquely to the Prover. A Link Secret is an input to Zero Knowledge Proofs that enables Claims from one or more Credentials to be combined in order to prove that the Credentials have a common Holder (the Prover). A Link Secret should be known only to the Prover.
pknowles (Tue, 15 Oct 2019 16:27:57 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 15th October, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm BST
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Demo: Universal DID Server ( @mwherman2000 ) - 30 mins
[Ref.: https://github.com/TechnitiumSoftware/DnsServer/issues/87 ]
• Use case: (DMV) Division of Motor Vehicles integration into decentralized identity blockchain ( @wksantiago ) - 15 mins
• Novartis TPRM update ( @pknowles ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
wksantiago (Tue, 15 Oct 2019 16:27:57 GMT):
Has joined the channel.
pknowles (Wed, 16 Oct 2019 02:22:51 GMT):
The agenda, video, notes, etc. from yesterday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, October 29th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
yunho.chung (Wed, 16 Oct 2019 08:03:34 GMT):
Has joined the channel.
mwherman2000 (Wed, 16 Oct 2019 11:35:00 GMT):
My apologies for missing the call yesterday.
pknowles (Wed, 16 Oct 2019 11:38:33 GMT):
@mwherman2000 No stress. Happy to schedule in the demo for October 29th. Let me know if that suits.
mwherman2000 (Wed, 16 Oct 2019 11:40:25 GMT):
Yes, please
VipinB (Wed, 16 Oct 2019 20:48:51 GMT):
From Identity Working Group presentation by @janl
Notes have been updated see https://wiki.hyperledger.org/display/IWG/2019-10-16 for details
Notes:
Jan Linquist gave a teaser on the RFC Consent in Hyperledger Aries .
The paper consists of :
An ontology - terms that are relevant and objects that are built up from these terms
Legal compliance standards
How can DID based systems implement a consent lifecyle
A reference implementation of a lifecycle
Consent certificate + proof
Process Flow
Jan says the paper should be properly called the enforcement of a Privacy Agreement
We spoke briefly of the following hard problems
Hierarchy of sharing (what if the original relying party (RP) sells or shares the information to another party) and so on?
Selective disclosure, granularity and quality of information shared (derived information like age boundary-i.e. older than x, younger than y from birthday)
Meta data harvesting (IP addresses, location) and creating correlations
Bankruptcy and delegation of control of privacy proof
Forgetting: what sort of regulation should control this
Common themes and ideas around sovereign or multi-state regulations (like GDPR, India Consent Layer, CCA, New York state privacy, Chinese regulation on consent) and how to implement them, are there patterns code snippets libraries
Some techniques proposed on the Semantics call
Adding masking layers for psuedonimisation
Metadata turns up as machine readable quasi-identifiers- what to do about this
Jan agreed to do a demo of the reference lifecycle in a future meeting- we will publicize this and hopefully we will have greater participation.
ajayjadhav (Fri, 18 Oct 2019 13:36:46 GMT):
Has joined the channel.
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB : Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and main seed behind Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development on Hyperledger.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework. The following interview explains what a "consent receipt" is and why is it important? Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB : Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and main seed behind Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development on Hyperledger.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and the main contributor of Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development on Hyperledger.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and the main contributor of Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development on Hyperledger. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor of Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development on Hyperledger. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor of Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development using Hyperledger. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor of Kantara's Consent Receipt Specification, and Harsh Pandit, the main contributing author of the Data Privacy Vocabulary, on consent development using Hyperledger Aries. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why is it important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
You can read more about the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
You can read more about a recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework via the following link. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
Check out the following press announcement re a collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
Check out the following press announcement regarding the recent collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary, on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
Check out the following press announcement regarding a collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary (DPV), on consent development implementation using Hyperledger Aries. Jan is leading that initiative.
Check out the following press announcement regarding a collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary (DPV) -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:33:41 GMT):
@janl @VipinB Jan and I continue to work closely with Mark Lizar, CEO at OpenConsent and seed contributor to Kantara's Consent Receipt Specification, and Harsh Pandit, main contributing author of the Data Privacy Vocabulary (DPV), on consent development using Hyperledger Aries. Jan is leading that initiative.
Check out the following press announcement regarding a collaboration agreement between Financial Data Exchange (FDX) and Kantara on an Open Banking consent receipt framework. The interview explains what a "consent receipt" is and why it is important. Kantara's Colin Wallis and FDX's Don Cardinal explain. https://financialdataexchange.org/blogs/fdx-blog/interview-fdx-s-don-cardinal-and-kantara-s-colin-wallace-talk-about-recent-collaborating-agreement
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary (DPV) -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
pknowles (Tue, 22 Oct 2019 23:38:49 GMT):
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
pknowles (Tue, 22 Oct 2019 23:38:49 GMT):
Related links ...
(i.) Kantara's Consent Receipt Specification -
https://kantarainitiative.org/confluence/display/infosharing/Consent+Receipt+Specification
(ii.) Data Privacy Vocabulary -
https://www.w3.org/ns/dpv/
(iii.) Data Consent Lifecycle RFC (Hyperledger Aries) -
https://github.com/hyperledger/aries-rfcs/blob/master/concepts/0167-data-consent-lifecycle/README.md
Rick (Thu, 24 Oct 2019 13:47:26 GMT):
Has joined the channel.
Rick (Thu, 24 Oct 2019 13:48:48 GMT):
proof
VipinB (Thu, 24 Oct 2019 15:45:38 GMT):
Great list- we might take up some of this in IDWG (there is a call to name this Identity TSIG (Technical Special Interest Group))
pknowles (Fri, 25 Oct 2019 02:44:06 GMT):
CredDef-ODCA.pdf
pknowles (Fri, 25 Oct 2019 02:44:06 GMT):
CredDef-ODCA.pdf
pknowles (Fri, 25 Oct 2019 02:47:02 GMT):
Credential Definitions (ODCA format) to discuss. @brentzundel @kenebert @mtfk
pknowles (Fri, 25 Oct 2019 02:47:02 GMT):
Credential Definitions (ODCA format) to discuss. @brentzundel @kenebert @mtfk @danielhardman
pknowles (Fri, 25 Oct 2019 02:47:02 GMT):
Credential Definitions (ODCA format). To discuss on the next *Indy Semantics WG* call . @brentzundel @kenebert @mtfk @danielhardman
pknowles (Fri, 25 Oct 2019 02:47:20 GMT):
CredDef-ODCA.pdf
pknowles (Fri, 25 Oct 2019 03:02:06 GMT):
CredDef-ODCA.pdf
pknowles (Fri, 25 Oct 2019 03:04:23 GMT):
CredDef-ODCA.pdf
pknowles (Fri, 25 Oct 2019 03:49:52 GMT):
CredDef-ODCA.pdf
pknowles (Fri, 25 Oct 2019 04:35:10 GMT):
CredDef-ODCA.pdf
mtfk (Fri, 25 Oct 2019 06:33:24 GMT):
Can we have links to the current state of the art for credential definition? Maybe @kenebert you could provide some links. So we can take a look.
pknowles (Fri, 25 Oct 2019 14:07:03 GMT):
@mtfk I believe this is the best place for the CredDef implementation work. @kenebert can correct me if I'm wrong! https://drive.google.com/drive/u/0/folders/1WDIP8t829XhBX2hq-9xBN8u2IG5k5TCO
jonathanreynolds (Fri, 25 Oct 2019 14:41:30 GMT):
have a look at https://sovrin.org/wp-content/uploads/2019/03/What-if-someone-steals-my-phone-040319.pdf
jonathanreynolds (Fri, 25 Oct 2019 14:41:58 GMT):
Have a look at https://sovrin.org/wp-content/uploads/2019/03/What-if-someone-steals-my-phone-040319.pdf
jonathanreynolds (Fri, 25 Oct 2019 14:42:42 GMT):
The definition here is around it being secret in a privacy sense rather than a security sense.
pknowles (Fri, 25 Oct 2019 20:32:31 GMT):
Can you identify someone from a Link Secret? If not, it doesn't need to go on the Blinding Identity Taxonomy. If you can, w
pknowles (Fri, 25 Oct 2019 20:32:31 GMT):
Can you identify someone from a Link Secret? If not, it doesn't need to go on the Blinding Identity Taxonomy. If it can, we should add it. What do you think?
pknowles (Fri, 25 Oct 2019 20:32:31 GMT):
Can you identify someone from a _Link Secret_? If not, it doesn't need to go on the Blinding Identity Taxonomy (BIT). If it can, then we should add it. What do you reckon?
jonathanreynolds (Sat, 26 Oct 2019 12:11:33 GMT):
that is probably a question for someone from Sovrin/Evernym but from that doc i linked it seems that if it is compromised then you will be at risk of correlation but not of identity theft
pknowles (Sat, 26 Oct 2019 12:46:25 GMT):
Thanks, Jonathan. I appreciate your input. I think we should add it to the BIT as it sounds like the element should always be encrypted if it were to fall outside of its intended verification purpose. From a data capture perspective, I would always flag it as sensitive and the BIT is a reference document for safe data capture. @danielhardman @MALodder
pknowles (Sat, 26 Oct 2019 12:46:25 GMT):
Thanks, Jonathan. I appreciate your input. I think we should add it to the BIT as it sounds like the element should always be encrypted if it were to fall outside of its intended verification purpose. From a data capture perspective, I'd advocate to flag it as sensitive and the BIT is a reference document for safe data capture. @danielhardman @MALodder
pknowles (Sat, 26 Oct 2019 12:46:25 GMT):
Thanks, Jonathan. I appreciate your input. I think we should add it to the BIT as it sounds like the element should always be encrypted if it were to fall outside of its intended verification purpose. The BIT is a reference document for safe data capture. From that perspective, I'd advocate to flag _Link Secrets_ as sensitive and therefore include it in the taxonomy. @danielhardman @MALodder
pknowles (Sat, 26 Oct 2019 12:46:25 GMT):
Thanks, Jonathan. I appreciate your input. I think we should add it to the BIT as it sounds like the element should always be encrypted if it were to fall outside of its intended verification purpose. The BIT is a reference document for safe data capture. From that perspective, I'd advocate flagging _Link Secrets_ as sensitive and therefore including that element in the taxonomy. @danielhardman @MALodder
pknowles (Sat, 26 Oct 2019 12:46:25 GMT):
Thanks, Jonathan. I appreciate your input. I think we should add it to the BIT as it sounds like the element should always be encrypted if it were to fall outside of its intended verification purpose. The BIT is a reference document for safe data capture. From that perspective, I'd advocate flagging _Link Secrets_ as sensitive and including that element in the taxonomy. @danielhardman @MALodder
pknowles (Sat, 26 Oct 2019 12:46:25 GMT):
Thanks, Jonathan. I appreciate your input. I think we should add it to the BIT as it sounds like the element should always be encrypted if it were to fall outside of its intended verification purpose. The BIT is a reference document for safe data capture. From that perspective, I'd advocate flagging _Link Secrets_ as sensitive and including it in the taxonomy. @danielhardman @MALodder
jonathanreynolds (Sat, 26 Oct 2019 13:51:11 GMT):
seems like a good call
mwherman2000 (Mon, 28 Oct 2019 00:02:51 GMT):
Before we get too excited about Tuesday, I'm going to have to push y Universal DID Data Service talk out 2 more weeks ...until after I get back from the Malta Blockchain Summit.
pknowles (Mon, 28 Oct 2019 07:50:59 GMT):
No problem, @mwherman2000 . That actually helps me. The agenda is ge
pknowles (Mon, 28 Oct 2019 07:50:59 GMT):
No problem, @mwherman2000 . That actually helps me. The agenda is quite full this week.
pknowles (Mon, 28 Oct 2019 07:50:59 GMT):
No problem, @mwherman2000 . That actually helps me. The agenda is quite full this week already.
pknowles (Tue, 29 Oct 2019 16:38:47 GMT):
Due to the clocks changing in Europe, please note that today's *HL Indy Semantics WG* call will start at 7pm CET / 12pm MT
pknowles (Tue, 29 Oct 2019 16:38:47 GMT):
Due to the clocks changing in Europe, please note that today's *Indy Semantics WG* call will start at 7pm CET / 12pm MT
pknowles (Tue, 29 Oct 2019 17:08:08 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 29th October, 2019
11am-12.15pm PT
12pm-1.15pm MT
1pm-2.15pm CT
2pm-3.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: IHAN Blueprint work for facilitating fair data economy (consents) ( C. Ahlin ) - 10 mins
[Ref.: https://media.sitra.fi/2019/04/09132843/a-roadmap-for-a-fair-data-economy.pdf ]
• Use case: (DMV) Division of Motor Vehicles integration into decentralized identity blockchain ( @wksantiago ) - 15 mins
• Discussion: CredDef structures in ODCA format ( @pknowles ) - 20 mins
• Discussion: Expected content structure within a CredDef ( @mtfk ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 29 Oct 2019 20:50:35 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, November 12th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
VipinB (Wed, 30 Oct 2019 14:20:53 GMT):
@janl There were some questions from the impromptu talk you gave last week from Randy Zhang from cisco which you may not have seen if you are not on the mailing list. I quote the email below...
"Thanks for sharing Vipin/Jan.
Questions:
Are there provisions to perform real-time id attestation (proofing in your chart)?
On the expiration of access, is the attribute or id removed from the database or just the access is revoked? I think there should be hierarchical RBAC for every ID attribute attribute with automatic revoking plus user allowed revoking timer. The ID owner has complete control over all the ID attributes that are inherent with the user (internal ID attributes).
"
Randy
VipinB (Wed, 30 Oct 2019 14:27:52 GMT):
@pknowles was not able to attend yesterday's meeting- I will read the agenda notes etc. to get a better idea of what was talked about. I have two points to add:
1. We need to talk about consent (especially telling is the backtracking of gitlab about the collection of telemetry data)
2. A reframing of the question of "data protection" by Elizabeth Reneiris on medium- I respect Elizabeth's viewpoint- please read and let me know what you think. https://medium.com/berkman-klein-center/distracted-by-data-dbe40033591c Going back to the basics helps sometimes
pknowles (Wed, 30 Oct 2019 14:49:02 GMT):
@janl :top:
pknowles (Wed, 30 Oct 2019 14:56:25 GMT):
Thanks, @VipinB . I respect Elizabeth's opinions so I look forward to reading the article. From my perspective, the link between trusted source and data sharing is vital for a healthy flow of information. The trick is not to become a prisoner of our personal data. Data sharing is absolutely vital so we're looking for the perfect blend of data flagging and subsequent encryption alongside SSI (decentralised identity). If any of those mechanisms are flawed, the model for a secure decentralised data economy breaks. ODCA is hugely powerful from the data capture perspective. SSI is hugely powerful from an identity perspective. We are working on bringing harmony between those two essential cogs.
janl (Wed, 30 Oct 2019 16:04:53 GMT):
@VipinB Let me see if I can answer the question from Randy. Expiration relates to when the service ends. The attribute limitation indicates how long the data will be kept. In case of forget I would say a new consent receipt is created that supersedes the previous consent with limitation set to 0. A technique of pseudynomization is mentioned the association between ID and data is removed when forgetting.
Hope this gives some ideas. They are welcome to comment in semantic mailing list or attend one of the WG calls.
VipinB (Wed, 30 Oct 2019 18:26:00 GMT):
@janl we talked about consent today at the IDWG call. The India consent layer came up again and @nitin.agarwal will give a presentation on this architecture at a later date. I would like to possibly unify the ideas around this topic and address in a short form in the Identity paper.
nitin.agarwal (Wed, 30 Oct 2019 18:26:00 GMT):
Has joined the channel.
pknowles (Thu, 31 Oct 2019 02:55:55 GMT):
In her article, Elizabeth focuses on:
(i.) data as a distraction from real human engagement; and
(ii.) an acknowledgement that we are facing data governance challenges.
Re the first point, I agree that society is becoming less engaged on a very human level but I blame _technology_ rather than _data_. I myself am guilty of using technology as a distancing tool!
Re the second point, I totally agree. However, as I've delved deeper into the development of data semantics through my ODCA work, I'm convinced that the large majority of people don't fully understand the power of a well-conceived semantic architecture for data capture. The semantics gurus are now starting to discuss overlays to deal with data watermarking, data quality, masking and data as currency. I'm not saying that all of these concepts will stick but I am saying that ODCA changes the current data landscape and, in particular, data governance possibilities.
pknowles (Thu, 31 Oct 2019 02:55:55 GMT):
In her article, Elizabeth focuses on:
(i.) data as a distraction from real human engagement and
(ii.) an acknowledgement that we are facing data governance challenges.
Re the first point, I agree that society is becoming less engaged on a very human level but I blame _technology_ rather than _data_. I myself am guilty of using technology as a distancing tool!
Re the second point, I totally agree. However, as I've delved deeper into the development of data semantics through my ODCA work, I'm convinced that the large majority of people don't fully understand the power of a well-conceived semantic architecture for data capture. The semantics gurus are now starting to discuss overlays to deal with data watermarking, data quality, masking and data as currency. I'm not saying that all of these concepts will stick but I am saying that ODCA changes the current data landscape and, in particular, data governance possibilities.
pknowles (Thu, 31 Oct 2019 02:55:55 GMT):
In her article, Elizabeth focuses on:
(i.) data as a distraction from real human engagement; and
(ii.) an acknowledgement that we are facing data governance challenges.
Re the first point, I agree that society is becoming less engaged on a very human level but I blame _technology_ rather than _data_. I myself am guilty of using technology as a distancing tool!
Re the second point, I totally agree. However, as I've delved deeper into the development of data semantics through my ODCA work, I'm convinced that the large majority of people don't fully understand the power of a well-conceived semantic architecture for data capture. The semantics gurus are now starting to discuss overlays to deal with data watermarking, data quality, masking and data as currency. I'm not saying that all of these concepts will stick but I am saying that ODCA changes the current data landscape and, in particular, data governance possibilities.
pknowles (Thu, 31 Oct 2019 02:55:55 GMT):
In her article, Elizabeth focuses on:
(i.) data as a distraction from real human engagement; and
(ii.) an acknowledgement that we are facing data governance challenges.
Re the first point, I agree that society is becoming less engaged on a very human level but I blame _technology_ rather than _data_. I myself am guilty of using technology as a distancing tool!
Re the second point, I totally agree. However, as I've delved deeper into the development of data semantics through my ODCA work, I'm convinced that the large majority of people don't fully understand the power of a well-conceived semantics architecture for data capture. The semantics gurus are now starting to discuss overlays to deal with data watermarking, data quality, masking and data as currency. I'm not saying that all of these concepts will stick but I am saying that ODCA changes the current data landscape and, in particular, data governance possibilities.
pknowles (Thu, 31 Oct 2019 02:55:55 GMT):
In her article, Elizabeth focuses on:
(i.) data as a distraction from real human engagement; and
(ii.) an acknowledgement that we are facing data governance challenges.
Re the first point, I agree that society is becoming less engaged on a very human level but I blame _technology_ rather than _data_. I myself am guilty of using technology as a distancing tool!
Re the second point, I totally agree. However, as I've delved deeper into the development of data semantics through my ODCA work, I'm convinced that the large majority of people don't fully understand the power of a well-designed semantics architecture for data capture and exchange. The semantics gurus in the open source community are now starting to discuss overlays to deal with data watermarking, data quality, masking and data as currency. I'm not saying that all of these concepts will stick but I am saying that ODCA changes the current data landscape and, in particular, data governance possibilities.
pknowles (Thu, 31 Oct 2019 02:55:55 GMT):
In her article, Elizabeth focuses on:
(i.) data as a distraction from real human engagement; and
(ii.) an acknowledgement that we are facing data governance challenges.
Re the first point, I agree that society is becoming less engaged on a very human level but I blame _technology_ rather than _data_. I myself am guilty of using technology as a distancing tool!
Re the second point, I totally agree. However, as I've delved deeper into the development of data semantics through my ODCA work, I'm convinced that the large majority of people don't fully understand the power of a well-designed semantics architecture for data capture and exchange. The semantics gurus in the open source community are now starting to discuss overlays to deal with data watermarking, data quality, masking and data as currency. I'm not saying that all of these concepts will stick but I am saying that ODCA changes the current landscape and, in particular, data governance possibilities.
VipinB (Thu, 31 Oct 2019 15:14:39 GMT):
Another view on this could be that "privacy" is the goal and "data governance" is the means. Focusing on the goal as an abstraction does not get you anywhere; however getting deep into the data governance aspect may not result in attaining the goal either. Unlike a "goal", privacy is a continuing concern as you noted.
pknowles (Fri, 01 Nov 2019 01:32:55 GMT):
Done. https://kantarainitiative.org/confluence/display/infosharing/Blinding+Identity+Taxonomy
pknowles (Tue, 05 Nov 2019 18:12:15 GMT):
Re the Blinding Identity Taxonomy, it would be good to get some community input on the following potential addition ... "Product Identifier". For example, if I come into some rich data re Maxidex, a drug manufactured by Novartis, I might be able to determine the identity of the company who published the data. However, Novartis might wish for 3rd parties to have access to that data without the identity of the company being revealed.
The BIT is supposed to protect the identity of organisations, people and things.
In my example, Maxidex is the pharmaceutical "tradename". Dexamethasone is the active ingredient. I would suggest that Maxidex is PII, Dexamethasone is not.
Maxidex is really supposed to be covered by ...
"Names (incl. First Names, Last Names, Full Names, Entity Names)"
... perhaps we should include "Product Names" in that inclusion list.
"Product Identifier" would be a new element on the list.
All thoughts welcome!
pknowles (Tue, 05 Nov 2019 18:12:15 GMT):
Re the *Blinding Identity Taxonomy*, it would be good to get some community input on the following potential addition ... "Product Identifier". For example, if I come into some rich data re Maxidex, a drug manufactured by Novartis, I might be able to determine the identity of the company who published the data. However, Novartis might wish for 3rd parties to have access to that data without the identity of the company being revealed.
The BIT is supposed to protect the identity of organisations, people and things.
In my example, Maxidex is the pharmaceutical "tradename". Dexamethasone is the active ingredient. I would suggest that Maxidex is PII, Dexamethasone is not.
Maxidex is really supposed to be covered by ...
"Names (incl. First Names, Last Names, Full Names, Entity Names)"
... perhaps we should include "Product Names" in that inclusion list.
"Product Identifier" would be a new element on the list.
All thoughts welcome!
pknowles (Tue, 05 Nov 2019 18:12:15 GMT):
Re the *Blinding Identity Taxonomy*, it would be good to get some community input on the following potential addition ... "Product Identifier". For example, if I were to come into some rich data re Maxidex, a drug manufactured by Novartis, I might be able to determine the identity of the company who published the data. However, Novartis might wish for 3rd parties to have access to that data without the identity of the company being revealed.
The BIT is supposed to protect the identity of organisations, people and things.
In my example, Maxidex is the pharmaceutical "tradename". Dexamethasone is the active ingredient. I would suggest that Maxidex is PII, Dexamethasone is not.
Maxidex is really supposed to be covered by ...
"Names (incl. First Names, Last Names, Full Names, Entity Names)"
... perhaps we should include "Product Names" in that inclusion list.
"Product Identifier" would be a new element on the list.
All thoughts welcome!
pknowles (Tue, 05 Nov 2019 18:12:15 GMT):
Re the *Blinding Identity Taxonomy*, it would be good to get some community input on the following potential addition ... "Product Identifier". For example, if I were to come into some rich data re Maxidex, a drug manufactured by Novartis, I might be able to determine the identity of the company who published the data. However, Novartis might wish for 3rd parties to have access to that data without the identity of the company being revealed.
The BIT is supposed to protect the identity of organisations, people and things.
In my example, Maxidex is the pharmaceutical trade name of the drug. Dexamethasone is the active ingredient. I would suggest that Maxidex is PII, Dexamethasone is not.
Maxidex is really supposed to be covered by ...
"Names (incl. First Names, Last Names, Full Names, Entity Names)"
... perhaps we should include "Product Names" in that inclusion list.
"Product Identifier" would be a new element on the list.
All thoughts welcome!
pknowles (Tue, 05 Nov 2019 18:12:15 GMT):
Re the *Blinding Identity Taxonomy*, it would be good to get some community input on the following potential addition ... "Product Identifier". For example, if I were to come into some rich data re Maxidex, a drug manufactured by Novartis, I might be able to determine the identity of the company who published the data. However, Novartis might wish for 3rd parties to have access to that data without the identity of the company being revealed.
The BIT is supposed to protect the identity of organisations, people and things.
In my example, Maxidex is the pharmaceutical trade name of the drug. Dexamethasone is the active ingredient. I would suggest that Maxidex is PII, Dexamethasone is not.
Maxidex is really supposed to be covered by ...
"Names (incl. First Names, Last Names, Full Names, Entity Names)"
... perhaps we should include "Product Names" in that inclusion list.
"Product Identifier" would be a new element on the list.
Does anyone have a strong opinion on this? All thoughts and deliberations welcome!
pknowles (Tue, 05 Nov 2019 18:12:15 GMT):
Re the *Blinding Identity Taxonomy*, it would be good to get some community input on the following potential addition ... "Product Identifier".
For example, if I were to come into some rich data re Maxidex, a drug manufactured by Novartis, I might be able to determine the identity of the company who published the data. However, Novartis might wish for 3rd parties to have access to that data without the identity of the company being revealed.
The BIT is supposed to protect the identity of organisations, people and things.
In my example, Maxidex is the pharmaceutical trade name of the drug. Dexamethasone is the active ingredient. I would suggest that Maxidex is PII, Dexamethasone is not.
Maxidex is really supposed to be covered by ...
"Names (incl. First Names, Last Names, Full Names, Entity Names)"
... perhaps we should include "Product Names" in that inclusion list.
"Product Identifier" would be a new element on the list.
Does anyone have a strong opinion on this? All thoughts and deliberations welcome!
pknowles (Tue, 05 Nov 2019 23:16:03 GMT):
After feedback from a few key privacy experts, we have decided to not include _product identifiers_ in the taxonomy. Thanks @janl & @TomWeiss for your valuable input.
pknowles (Tue, 05 Nov 2019 23:16:03 GMT):
After feedback from a few key privacy experts, it has been decided not to include _product identifiers_ in the taxonomy. Thanks to @janl and @TomWeiss for your valuable input.
TomWeiss (Tue, 05 Nov 2019 23:16:03 GMT):
Has joined the channel.
gordon_hkpkiforum (Mon, 11 Nov 2019 08:49:25 GMT):
Has joined the channel.
VipinB (Mon, 11 Nov 2019 16:23:02 GMT):
@pknowles Any Agenda for tomorrow?
pknowles (Tue, 12 Nov 2019 09:06:37 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 12th November, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: DIDAuthZ ( @george.aristy ) - 20 mins
• Consent Q&A led by @janl - 10 mins
• Discussion: Schema and CredDef structures for Sovrin implementation (incl. use of hashlinks) ( @pknowles / C.Stöcker) - 20 mins
• Implementing modular blocks in ODCA objects ( @pknowles / @mtfk ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 12 Nov 2019 09:06:37 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 12th November, 2019
10am-11.15am PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: DIDAuthZ ( @george.aristy ) - 20 mins
• Consent Q&A led by @janl - 10 mins
• Discussion: Schema and CredDef structures for Sovrin implementation (incl. using hashlinks) ( @pknowles / C.Stöcker) - 20 mins
• Implementing modular blocks in ODCA objects ( @pknowles / @mtfk ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
VipinB (Tue, 12 Nov 2019 19:29:04 GMT):
@pknowles @mitfk About Modular blocks: I was on the call- It was not clear whether hl:
VipinB (Tue, 12 Nov 2019 19:32:28 GMT):
The other idea was using time to live as forcing a polling mechanism to introduce a push-like (event driven) mechanism into revocation- seems like this is used in many places (ttl for drivers license is 10 yrs in US); but if you get stopped by cops they do check the license revocation registry in real time.
pknowles (Tue, 12 Nov 2019 19:58:20 GMT):
@mtfk :top:
mtfk (Tue, 12 Nov 2019 21:10:59 GMT):
@VipinB regarding the links basically I always tend to talk abotu DRI (Decentralized Resource Identifier) which is basically what is URL but content based. Means DRI could become a standard how you link data points which are immutable. If it is Sovrin schema or IPFS schema does not matter it could goes as 'dri://sov/schema/112354' or 'dri://ipfs/112354' which points to same content. This way no matter where the object is you can be 100% that is same thing. Same concept as with `magnet` link This way this "hashlink" can be actually DRI which then make whole process super simple.
VipinB (Tue, 12 Nov 2019 21:41:30 GMT):
Thanks @mtfk dri is a good solution, was not evident from slide I think
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread as he should be able to provide us with a small _to do_ list to start the process of making `DRI` a standard. It looks like an essential piece of the puzzle so we should put some strong focus into this topic.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that he will be able to provide us with a small _to do_ list to help start the process of making `DRI` a standard. It looks like an essential piece of the puzzle so lets put some strong focus on this point.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that Drummond will be able to provide us with a small _to do_ list to help guide us in process of making `DRI` a standard. It looks like an essential piece of the puzzle so lets put some strong focus on this.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that Drummond will be able to provide us with a small todo list to help guide us in process of making `DRI` a standard. It looks like an essential piece of the puzzle so lets put some strong focus on this.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that Drummond will be able to help guide us in the process of making `DRI` a standard. It looks like an essential piece of the puzzle so lets put some strong focus on this.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that Drummond will be able to help guide us in the process of making DRI a standard. It looks like an essential piece of the puzzle so lets put some strong focus on this.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that Drummond will be able to help guide us in the process of making DRI a standard. It looks like an essential puzzle piece so lets put some strong focus on this.
pknowles (Wed, 13 Nov 2019 00:48:45 GMT):
Tagging @drummondreed into this "DRI (Decentralized Resource Identifier)" thread. I reckon that Drummond will be able to help guide us in the process of making DRI a standard. It looks like an essential puzzle piece so lets put some strong focus on it.
pknowles (Wed, 13 Nov 2019 01:19:20 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, November 26th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
@channel Regarding how we locate immutable data points, it would be great if we could come up with a stable solution for any use case. I think we can do that by delving into this idea of a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members. Regarding how we locate immutable data points, it would be great if we could come up with a stable solution for any use case. I think we can do that by delving into this idea of a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members.
Regarding how we locate immutable data points, it would be great if we could come up with a stable solution for any use case. I think we can do that by delving into this idea of a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
Regarding how we locate immutable data points, it would be great if we could come up with a stable solution for any use case. I think we can do that by delving into this idea of a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable solution for any use case involving the location of immutable data points. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable solution for any use case involving the locating of immutable data points. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable solution for any use case involving immutable data point location. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback?
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable solution for any use case involving immutable data point location. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback welcome.
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable identifier that can be used for any use case involving immutable data points. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same one. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback welcome.
pknowles (Wed, 13 Nov 2019 08:31:04 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable identifier that can be used for any use case involving immutable data points. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same object. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback welcome.
pknowles (Wed, 13 Nov 2019 20:31:35 GMT):
*Rich Schemas* - New RFC under review for the schema object (and corresponding HIPE in Indy). Review comments welcome. https://github.com/hyperledger/aries-rfcs/tree/master/features/0281-rich-schemas [For more info, reach out to @kenebert ]
pknowles (Wed, 13 Nov 2019 20:31:35 GMT):
*Rich Schemas* - New RFC under review for the schema object (and corresponding HIPE in Indy). Review comments welcome. https://github.com/hyperledger/aries-rfcs/tree/master/features/0281-rich-schemas [For more info, reach out to @kenebert directly]
pknowles (Wed, 13 Nov 2019 20:31:35 GMT):
*Rich Schemas* - New RFC under review for the schema object (and corresponding HIPE in Indy). Review comments welcome. https://github.com/hyperledger/aries-rfcs/tree/master/features/0281-rich-schemas [For more info, reach out to @kenebert directly.]
pknowles (Wed, 13 Nov 2019 20:31:35 GMT):
*Rich Schemas* - New RFC under review for the schema object (and corresponding HIPE in Indy). Review comments welcome. https://github.com/hyperledger/aries-rfcs/tree/master/features/0281-rich-schemas [For more info, reach out to @kenebert or @brentzundel directly.]
pknowles (Wed, 13 Nov 2019 20:31:35 GMT):
*Rich Schemas* - New RFC under review for the schema object (and corresponding HIPE in Indy). Review comments welcome. https://github.com/hyperledger/aries-rfcs/tree/master/features/0281-rich-schemas [For more info, reach out to @kenebert or @brentzundel .]
VipinB (Thu, 14 Nov 2019 21:22:13 GMT):
@pknowles In the example that you provided (also @mtfk ) 'dri://ipfs/112354' does 112354 refer to the hash of the attributes that you are including in the super-schema; I was looking for a reference to DRI to see whether there are formal standards for this. Was not able to come up with any. Maybe I am not looking in the right place. Magnet of course has lots of references. DRI is a special case of URI?
mtfk (Thu, 14 Nov 2019 22:14:29 GMT):
DRI was invented by me as nice name for the thing which we need. There is no standard for it, maybe one day. Basically DRI does not much differ from what magnet link is. Maybe except that magnet link has a bad reputation of piracy behind it ;) I did a presentation about DRI in one of our semantic call you can check it out.
pknowles (Thu, 14 Nov 2019 22:33:08 GMT):
DRI deck available at --> https://drive.google.com/drive/u/0/folders/17COuFJCbNgSrHo2blFyA38my9sNFRDn2
pknowles (Thu, 14 Nov 2019 22:35:59 GMT):
DRI video presentation available at --> https://drive.google.com/drive/u/0/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP
pknowles (Thu, 14 Nov 2019 22:35:59 GMT):
DRI video presentation available from 8 mins 55 secs at --> https://drive.google.com/drive/u/0/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP
pknowles (Thu, 14 Nov 2019 22:35:59 GMT):
DRI video presentation available at --> (from 8 mins 55 secs) https://drive.google.com/drive/u/0/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP
pknowles (Thu, 14 Nov 2019 22:35:59 GMT):
DRI video presentation available at --> https://drive.google.com/drive/u/0/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP (from 8 mins 55 secs)
pknowles (Thu, 14 Nov 2019 22:35:59 GMT):
DRI video presentation available at --> https://drive.google.com/drive/u/0/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP (from 8 mins 55 secs onwards)
pknowles (Thu, 14 Nov 2019 22:35:59 GMT):
DRI video presentation available at --> https://drive.google.com/drive/u/0/folders/1VslH6Wy4WQbGzZ1uAcWFWE1mpkq03drP (from 8 mins 55 secs)
pknowles (Thu, 14 Nov 2019 22:41:07 GMT):
DRI deck available at --> https://drive.google.com/drive/u/0/folders/17COuFJCbNgSrHo2blFyA38my9sNFRDn2
pknowles (Thu, 14 Nov 2019 23:56:26 GMT):
@mtfk Are we able to use "content-type" and "content-id" DID matrix parameters as a DRI solution? https://github.com/w3c/did-core/pull/61
pknowles (Thu, 14 Nov 2019 23:56:26 GMT):
@mtfk Are we able to use "content-type" and "content-id" DID matrix parameters as a DRI solution for now? https://github.com/w3c/did-core/pull/61
mtfk (Fri, 15 Nov 2019 06:36:04 GMT):
In theory we can use anything which points to immutable file
mtfk (Fri, 15 Nov 2019 06:38:33 GMT):
The problem is that having schema on the ledger does not seems like a good idea as there is size limitation as well performance to se/query/
mtfk (Fri, 15 Nov 2019 06:38:33 GMT):
The problem is that having schema on the ledger does not seems like a good idea as there is size limitation as well performance to search/query/
VipinB (Fri, 15 Nov 2019 19:11:08 GMT):
Should we be inventing our own? I will take a look at the slides. Magnet seems like a good way to get at a URI with an embedded hash, it contains a fingerprint of the doc as well. I am sure that someone will bring up the whole collision thing. Which of course may have to be addressed in your write-up and why a salt is not necessary.
Having the schema on the ledger- means (in my mind) there is a schema on the ledger- (the ledger has to be readable publicly- if the schema is public- at the minimum) or there is a way to get to schema using a pointer (DRI); or there is a way to assemble the schema using multiple pointers(DRIs). When I say pointer I mean that it has to be also reachable and readable by all (if it is a public schema). Now you are also telling me that the hash at the tail of the schema will be the same for all dris that point to the same document and will be a fingerprint.
Querying is another story, since the schema details are subsumed in the DRI. Querying from the ledger is always hard (for random searches).
pknowles (Mon, 18 Nov 2019 06:54:33 GMT):
Thanks for your input, @VipinB . We'll bash this about some more to get consensus of opinion. Magnet may well be our best option here rather than DID. In any case, @mtfk and I have to come to a definite decision this week as we need a solid solution for a current pilot that we're working on.
pknowles (Mon, 18 Nov 2019 21:33:45 GMT):
FAO all #indy-semantics channel members ...
It would be great if we could come up with a stable identifier that can be used for any use case involving immutable data points. A popular idea that has been touched upon on a number of occasions is the concept of using a *DRI* (Decentralized Resource Identifier) which is basically a similar concept to URL but content based. DRI could become a standard for how you link data points which are immutable. In other words, it wouldn't matter whether we're dealing with a Sovrin schema or an IPFS schema as 'dri://sov/schema/112354' and 'dri://ipfs/112354' would point to the same content. In this way, no matter where the object is housed, you can be 100% sure that we're referencing the same object. This is a similar concept to a _magnet link_. A DRI would make the whole process very simple. [ Ref. for _magnet link_: https://en.wikipedia.org/wiki/Magnet_URI_scheme ]. Thoughts and feedback welcome.
pknowles (Wed, 20 Nov 2019 14:56:06 GMT):
@kenebert @brentzundel @mtfk Is it theoretically possible to point to schema objects not anchored on the Sovrin ledger and still build on-ledger CredDefs? At this stage, we don't necessarily need to know how to do it but that it is possible in theory.
pknowles (Wed, 20 Nov 2019 14:56:06 GMT):
@kenebert @brentzundel @mtfk Is it theoretically possible to point to schema objects not anchored on the Sovrin ledger and still build on-ledger CredDefs? At this stage, we don't necessarily need to know how to do it, just whether or not it is possible in theory.
pknowles (Wed, 20 Nov 2019 14:56:06 GMT):
@kenebert @brentzundel @mtfk Is it theoretically possible to point to schema objects not anchored on the Sovrin ledger and still build on-ledger CredDefs? At this stage, we don't necessarily need to know "how" to do it but whether or not it "can" be done.
mtfk (Wed, 20 Nov 2019 16:04:36 GMT):
I believe so, is just question of resolution process of fetching schema right now it fetch from ledger but it could get it from other places.
brentzundel (Wed, 20 Nov 2019 17:05:25 GMT):
Theoretically, yes.
mwherman2000 (Thu, 21 Nov 2019 19:40:16 GMT):
Here's the link I mentioned in the Aries call this morning ...following Paul's talk ...the idea is about Universal Digital Identities and Universal Digital Identifiers having varying discernible Levels of Trust: https://hyperonomy.com/2019/11/21/trusted-digital-web-levels-of-universal-trust/
mwherman2000 (Thu, 21 Nov 2019 19:40:16 GMT):
Here's the link I mentioned in the Aries call this morning ...following Paul's talk ...the idea is about Universal Digital Identities and Universal Digital Identifiers having varying _discernible _Levels of Trust: https://hyperonomy.com/2019/11/21/trusted-digital-web-levels-of-universal-trust/
pknowles (Thu, 21 Nov 2019 19:50:39 GMT):
Thanks for sharing, Michael!
mtfk (Thu, 21 Nov 2019 20:10:09 GMT):
Tomorrow at 2pm CET I would take part in MyData Webinary where together with Schluss we would dive into integration between digital wallet (PDA) and data vaults. More info at: https://mydata.org/webinars/
Feel free to join!
pknowles (Tue, 26 Nov 2019 04:33:22 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 26th November, 2019
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Future scope of the Indy Semantics WG - 10 mins
• Update: ODCA as a standard ( pknowles ) - 10 mins
• Presentation: Linking to uncontrolled immutable data points - Hashlinks vs. Magnet links ( mtfk ) - 10 mins
[Ref.: Hashlinks - https://tools.ietf.org/html/draft-sporny-hashlink-04 / Magnet links - https://en.wikipedia.org/wiki/Magnet_URI_scheme ]
• Open workshop: Determining external schema object requirements for on-ledger CredDef builds - 30 mins
[Part 1. Schema bases - WG call: 26NOV2019 / Part 2. Overlays - WG call: 10DEC2019]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 26 Nov 2019 04:35:44 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 26th November, 2019
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Future scope of the Indy Semantics WG - 10 mins
• Update: ODCA as a standard ( @pknowles ) - 10 mins
• Short presentation: Linking to uncontrolled immutable data points - Hashlinks vs. Magnet links ( @mtfk ) - 10 mins
[Ref.: Hashlinks - https://tools.ietf.org/html/draft-sporny-hashlink-04 / Magnet links - https://en.wikipedia.org/wiki/Magnet_URI_scheme ]
• Open workshop: Determining external schema object requirements for on-ledger CredDef builds - 30 mins
[Part 1. Schema bases - WG call: 26NOV2019 / Part 2. Overlays - WG call: 10DEC2019]
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
IWontDiscloseMyIdentity (Tue, 26 Nov 2019 04:55:16 GMT):
Has joined the channel.
pknowles (Tue, 26 Nov 2019 21:00:36 GMT):
The decks and agenda from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. Unfortunately, due to altered Zoom settings, the call did not record. My humblest apologies. The Zoom settings have now been reset. The next meeting is on Tuesday, December 10th. https://drive.google.com/drive/u/0/folders/1FXajIhHJhRlGEDNf-JDIS_KPrOs9mnU4
lsl88 (Wed, 27 Nov 2019 15:37:50 GMT):
Has joined the channel.
mwherman2000 (Mon, 02 Dec 2019 17:24:04 GMT):
Can you add me as a demo for next week Paul? Trusted Digital Web: Universal DID Data Server
mwherman2000 (Mon, 02 Dec 2019 17:27:36 GMT):
Clipboard - December 2, 2019 10:27 AM
pknowles (Mon, 02 Dec 2019 21:18:53 GMT):
Absolutely. How long do you need for the demo?
mwherman2000 (Wed, 04 Dec 2019 01:09:21 GMT):
30 with Q&A
mwherman2000 (Wed, 04 Dec 2019 01:10:08 GMT):
Just posted this a few minutes ago: https://hyperonomy.com/2019/12/03/trusted-digital-web-first-trusted-web-page-delivered-today-dec-3-2019/
mtfk (Wed, 04 Dec 2019 21:29:23 GMT):
During today Aries call I briefly mentioned about the need of schema interop (RFC in preparation). Basic idea is to make sure that schema can be reused across networks and can be resolved for any place. We believe that having interoperabale object like schema is the key for decentralized data economy. As we know schema is not only used as data structure for verifiable credentials. In my opinion there is much more use cases outside VC, like data storage, data transportation, data requests. Having one schema for VC and other for other data structure does not make sens this is why we need to seek for interoperability for this crucial object.
What we are looking for is schema which:
- can be resolved from any place (without need to be member of particular network)
- can be uniquely identifiable across different networks and systems (best content based - DRI - hashlinks)
- does not have limit on size nor amount of attributes
- have to be immutable - once posted never cahnges (see above content based identifiers)
- support any type of the data (blobs, text, arrays etc, so one of the attribute could be your MRI picture)
- anything else?....
mtfk (Wed, 04 Dec 2019 21:29:50 GMT):
@kenebert ^
mtfk (Wed, 04 Dec 2019 21:31:48 GMT):
obviously we are seeing ODCA with schema_base as a candidate which fulfill all above and we are looking for suggestion about how we could introduce changes to existing systems like indy and VC to support that flow as well.
esplinr (Thu, 05 Dec 2019 21:20:18 GMT):
Hyperledger has a new process for managing calendars. Administrators of the mailing list group have the right to create calendar appointments. I requested to become an admin of the Indy group so that I could migrate our meetings to the new calendar. I think that I correctly created this meeting for every other Tuesday. Please let me know if I got it right @pknowles
esplinr (Thu, 05 Dec 2019 21:20:41 GMT):
The interface required my adding a meeting organizer. I added @kenebert because he was sitting next to me and I could warn him.
esplinr (Thu, 05 Dec 2019 21:21:02 GMT):
I don't know if that gives him any powers, or if it is just used when Hyperledger staff need to contact someone about a meeting.
esplinr (Thu, 05 Dec 2019 21:21:22 GMT):
Let me know if you decide to cancel the meeting scheduled for December 24. I can remove it from the calendar for you.
esplinr (Thu, 05 Dec 2019 21:21:54 GMT):
If someone else wants to become an admin and help manage this let me know.
pknowles (Thu, 05 Dec 2019 22:34:32 GMT):
Thanks, @esplinr . That all sounds fine. The next Indy Semantics WG call is next Tuesday (Dec 10th). You can go ahead and cancel the following one (Dec 24th). Cheers.
esplinr (Thu, 05 Dec 2019 22:36:37 GMT):
Excellent. I was able to make Ken an admin for the Indy mailing list, so he can help maintain the appointments.
esplinr (Thu, 05 Dec 2019 22:38:39 GMT):
Thank you for catching the missing meeting on the 10th. I fixed that and removed the meeting on the 24th.
esplinr (Thu, 05 Dec 2019 22:38:52 GMT):
It takes a few minutes for the change to propagate through the system.
pknowles (Tue, 10 Dec 2019 17:18:50 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 10th December, 2019
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation/Demo: Trusted Digital Web: Universal DID Data Server ( @mwherman2000 ) - 40 mins
[Ref.: https://hyperonomy.com/2019/12/03/trusted-digital-web-first-trusted-web-page-delivered-today-dec-3-2019/ ]
• New ODCA overlay: “Mapping overlay” ( @pknowles ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
mwherman2000 (Tue, 10 Dec 2019 17:34:28 GMT):
For the demo, it will be useful to know a little bit about the technical details of DNS ...n particular, that DNS is an extensible framework in addition to being a foundational protocol and a service on the Internet. This article will help you on the DNS side of things: https://hyperonomy.com/2019/01/02/dns-domain-name-service-a-detailed-high-level-overview/
mwherman2000 (Tue, 10 Dec 2019 17:34:28 GMT):
For the demo, it will be useful to know a little bit about the technical details of DNS ...in particular, that DNS is an extensible framework in addition to being a foundational protocol and a service on the Internet. This article will help you on the DNS side of things: https://hyperonomy.com/2019/01/02/dns-domain-name-service-a-detailed-high-level-overview/
pknowles (Wed, 11 Dec 2019 06:02:11 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. As the next scheduled meeting happens to fall on Christmas Eve, we'll give that one a miss and reconvene in the new year. The next meeting will be on Tuesday, January 7th. Wishing the Hyperledger community a wonderful festive period. See you on the other side! https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 11 Dec 2019 06:02:11 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. As the next scheduled meeting happens to fall on Christmas Eve, we'll give that one a miss and reconvene in the new year. The next meeting will be on Tuesday, January 7th. I'd like to take this opportunity to wish the Hyperledger community a wonderful festive season. See you on the other side! https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 11 Dec 2019 06:02:11 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. As the next scheduled meeting happens to fall on Christmas Eve, we'll give that one a miss and reconvene in the new year. The next meeting will be on Tuesday, January 7th. I'd like to take this opportunity to wish the Hyperledger community a wonderful festive season and I look forward to catching up with many of you on the other side! https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 11 Dec 2019 06:02:11 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. As the next scheduled meeting happens to fall on Christmas Eve, we'll give that one a miss and reconvene in the new year. The next meeting will be on Tuesday, January 7th. I'd like to take this opportunity to wish the Hyperledger community a wonderful festive period and I look forward to catching up with many of you on the other side! https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 11 Dec 2019 06:02:11 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. As the next scheduled meeting happens to fall on Christmas Eve, we'll give that one a miss and reconvene in the new year. The next meeting will be on Tuesday, January 7th. I'd like to take this opportunity to wish the Hyperledger community a wonderful festive period and look forward to catching up with many of you on the other side! https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 11 Dec 2019 06:02:11 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. As the next scheduled meeting happens to fall on Christmas Eve, we'll give that one a miss and reconvene in the new year. The next meeting will be on Tuesday, January 7th. I'd like to take this opportunity to wish Hyperledger community members a wonderful festive period and look forward to catching up with many of you on the other side! https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
mwherman2000 (Sat, 14 Dec 2019 04:05:58 GMT):
As a follow-up to my demo last Tuesday and the question about "secure didttp:":1) I've now implemented didttps: (Secure DID Trusted Transport Protocol) using TLS over Tcp port 853 (instead of DNS Tcp port 53)
mwherman2000 (Sat, 14 Dec 2019 04:05:58 GMT):
As a follow-up to my demo last Tuesday and the question about "secure didttp:":
1) I've now implemented didttps: (Secure DID Trusted Transport Protocol) using TLS over Tcp port 853 (instead of DNS Tcp port 53)
2) Here's a good explanation about the differences between DNS over TLS vs. DNS over HTTPS: https://www.ma-no.org/en/networking/configuring-dns-over-tls-and-dns-over-https-with-any-dns-server
stone-ch (Sun, 15 Dec 2019 04:41:40 GMT):
Has left the channel.
pknowles (Tue, 07 Jan 2020 17:39:20 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 7th January, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Demo: Using Hashlinks to resolve data payloads outside of the credential definition ( @mtfk ) - 20 mins
• Complimentary technologies to support the SSI community and related use cases ( @pknowles ) - 10 mins
[Ref.: e.g. semantic containers - https://www.ownyourdata.eu/en/semcon/ ]
• Use case: Proposal for a Pharma consortia “Data Sharing Hub” with SSI onboarding for all health subjects ( @pknowles ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Wed, 08 Jan 2020 23:12:10 GMT):
The agenda, video, notes, etc. from yesterday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, January 21st. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 15 Jan 2020 22:02:01 GMT):
The word _encode_ is used for both _binary-to-text encoding_ (e.g. sha256) and _character encoding_ (e.g. utf-8). Having spoken to @kdenhartog , we decided that it would make sense to change the name of the current "encode overlay" to "character overlay" so that we have room to manoeuvre when we start working in the _binary-to-text encoding_ space. In other words, we will eventually have both a "character overlay" and a "binary-to-text overlay". Problem solved. Thanks, Kyle.
pknowles (Wed, 15 Jan 2020 22:02:01 GMT):
The word _encode_ is used for both _binary-to-text encoding_ (e.g. sha256) and _character encoding_ (e.g. utf-8). Having spoken to @kdenhartog , we decided that it would make sense to change the name of the current "encode overlay" to "character encoding overlay" so that we have room to manoeuvre when we start working in the _binary-to-text encoding_ space. In other words, we will eventually have both a "character encoding overlay" and a "binary-to-text encoding overlay". Problem solved. Thanks, Kyle.
EdEykholt (Mon, 20 Jan 2020 03:30:21 GMT):
Has joined the channel.
pknowles (Tue, 21 Jan 2020 17:22:01 GMT):
Due to a daily light agenda, today's *Indy Semantics WG* call is postponed to next Tuesday (Jan.28th) at the usual time. Apologies for any inconvenience. Speak to you next week. Paul
pknowles (Tue, 21 Jan 2020 17:22:01 GMT):
Due to a fairly light agenda, today's *Indy Semantics WG* call is postponed to next Tuesday (Jan.28th) at the usual time. Apologies for any inconvenience. Speak to you next week. Paul
pknowles (Tue, 21 Jan 2020 17:22:01 GMT):
Due to a fairly light agenda, today's *Indy Semantics WG* call is postponed to next Tuesday (Jan.28th) at the usual time. Apologies for any inconvenience. Paul
esplinr (Tue, 21 Jan 2020 23:15:41 GMT):
I can update the calendar for you.
esplinr (Tue, 21 Jan 2020 23:18:03 GMT):
Oh, you meet every two weeks. When will you be meeting after Jan 28?
* Feb 4, per the existing appointment
* Feb 11, switching to the opposite cadence of bi-weekly
* Feb 18, skipping one session and moving back to the current schedule
Let me know and I can make the calendar match.
pknowles (Wed, 22 Jan 2020 01:19:01 GMT):
Thanks, @esplinr . It'll be Jan 28, Feb 4, Feb 18, Mar 3, etc.
esplinr (Wed, 22 Jan 2020 16:04:42 GMT):
Good to know. The calendar should reflect that now. If you see any problems, or need any changes in the future, either Ken Ebert or I can make them.
domwoe (Sat, 25 Jan 2020 18:31:19 GMT):
Has joined the channel.
pknowles (Tue, 28 Jan 2020 17:34:20 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 7th January, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: Semantic Container for Data Mobility ( C.Fabianek ) - 35 mins
[Ref.: semantic containers - https://www.ownyourdata.eu/en/semcon/ ]
• Presentation: Decentralized Data Network and the case for introducing a new identifier for non-governed entities, the "DRI" ( @pknowles ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
pknowles (Tue, 28 Jan 2020 17:34:20 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 28th January, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: Semantic Container for Data Mobility ( C.Fabianek ) - 35 mins
[Ref.: semantic containers - https://www.ownyourdata.eu/en/semcon/ ]
• Presentation: Decentralized Data Network and the case for introducing a new identifier for non-governed entities, the "DRI" ( @pknowles ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
pknowles (Tue, 28 Jan 2020 17:34:20 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 28th January, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: Semantic Container for Data Mobility ( C.Fabianek ) - 35 mins
[Ref.: semantic containers - https://www.ownyourdata.eu/en/semcon/ ]
• Presentation: Decentralized Data Network and the case for introducing an identifier for non-governed entities ( @pknowles ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
pknowles (Tue, 28 Jan 2020 17:34:20 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 28th January, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: Semantic Container for Data Mobility (C.Fabianek) - 35 mins
[Ref.: semantic containers - https://www.ownyourdata.eu/en/semcon/ ]
• Presentation: Decentralized Data Network and the case for introducing an identifier for non-governed entities ( @pknowles ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
pknowles (Wed, 29 Jan 2020 03:43:56 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, January 28th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Wed, 29 Jan 2020 04:01:12 GMT):
The semantics group have recently been discussing how to best resolve large data objects in verifiable credentials. A key technology, component and endpoint in that resolve is *Semantic Containers* for transient storage and data mobility. For anyone interested to learn more about the technology, click on the above link, go to "Videos", "2020-01-28" and watch the WG call video from 12 mins 55 secs onwards. Thanks to Christoph Fabianek from OwnYourData for a fascinating presentation/discussion regarding the technology.
pknowles (Thu, 30 Jan 2020 12:45:56 GMT):
Kantara is decommissioning the "Consent and Information Sharing" WG. A new WG is now in place to take on the remit of that group, the "Information Sharing Interoperability" WG. As such, there is now a new home/URL for the "Blinding Identity Taxonomy". If you click on the link, you'll notice that we removed any mention of PII in the descriptive intro. Here is the new URL for the BIT ...
pknowles (Thu, 30 Jan 2020 12:45:56 GMT):
Kantara is decommissioning the "Consent and Information Sharing" WG. A new WG is now in place to take on the remit of that group, the "Information Sharing Interoperability" WG. As such, there is now a new home/URL for the *Blinding Identity Taxonomy*. If you click on the link, you'll notice that we removed any mention of PII in the descriptive intro. Here is the new URL for the BIT ...
pknowles (Thu, 30 Jan 2020 12:46:12 GMT):
https://kantarainitiative.org/confluence/display/WGISI/Blinding+Identity+Taxonomy
pknowles (Tue, 04 Feb 2020 17:12:49 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 4th February, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Use case: Proposal for a Pharma consortium ‘Data Sharing Hub’ with SSI onboarding for all subjects ( @pknowles ) - 20 mins
• Demo: Latest version of hashed data transportation using Hyperledger Aries VC tool ( @mtfk ) - 20 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
rehuman (Tue, 04 Feb 2020 19:04:24 GMT):
Has joined the channel.
rehuman (Tue, 04 Feb 2020 19:04:25 GMT):
Thank you @pknowles
pknowles (Tue, 04 Feb 2020 20:10:20 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, February 18th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this generic model during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a reference.
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this generic model during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a reference point.
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this generic model during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a point of reference. For anyone interested in a fuller description of the use case, go to https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32 , click on "Videos" and "2020-02-04" to get to the use case presentation.
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this flow diagram during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a point of reference. For anyone interested in a fuller description of the use case, go to https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32 , click on "Videos" and "2020-02-04" to get to the use case presentation.
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this flow diagram during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a point of reference. For anyone interested in a fuller description of the use case, go to https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32 , click on "Videos" and "2020-02-04" to get to the use case presentation. PDF attachment below.
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this flow diagram during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a point of reference. For anyone interested in a fuller description of the use case, go to https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32 , click on "Videos" and "2020-02-04" to get to the use case presentation. PDF attachment below. :arrow_down:
pknowles (Thu, 06 Feb 2020 03:59:17 GMT):
Thanks for the input from the semantics group and especially to @swcurran for helping to get the flow sequence right for the following model. I presented this flow diagram during yesterday's semantics call describing how to go about *SSI onboarding prior to data capture consent*. I've pitched this IMI/PharmaLedger "Blockchain Enabled Healthcare" proposal to Roche. It would include the creation of a transformation tool to transform schema from ODM-XML format [ https://www.cdisc.org/standards/data-exchange/odm ] in their Data Capture Hub (DCH) to OCA-formatted objects which would enable consortium members to use interoperable schema objects when interacting with data transported to a new Data Sharing Hub (DSH) under the IMI umbrella. If anyone is working on a similar flow, feel free to use this model as a point of reference. For anyone interested in a fuller description of the use case, go to https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32 , click on "Videos" and "2020-02-04" to view the use case presentation. PDF attached below. :arrow_down:
pknowles (Thu, 06 Feb 2020 03:59:25 GMT):
2020-02-04 Extract.pdf
pknowles (Thu, 06 Feb 2020 04:16:14 GMT):
2020-02-04 Extract.pdf
esplinr (Mon, 10 Feb 2020 18:25:42 GMT):
Because the Indy Contributors call hasn't been convenient for us all to work together, we want to schedule a call to discuss Rich Schemas. Would tomorrow at 8AM Mountain work for people? (especially @kenebert )
kenebert (Mon, 10 Feb 2020 18:25:59 GMT):
Yes.
NikhilPrakash (Wed, 12 Feb 2020 00:50:22 GMT):
Has joined the channel.
pknowles (Tue, 18 Feb 2020 17:10:48 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 18th February, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Update: Rich Schema ( @kenebert ) - 15 mins
• Update: Development plans for Kantara Initiative’s Consent Receipt v.2.0 (Mark Lizar, OpenConsent) - 10 mins
• Use case: Proposal for a Pharma consortium ‘Data Sharing Hub’ with SSI onboarding for all subjects [Part 2] ( @pknowles ) - 10 mins
• Demo/update: OCA middleware tools updates ( @mtfk ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 18 Feb 2020 17:10:48 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 18th February, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Update: Rich Schema ( @kenebert ) - 15 mins
• Update: Development plans for Kantara Initiative’s Consent Receipt v.2.0 (Mark Lizar, OpenConsent) - 10 mins
• Use case: Proposal for a Pharma consortium ‘Data Sharing Hub’ with SSI onboarding for all subjects [Part 2] ( @pknowles ) - 10 mins
• Demo/update: OCA middleware tooling ( @mtfk ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 18 Feb 2020 17:10:48 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 18th February, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Update: Rich Schema ( @kenebert ) - 15 mins
• Update: Development plans for Kantara Initiative’s Consent Receipt v.2.0 (Mark Lizar, OpenConsent) - 10 mins
• Demo: Using Verifiable Credentials to resolve external schemas and data payloads using Hashlinks ( @mtfk ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 18 Feb 2020 21:16:56 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, March 3rd. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
ajayjadhav (Wed, 19 Feb 2020 08:23:07 GMT):
FYI - @ankita.p
pknowles (Wed, 19 Feb 2020 08:46:16 GMT):
@ajayjadhav @ankita.p Welcome to the Hyperledger Indy Semantics channel. Feel free to reach out if you have any specific queries.
ankita.p (Wed, 19 Feb 2020 08:46:16 GMT):
Has joined the channel.
ajayjadhav (Thu, 20 Feb 2020 10:53:21 GMT):
Thanks @pknowles
ankita.p (Fri, 28 Feb 2020 06:46:03 GMT):
[ ](https://chat.hyperledger.org/channel/indy-semantics?msg=Zr66LT5cbtajk4XZ3) Thank you @pknowles
pknowles (Tue, 03 Mar 2020 17:07:46 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 3rd March, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Overview: "Decentralized Data Network for Dummies" ( @pknowles ) - 15 mins
• Formation of The Human Colossus Foundation: First steps and why it was founded ( @pknowles / @mtfk ) - 15 mins
• Use case: Proposal for a Pharma consortium ˜Data Sharing Hub” with SSI onboarding for all subjects ( @pknowles ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 03 Mar 2020 17:07:46 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 3rd March, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Overview: "Decentralized Data Network for Dummies" ( @pknowles ) - 15 mins
• Formation of The Human Colossus Foundation: First steps and why it was founded ( @pknowles / @mtfk ) - 15 mins
• Use case: Proposal for a Pharma consortium "Data Sharing Hub" with SSI onboarding for all subjects ( @pknowles ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 03 Mar 2020 20:22:56 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, March 17th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
Abhishekkishor (Thu, 12 Mar 2020 19:44:50 GMT):
Has joined the channel.
pknowles (Tue, 17 Mar 2020 16:30:48 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 17th March, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Update: The Human Colossus Foundation: Synergy for a Decentralized Data Economy ( @pknowles ) - 15 mins
• Discussion: Resource DID / DRI - What properties are required and can it be kept in the DID space? ( @mtfk / @pknowles ) - 15 mins
• Update: Sovrin Transition Committee - Action plan and road ahead ( @pknowles ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 17 Mar 2020 16:30:48 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 17th March, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Update: The Human Colossus Foundation: Synergy for a Decentralized Data Economy ( @pknowles ) - 10 mins
• Discussion: Resource DID / DRI - What properties are required and can it be kept in the DID space? ( @mtfk / @pknowles ) - 40 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 17 Mar 2020 20:52:04 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, March 17th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Tue, 17 Mar 2020 20:52:04 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, March 31st. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Fri, 20 Mar 2020 16:22:49 GMT):
The most important discussion regarding _DIDs for everything_ is in full flow. If anyone has any firm thoughts on DID spec inclusion/exclusion of resource identifiers, speak now or forever hold your peace. https://github.com/w3c/did-core/issues/233
pknowles (Fri, 20 Mar 2020 16:22:49 GMT):
The most important discussion regarding _DIDs for everything_ is in full flow. If anyone has any firm thoughts on DID spec inclusion/exclusion of object identifiers, speak now or forever hold your peace. https://github.com/w3c/did-core/issues/233
pknowles (Sat, 28 Mar 2020 01:46:00 GMT):
Evernym published a demo video yesterday to explain ...
* The rich schema implementation in Indy Node and Indy VDR
* Aries interoperability between LibVCX and Streetcred
https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate *OCA* / *rich schema* integration. Their investigation will no doubt provide valuable knowledge to the Indy/Aries community. I believe we will need to introduce two new overlays to make full integration possible: an "order overlay" (mappings) and a "binary-to-text encoding overlay" (encodings). I look forward to feeding back with news of their findings.
The best resource for OCA is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their rich schema project development work, head to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
I believe that we will ultimately need to introduce two new overlays to make full integration possible: an "order overlay" (what the rich schema guys refer to as _mappings_) and a "binary-to-text encoding overlay" (what they refer to as _encodings_) but let's see what Carsten's team can find out following a deep dive.
New overlays for the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base. (Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we need to introduce two new overlays to make full integration possible: an "order overlay" (_mappings_) and a "binary-to-text encoding overlay" (_encodings_). I look forward to receiving feed back following Spherity's deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, head to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays for the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base. (Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: an "order" overlay (_mappings_) and a "binary-to-text encoding" overlay (_encodings_). I look forward to receiving feed back from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, head to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base. (Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feed back from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, head to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base. (Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feed back from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, head to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base. (Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feed back from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base. (Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feed back from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- _Risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- _Order overlay_ to allow issues to set a distinct attribute order within the schema.
- _Binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- A _risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- An _order overlay_ to allow issues to set a distinct attribute order within the schema.
- A _binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include ...
- A _risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- An _order overlay_ to allow issues to set a distinct attribute order within the schema.
- A _binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- A _risk overlay_ to allow issuers to add a unique sensitivity level to any attributes that have been flagged in the schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- An _order overlay_ to allow issues to set a distinct attribute order within the schema.
- A _binary-to-text encoding overlay_ to allow the encoding of binary data in a sequence of printable characters.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go to 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA / rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That is more accurate in terms of the network model.
_(Note: Identity people naming semantic objects usually ends up in a land grab! Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That is more accurate in terms of the network model.
_(Note: Identity people naming semantic objects usually ends up in a land grab! Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That is more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab! Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best resource for *OCA* is The Human Colossus GitHub repository: https://github.com/thclab
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That is more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* resource is The Human Colossus GitHub repository: https://github.com/thclab
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That is more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* resource is The Human Colossus GitHub repository: https://github.com/thclab
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same issue with DIDs and there being no DID home for non-governed objects!)_
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same issue with DIDs and there being no DID home for non-governed objects!)_
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *rich schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and rich schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_ ... Just a thought. (I like synergy throughout!)
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the data capture side of the network model - the common schema space. For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of the network model. _(Note: Identity people naming semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_ ... Just a thought.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the female side of the network model - the _Schema_ space (as opposed to the _Credential_ space). For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of painting a picture on where that piece sits. _(Note: Identity people naming Semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_ ... Just a thought.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the female side of the network model - the _Schema_ space (as opposed to the _Credential_ space). For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of painting a picture on where that piece sits. _(Note: Identity people naming Semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_ ... Just a thought.
See mini-deck below to help naming of network components.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been keen on the term _Rich Schema_ as they have nothing to do with the female side of the network model - the _Schema_ space (as opposed to the _Credential_ space). For those who are new to the concept, think of Rich Schema as a claim entry architecture. That would be more accurate in terms of painting a picture on where that piece sits. _(Note: Identity people naming Semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_ ... Just a thought.
See mini-deck below to help naming of network components.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been keen on the term _Rich Schema_ as they have nothing to do with the female side of the network model - the _Schema_ space (as opposed to the _Credential_ space). For those who are new to the concept, think of Rich Schema as a claim entry architecture. That would be more accurate in terms of painting a picture on where that piece sits. _(Note: Identity people naming Semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_
"ZEA" is a dramatically better name than "Rich Schema". I'll put it down as an agenda item for the next Semantics WG call.
See mini-deck below to help naming of network components.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been a fan on the name _Rich Schema_ as the framework has nothing to do with the female (data capture) side of the network model - the _Schema_ space (as opposed to the _Credential_ space). For those who are new to the concept, think of Rich Schema as a claim entry architecture. That would be more accurate in terms of painting a picture on where that piece sits.
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_
@brentzundel / @kenebert - "ZEA" is a dramatically better name than "Rich Schema". I'll put it down as an agenda item for the next Semantics WG call to open up the discussion. See mini-deck below to help naming of network components.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been a fan on the name _Rich Schema_ as the framework has nothing to do with the female (data capture) side of the network model - the _Schema_ space. Rich Schema sit in the _Credential_ space. For those who are new to the concept, think of Rich Schema as a claim entry architecture. That would be more accurate in terms of painting a picture on where that piece sits.
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_
@brentzundel / @kenebert - "ZEA" is a dramatically better name than "Rich Schema". I'll put it down as an agenda item for the next Semantics WG call to open up the discussion. See mini-deck below to help naming of network components.
pknowles (Sat, 28 Mar 2020 02:54:23 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been a fan on the name _Rich Schema_ as the framework has nothing to do with the female (data capture) side of the network - the _Schema_ space. Rich Schema actually sit in the _Credential_ space. For those who are new to the concept, think of Rich Schema as a claim entry architecture. That would be more accurate in terms of painting a picture on where that piece sits.
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_
@brentzundel / @kenebert - "ZEA" is a dramatically better name than "Rich Schema". I'll put it down as an agenda item for the next Semantics WG call to open up the discussion. See mini-deck below to help naming of network components.
pknowles (Sat, 28 Mar 2020 08:53:31 GMT):
Identifiers.pdf
pknowles (Sat, 28 Mar 2020 08:54:13 GMT):
Identifiers.pdf
pknowles (Sat, 28 Mar 2020 09:41:41 GMT):
The Spherity [https://spherity.com] developers are keen to investigate OCA and Rich Schema integration. Their investigation will no doubt provide valuable feedback to the Indy/Aries community. I believe we'll need to develop two new overlays to make full integration possible: (i.) an _order overlay_ (mappings) and (ii.) a _binary-to-text encoding overlay_ (encodings). I look forward to receiving feedback from Spherity following their deep dive.
The best *OCA* (Overlays Capture Architecture) resource is The Human Colossus GitHub repository: https://github.com/thclab
New overlays in the development pipeline include, ...
- *Risk overlay* to allow issuers to add a unique sensitivity level to attributes that have been flagged as sensitive in a schema base.
(Context: https://wiki.idesg.org/wiki/index.php/Trustworthy_Healthcare_Provider#Data_Categorization)
- *Order overlay* to allow issuers to add a definitive order to attributes in a schema base.
- *Binary-to-text encoding overlay* _(encoding of binary data in a sequence of printable characters)_ to allow issuers to lock in hash functions (e.g. SHA-256 encryption) to ordered attributes defined by an _order overlay_.
For the latest update on where Evernym are at with their *Rich Schema* project development work, go from 8 mins 15 secs of the following demo video. This was posted just yesterday so is bang up to date. https://www.youtube.com/watch?v=lZ84bCxEKWo&list=PLRp0viTDxBWGLdZk0aamtahB9cpJGV7ZF
List of Rich Schema RFCs ...
- 0120: *Rich Schema Objects Common* - https://github.com/hyperledger/indy-hipe/tree/master/text/0120-rich-schemas-common
- 0138: *Contexts for Rich Schema Objects* - https://github.com/hyperledger/indy-hipe/blob/master/text/0138-rich-schema-context
- 0149: *Rich Schema Schemas* - https://github.com/hyperledger/indy-hipe/blob/master/text/0149-rich-schema-schema
- 0154: *Rich Schema Encoding* - https://github.com/hyperledger/indy-hipe/blob/master/text/0154-rich-schema-encoding
- 0155: *Rich Schema Mapping* - https://github.com/hyperledger/indy-hipe/blob/master/text/0155-rich-schema-mapping
- 0156: *Rich Schema Credential Definition* - https://github.com/hyperledger/indy-hipe/blob/master/text/0156-rich-schema-cred-def
I've never been too keen on the term _Rich Schema_ as they have nothing to do with the female side of the network model - the _Schema_ space (as opposed to the _Credential_ space). For those who are new to the concept, think of rich schema as _rich credential schema_. That would be more accurate in terms of painting a picture on where that piece sits. _(Note: Identity people naming Semantic objects usually ends up in a land grab. Same thing with DIDs and there being no DID home for non-governed objects!)_
_ZKP Entry Architecture_ vs _Overlays Capture Architecture_ ... Just a thought.
See mini-deck below to help naming of network components.
mohammadhossein73 (Sun, 29 Mar 2020 05:48:45 GMT):
Has joined the channel.
pknowles (Tue, 31 Mar 2020 16:50:54 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 31st March, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: Entity and Object Identifiers: Elements, components and characteristics of a decentralised network ( @pknowles ) - 15 mins
• Discussion: DIDs for non-governed objects. Can they have a home under the DID umbrella? ( @mtfk / @pknowles ) - 10 mins
• Presentation: Safe data sharing amidst a global pandemic ( @pknowles ) - 15 mins
• Update: Sovrin Transition Committee - Comms plan and steward testimonials ( @pknowles ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 31 Mar 2020 16:50:54 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 31st March, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Presentation: Entity and Object Identifiers: Elements, components and characteristics of a decentralised network ( @pknowles ) - 15 mins
• Discussion: DIDs for non-governed objects. Can they have a home under the DID umbrella? ( @mtfk / @pknowles ) - 15 mins
• Presentation: Safe data sharing amidst a global pandemic ( @pknowles ) - 15 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Wed, 01 Apr 2020 06:48:49 GMT):
The agenda, video, notes, etc. from yesterday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 14th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
brentzundel (Fri, 03 Apr 2020 20:39:32 GMT):
Has left the channel.
pknowles (Tue, 14 Apr 2020 16:41:45 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 14th April, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Live demo: Overlays Capture Architecture (OCA): A standardized global solution for data capture ( @mtfk ) - 20 mins
• Live demo: COVID-19 demo using Aries Toolbox ( @janl ) - 20 mins
• COVID-19 initiative: “Tools” focus groups for building credentials and initiating data flows ( @pknowles )- 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
Password: 1234
pknowles (Tue, 14 Apr 2020 16:41:45 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 14th April, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Live demo: Overlays Capture Architecture (OCA): A standardized global solution for data capture ( @mtfk ) - 20 mins
• Live demo: COVID-19 demo using Aries Toolbox ( @janl ) - 20 mins
• COVID-19 initiative: “Tools” focus groups for building credentials and initiating data flows ( @pknowles ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
Password: 1234
pknowles (Tue, 14 Apr 2020 20:51:17 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, April 28th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
SethiSaab (Wed, 15 Apr 2020 08:45:33 GMT):
Is there anyone who has done KeyCloak SSo integration with DIDs ?
swcurran (Wed, 15 Apr 2020 13:39:36 GMT):
We've done it with verified credentials, but not DIDs.
swcurran (Wed, 15 Apr 2020 13:40:10 GMT):
https://github.com/bcgov/vc-authn-oidc
swcurran (Wed, 15 Apr 2020 13:40:10 GMT):
https://github.com/bcgov/vc-authn-oidc - there are demos that can be run in the repo and we have some online - see the DemoInstructions.md in the docs folder
SethiSaab (Wed, 22 Apr 2020 06:37:05 GMT):
Hi Team , I want to integrate Cloud HSM with Indy for key management . Is there anyone who has done that before ?
SethiSaab (Wed, 22 Apr 2020 06:38:12 GMT):
or if anyone can provide some reference
pknowles (Tue, 28 Apr 2020 16:46:11 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 28th April, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Update: Trust-over-IP Foundation ( @pknowles ) - 10 mins
• Update: Sovrin Ecosystem ( @pknowles ) - 10 mins
• Update: Internet Identity Workshop (IIW) [30th edition] ( @pknowles ) - 10 mins
• Update: COVID-19 Credentials Initiative: Tools and technology ( @pknowles ) - 10 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 28 Apr 2020 23:30:50 GMT):
The agenda, video, notes, etc. from today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, May 12th. https://drive.google.com/drive/u/0/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou?ogsrc=32
pknowles (Thu, 30 Apr 2020 06:56:03 GMT):
@mtfk and I hosted an IIW session on *OCA* [Overlays Capture Architecture] yesterday which included a demo using the Aries toolbox.
Here is the video link - https://drive.google.com/file/d/13yuupet1o_oysdEjM99avsT5aPqs4DY9/view?usp=sharing
pknowles (Sat, 02 May 2020 00:55:20 GMT):
I hosted an IIW session on the *MHM* [Mouse Head Model] on Thursday. Here is the video link ...
https://drive.google.com/file/d/1TbUtUMjl_dbGQSlU0CMph2cFXhxMCD_p/view?usp=sharing
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group as we start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build middleware tooling for a Decentralized Data Economy (DDE). On the next *Indy Semantics WG* call I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from the three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms. If anyone is interested in this debate, please join us on Tuesday, May 12th at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This is less of a bun fight and more of a focussed discussion of human interaction versus system interaction within the model. Those are the kernels.
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group as we start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build middleware tooling for a Decentralized Data Economy (DDE). On the next *Indy Semantics WG* call I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from the three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms. If anyone is interested in this debate, please join us on Tuesday, May 12th at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This is less of a bun fight and more of a focussed discussion of _human interaction_ versus _system interaction_ within the model. Those are the kernels.
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group as we start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build middleware tooling for a Decentralized Data Economy (DDE). On the next *Indy Semantics WG* call I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from the three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms. If anyone is interested in this debate, please join us on Tuesday, May 12th at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This is less of a bun fight and more of a focussed discussion of _human interaction_ versus _machine interaction_ within the model. Those are the kernels.
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group as we start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build open source middleware tooling for a Decentralized Data Economy (DDE). On the next *Indy Semantics WG* call I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from the three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms. If anyone is interested in this debate, please join us on Tuesday, May 12th at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This is less of a bun fight and more of a focussed discussion of _human interaction_ versus _machine interaction_ within the model. Those are the kernels.
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group as we start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build open source middleware tooling for a Decentralized Data Economy (DDE). On the next *Indy Semantics WG* call I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from the three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms. If anyone is interested in this debate, please join us on Tuesday, May 12th at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This will be less of a bun fight and more of a focussed discussion of _human interaction_ versus _machine interaction_ within the model. Those are the kernels here.
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group as we start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build open source middleware tooling for a Decentralized Data Economy (DDE).
On the next *Indy Semantics WG* call, I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from all three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms.
If anyone is interested in this debate, please join us on *Tuesday, May 12th* at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This will be less of a bun fight and more of a focussed discussion of human interaction versus machine interaction within the model. Those are the kernels at play here.
pknowles (Sat, 02 May 2020 08:00:04 GMT):
Over the course of discussions with experts in the _Identity_ and _Consent_ communities before and during IIW, I believe that a clearer picture is starting to emerge on when the collective "we" should be using the word "trust" and when we should be using the word "assurance". The reason that this nuance is so important is that, having already knitted some key _Identity_ and _Semantics_ components together, The Human Colossus Foundation will now be shifting our focus to the _Consent_ piece by opening up discussions with the Open Consent Group to start knitting _Identity_, _Consent_ and _Semantics_ components together as we continue to build open source middleware tooling for a Decentralized Data Economy (DDE).
On the next *Indy Semantics WG* call, I want to bring some focus on the "trust" versus "assurance" naming issue in a bid to gain consensus from key stakeholders from all three ecosystems so that we can all jump the hurdle together and continue down the "decentralized" path with renewed confidence. In my granular breakdown during the call, I hope to shed some light on when best to use the two terms.
If anyone is interested in this debate, please join us on *Tuesday, May 12th* at 10am-11.15pm PT / 1pm-2.15pm ET / 6pm-7.15pm GMT. This will be less of a bun fight and more of a focussed discussion of human interaction versus machine interaction within the model. Those are the kernels at play here.
pknowles (Tue, 12 May 2020 15:31:33 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 12th May, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: pknowles
Agenda:
• Introductions (Open) - 5 mins
• Discussion: Trust versus Assurance ( pknowles ) - 35 mins• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
pknowles (Tue, 12 May 2020 15:31:33 GMT):
Here is the agenda and dial-in information for today's *Indy Semantics WG* call. These calls provide an opportunity for Hyperledger Indy community members to discuss issues pertaining to the Semantics layer of the stack. Anyone is welcome to join the call.
Meeting: Indy Semantics Working Group
Date: Tuesday, 12th May, 2020
10am-11.15pm PT
11am-12.15pm MT
12pm-1.15pm CT
1pm-2.15pm ET
6pm-7.15pm GMT
7pm-8.15pm CET
Chair: @pknowles
Agenda:
• Introductions (Open) - 5 mins
• Discussion: Trust versus Assurance ( @pknowles ) - 40 mins
• Any other business (Open) - 5 mins
Where: Online
Join from PC, Mac, Linux, iOS or Android: https://zoom.us/j/2157245727
Or iPhone one-tap : US: +16465588665,,2157245727# or +14086380986,,2157245727#
Or by Telephone … https://zoom.us/zoomconference?m=a0jD_rTMnh0ZYGQDOKPCNrK_0dP7WPfp1
Meeting ID : 2157245727
janl (Tue, 12 May 2020 17:04:16 GMT):
Hi @pknowles, I am getting a request for password. I do not see it in the above invite.
kenebert (Tue, 12 May 2020 17:04:29 GMT):
Me too.
janl (Tue, 12 May 2020 17:04:47 GMT):
it must be a very easy too knowing Paul
janl (Tue, 12 May 2020 17:05:15 GMT):
try 1234
janl (Tue, 12 May 2020 17:05:21 GMT):
I read further up
kenebert (Tue, 12 May 2020 17:05:31 GMT):
Paul is having a lonely meeting by himself.
pknowles (Tue, 12 May 2020 19:41:41 GMT):
Thanks for joining the meeting @kenebert and @janl . Can't believe you cracked the password. Talented chaps.
pknowles (Tue, 12 May 2020 19:41:41 GMT):
Thanks for joining the meeting @kenebert and @janl. Can't believe you cracked the password. Talented chaps.
pknowles (Tue, 12 May 2020 19:41:41 GMT):
Thanks for joining the meeting @kenebert and @janl . Can't believe you cracked the password. Talented chaps.
pknowles (Tue, 12 May 2020 19:41:41 GMT):
Thanks for joining the call @kenebert and @janl . Can't believe you cracked the password. Talented chaps.
pknowles (Tue, 12 May 2020 19:41:41 GMT):
Thanks for joining the call @kenebert and @janl . Can't believe you cracked the password. Talented chaps. :wink:
pknowles (Tue, 12 May 2020 19:41:41 GMT):
Thanks for dialling in @kenebert and @janl . Talented chaps. You cracked the password. :wink:
pknowles (Tue, 12 May 2020 19:52:40 GMT):
My old Dativa email address is defunct and, with it, my access to the shared area. As soon as have write access again, I'll upload the agenda, video, notes, etc. to the usual place. Apologies in advance for the delay.
pknowles (Thu, 14 May 2020 10:08:30 GMT):
The agenda, video, notes, etc. from Tuesday's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. The next meeting will be on Tuesday, May 26th. https://drive.google.com/drive/folders/1zkXr--0DG7I1k62vaFuotEzIaTIUH0ou
pknowles (Thu, 14 May 2020 10:24:27 GMT):
@drummondreed :top:
drummondreed (Thu, 14 May 2020 16:46:59 GMT):
Thanks Paul.
pknowles (Mon, 18 May 2020 16:36:36 GMT):
This is as granular as I think I can go regarding the Trust over IP dual-stack.
_Human trust in digital systems = Social Cohesion + Cryptographic Assurance_
If anyone has any thoughts, I'm all ears.
pknowles (Mon, 18 May 2020 16:36:36 GMT):
This is as granular as I think I can go regarding the Trust over IP dual-stack.
_Human trust in digital systems = Social trustworthiness + Cryptographic assurance_
If anyone has any thoughts, I'm all ears.
pknowles (Mon, 18 May 2020 16:36:36 GMT):
This is as granular as I think I can go regarding the Trust over IP dual-stack.
_Human trust in digital systems = Social cohesion + Cryptographic assurance_
If anyone has any thoughts, I'm all ears.
pknowles (Mon, 18 May 2020 16:36:36 GMT):
This is as granular as I think I can go regarding the Trust over IP dual-stack.
_Digital trust = Human accountability + Cryptographic assurance_
If anyone has any thoughts, I'm all ears.
pknowles (Tue, 26 May 2020 06:19:32 GMT):
NEWSFLASH: After nearly 18 months in existence, the *Hyperledger Indy Semantics WG* will be closing shop for good on *June 1st*. We are currently in the process of setting up a new *Decentralized Semantics WG* at the *Trust over IP Foundation*. The mission and scope of the new group will be to define a data capture architecture consisting of immutable schema bases and interoperable overlays for Internet-scale deployment. For more information, check out the new wiki page at https://wiki.trustoverip.org/pages/viewpage.action?pageId=65746
pknowles (Tue, 26 May 2020 06:21:02 GMT):
Today's *Indy Semantics WG* call will be the final one!
pknowles (Tue, 26 May 2020 20:14:01 GMT):
The slides and video from Today's *Indy Semantics WG* call have been uploaded to the following HL Indy shared area. https://drive.google.com/drive/folders/1DWZ97eBD4QpX_CWK2SxD_3Ed5KjIvCF8
pknowles (Tue, 26 May 2020 20:19:02 GMT):
Screenshot 2020-05-26 at 22.14.53.png
pknowles (Tue, 26 May 2020 20:19:02 GMT):
Screenshot 2020-05-26 at 22.14.53.png
pknowles (Tue, 26 May 2020 20:19:02 GMT):
Screenshot 2020-05-26 at 22.14.53.png
pknowles (Tue, 26 May 2020 20:19:52 GMT):
For more information, check out the new wiki page at https://wiki.trustoverip.org/pages/viewpage.action?pageId=65746
pknowles (Tue, 26 May 2020 20:19:52 GMT):
For more information on the newly proposed *Decentralized Semantics WG* at the *Trust over IP Foundation*, check out the wiki page at https://wiki.trustoverip.org/pages/viewpage.action?pageId=65746
pknowles (Wed, 27 May 2020 05:19:11 GMT):
If you are interested in being included in the kick-off plans for the newly proposed *Decentralized Semantics WG* at the *Trust over IP Foundation*, please add your name and email address to the following list. We will then add your name to the wiki and send a calendar invite to your email address. Please note that your email address will not be added to the wiki for privacy reasons.
https://drive.google.com/file/d/1XiE4IzeVke-tm0oCHC_GsKp2JgGuXIkZ/view?usp=sharing
pknowles (Fri, 29 May 2020 09:59:51 GMT):
@all FINAL NOTIFICATION: The *Hyperledger Indy Semantics WG* will be terminated on *Monday, June 1st*. A new *Decentralized Semantics WG* will be established at the *Trust over IP Foundation* in its place. The mission and scope of the new work group will be to define a data capture architecture consisting of immutable schema bases and interoperable overlays for Internet-scale deployment. For more information, check out the new wiki page at https://wiki.trustoverip.org/pages/viewpage.action?pageId=65746
If you are interested in being included in the kick-off plans for the new work group, please add your name and email address to the following distribution list. We will then add your name to the wiki and send a calendar invite to your email address. Please note that your email address will not be added to the wiki for privacy reasons. https://drive.google.com/file/d/1XiE4IzeVke-tm0oCHC_GsKp2JgGuXIkZ/view?usp=sharing
MALodder (Fri, 29 May 2020 13:38:05 GMT):
Has left the channel.
pknowles (Mon, 01 Jun 2020 19:25:20 GMT):
UPDATE: The newly proposed *Decentralized Semantics WG* at the *Trust over IP Foundation* will be reviewed by the *ToIP Steering Committee* on *Wednesday, June 10th*. To be kept in the loop, please add your name and email address to the following distribution list. We will then add your name to the wiki and send a calendar invite to your email address. Please note that your email address will not be added to the wiki for privacy reasons. https://drive.google.com/file/d/1XiE4IzeVke-tm0oCHC_GsKp2JgGuXIkZ/view?usp=sharing
swcurran (Mon, 01 Jun 2020 19:38:59 GMT):
Has left the channel.
george.aristy (Tue, 02 Jun 2020 19:23:29 GMT):
Has left the channel.
SethiSaab (Thu, 04 Jun 2020 12:41:45 GMT):
Hi Team , I need to setup production level Indy node for my client. Could someone please provide me any reference . As i haven't set it up for Production before . Thanks
esplinr (Tue, 23 Jun 2020 13:52:23 GMT):
Due to the transition to the Decentralized Semantics WG at the ToIP Foundation, should I remove the Tuesday meetings for Indy Semantics from the Hyperledger calendar?
esplinr (Tue, 23 Jun 2020 13:58:04 GMT):
@pknowles ?
pknowles (Wed, 24 Jun 2020 18:03:08 GMT):
Hi @esplinr - Yes, please remove the entry from the calendar. Thanks for reaching out.
pknowles (Wed, 24 Jun 2020 18:15:50 GMT):
UPDATE: Apologies for the delay regarding news of the *Decentralized Semantics WG* at the *Trust over IP Foundation*. The WG has been formally approved. We are just awaiting sign off on the J_DF Working Group Charter_ and then we can get things moving. Thanks for your patience.
pknowles (Wed, 24 Jun 2020 18:15:50 GMT):
UPDATE: Apologies for the delay regarding news of the *Decentralized Semantics WG* at the *Trust over IP Foundation*. The WG has been formally approved. We are just awaiting sign off on the _JDF Working Group Charter_ and then we can get things moving. Thanks for your patience.
pknowles (Mon, 29 Jun 2020 14:49:17 GMT):
Hello everyone,
I'm excited to announce that the *Decentralized Semantics Working Group* has now been formalized.
Wiki: https://wiki.trustoverip.org/display/HOME/Decentralized+Semantics+Working+Group
Mailing List: decentralized-semantics-wg@lists.trustoverip.org (please self-subscribe at https://lists.trustoverip.org/g/decentralized-semantics-wg)
Meeting Series: Weekly on Tuesday at 09:00 US PT, 12:00 US ET, 16:00 UTC (note: once you self-subscribe to the list, you will be added to the calendar invite)
IMPORTANT: If you or your employer are existing Members of the Trust over IP Foundation, but have not yet signed the Decentralized Semantics Working Group Charter, you or your employer can sign here. If you or your employer are not yet Members but are interested in joining the Trust over IP Foundation and this working group, please request a membership agreement at https://trustoverip.org/members/join/.
For the protection of all Members, participation in this Working Group is limited to members, including their employees, of the Trust over IP Foundation Decentralized Semantics Working Group, who have signed the membership documents and thus agreed to the intellectual property rules governing participation. If you or your employer are not a member of the working group, we ask that you not participate in Working Group activities beyond observing.
The kickoff meeting will be on Tuesday, July 7th. I look forward to meeting many of you then.
Best regards,
Paul
pknowles (Mon, 29 Jun 2020 14:49:17 GMT):
Hello everyone,
I'm excited to announce that the *Decentralized Semantics Working Group* has now been formalized.
Wiki: https://wiki.trustoverip.org/display/HOME/Decentralized+Semantics+Working+Group
Mailing List: decentralized-semantics-wg@lists.trustoverip.org (please self-subscribe at https://lists.trustoverip.org/g/decentralized-semantics-wg)
Meeting Series: Weekly on Tuesday at 09:00 US PT, 12:00 US ET, 16:00 UTC (note: once you self-subscribe to the list, you will be added to the calendar invite)
IMPORTANT: If you or your employer are existing Members of the Trust over IP Foundation, but have not yet signed the Decentralized Semantics Working Group Charter, you or your employer can sign here. If you or your employer are not yet Members but are interested in joining the Trust over IP Foundation and this working group, please request a membership agreement at https://trustoverip.org/members/join/.
For the protection of all Members, participation in this Working Group is limited to members, including their employees, of the Trust over IP Foundation Decentralized Semantics Working Group, who have signed the membership documents and thus agreed to the intellectual property rules governing participation. If you or your employer are not a member of the working group, we ask that you not participate in Working Group activities beyond observing.
The kickoff meeting will be on Tuesday, July 7th. I look forward to meeting many of you then.
Best regards,
Paul
pknowles (Mon, 29 Jun 2020 14:49:17 GMT):
Hello everyone,
I'm excited to announce that the *Decentralized Semantics Working Group* has now been formalized.
Wiki: https://wiki.trustoverip.org/display/HOME/Decentralized+Semantics+Working+Group
Mailing List: decentralized-semantics-wg@lists.trustoverip.org (please self-subscribe at https://lists.trustoverip.org/g/decentralized-semantics-wg)
Meeting Series: *Weekly on Tuesday at 09:00 US PT, 12:00 US ET, 16:00 UTC* (note: once you self-subscribe to the list, you will be added to the calendar invite)
IMPORTANT: If you or your employer are existing Members of the Trust over IP Foundation, but have not yet signed the Decentralized Semantics Working Group Charter, you or your employer can sign here. If you or your employer are not yet Members but are interested in joining the Trust over IP Foundation and this working group, please request a membership agreement at https://trustoverip.org/members/join/.
For the protection of all Members, participation in this Working Group is limited to members, including their employees, of the Trust over IP Foundation Decentralized Semantics Working Group, who have signed the membership documents and thus agreed to the intellectual property rules governing participation. If you or your employer are not a member of the working group, we ask that you not participate in Working Group activities beyond observing.
The kickoff meeting will be on *Tuesday, July 7th*. I look forward to meeting many of you then.
Best regards,
Paul
pknowles (Tue, 14 Jul 2020 09:53:54 GMT):
The mission statement for the *Decentralized Semantics WG* at Trust over IP is "to define a data capture architecture consisting of immutable schema bases and interoperable overlays for Internet-scale deployment." As promised during last week's successful kickoff meeting, Robert and I have put together an Overlays Capture Architecture (*OCA*) presentation/live demo for today's WG call. We hope to see some of you then! Call time: 09:00 US PT, 12:00 US ET, 16:00 UTC.
DSWG meeting page: https://wiki.trustoverip.org/display/HOME/DSWG+Meeting+Page
pknowles (Tue, 14 Jul 2020 09:53:54 GMT):
The mission statement for the *Decentralized Semantics WG* at *Trust over IP* is "to define a data capture architecture consisting of immutable schema bases and interoperable overlays for Internet-scale deployment." As promised during last week's successful kickoff meeting, Robert and I have put together an Overlays Capture Architecture (*OCA*) presentation/live demo for today's WG call. We hope to see some of you then! Call time: 09:00 US PT, 12:00 US ET, 16:00 UTC.
DSWG meeting page: https://wiki.trustoverip.org/display/HOME/DSWG+Meeting+Page
pknowles (Tue, 21 Jul 2020 10:45:55 GMT):
The main purpose of today's *Decentralized Semantics WG* meeting at *Trust over IP* is to allow the conveners of 3 proposed TFs (task forces) to present to the group: (i.) _Imaging TF_ (Conveners: Scott Whitmire/Moira Schieke); (ii.) _Medical Information TF_ (Conveners: Scott Whitmire/Moira Schieke); and (iii.) _Notice & Consent TF_ (Conveners: Mark Lizar/Salvatore D'Agostino). We look forward to seeing many of you then! Call time: 09:00 US PT, 12:00 US ET, 16:00 UTC.
DSWG meeting page: https://wiki.trustoverip.org/display/HOME/DSWG+Meeting+Page
Moshe7 (Mon, 27 Jul 2020 19:40:32 GMT):
Has joined the channel.
pknowles (Tue, 28 Jul 2020 14:42:01 GMT):
The main purpose of today's *Decentralized Semantics WG* meeting at *Trust over IP* is to allow @mtfk to give a tutorial on the _OCA Editor_ and _OCA Repository_. We look forward to seeing many of you then! Call time: 09:00 US PT, 12:00 US ET, 16:00 UTC.
DSWG meeting page: https://wiki.trustoverip.org/display/HOME/DSWG+Meeting+Page
pknowles (Tue, 04 Aug 2020 15:25:45 GMT):
The main purpose of today's *Decentralized Semantics WG* meeting at *Trust over IP* is to discuss _binary-to-text encoding objects_ (as defined on, for example, _Hyperledger Ursa_) and _Zero-knowledge proof_ (ZKP) functionality which OCA will need to support. We look forward to seeing many of you then! Call time: 09:00 US PT, 12:00 US ET, 16:00 UTC.
DSWG meeting page: https://wiki.trustoverip.org/display/HOME/DSWG+Meeting+Page
ankita.p17 (Mon, 12 Oct 2020 08:40:53 GMT):
Has joined the channel.
robdaa (Sat, 31 Oct 2020 18:04:01 GMT):
Has joined the channel.
robdaa (Sat, 31 Oct 2020 18:04:01 GMT):
Greetings. Just saw the Overlays 101 ssimeetup presentation again. Great stuff and seeking to get involved. Thanks Paul and Robert!
pknowles (Sat, 31 Oct 2020 18:46:33 GMT):
Thanks, @robdaa. We’ll be working on a revamped *Overlays Capture Architecture* (OCA) technical specification over the next few days which will be added as a new RFC on the Trust over IP GitHub repo. In the meantime, although in desperate need of lick of paint, *Aries RFC 0013: Overlays* is still the best technical resource out there presently. The *Semantics WG* at *Trust over IP* is the home for OCA pre-standards work. This is where you can keep up to date with all of the latest OCA developments. Those calls take place every Tuesday (11am MST / 6pm CET). For anyone interested in joining the ToIP Semantics WG as a contributing member, send an email to David Luchuk at dluchuk@contractor.linuxfoundation.org who will be able to help with the onboarding process. Feel free to namecheck me. It is free to join as an individual contributing member.
https://wiki.trustoverip.org/display/HOME/Semantics+Working+Group
pknowles (Sat, 31 Oct 2020 18:46:33 GMT):
Thanks, @robdaa. We’ll be working on a revamped *Overlays Capture Architecture* (OCA) technical specification over the next few days which will be added as a new RFC on the Trust over IP GitHub repo. In the meantime, although in desperate need of lick of paint, *Aries RFC 0013: Overlays* is still the best technical resource out there presently. The *Semantics WG* at *Trust over IP* is the home for OCA pre-standards work. This is where you can keep up to date with all of the latest OCA developments. Those calls take place every Tuesday (11am MST / 6pm CET). If you are interested in joining the ToIP Semantics WG as a contributing member, send an email to David Luchuk at dluchuk@contractor.linuxfoundation.org who will be able to help with the onboarding process. Feel free to namecheck me. It is free to join as an individual contributing member.
https://wiki.trustoverip.org/display/HOME/Semantics+Working+Group
pknowles (Sat, 31 Oct 2020 18:46:33 GMT):
Thanks, @robdaa . We’ll be working on a revamped *Overlays Capture Architecture* (OCA) technical specification over the next few days which will be added as a new RFC on the Trust over IP GitHub repo. In the meantime, although in desperate need of lick of paint, *Aries RFC 0013: Overlays* is still the best technical resource out there presently. The *Semantics WG* at *Trust over IP* is the home for OCA pre-standards work. This is where you can keep up to date with all of the latest OCA developments. Those calls take place every Tuesday (11am MST / 6pm CET). If you are interested in joining the ToIP Semantics WG as a contributing member, send an email to David Luchuk at dluchuk@contractor.linuxfoundation.org who will be able to help with the onboarding process. Feel free to namecheck me. It is free to join as an individual contributing member.
https://wiki.trustoverip.org/display/HOME/Semantics+Working+Group
mccown (Thu, 05 Nov 2020 15:33:38 GMT):
Has joined the channel.
ioddo (Tue, 17 Nov 2020 07:53:34 GMT):
Has joined the channel.
windley (Sun, 17 Jan 2021 22:33:48 GMT):
Has left the channel.
ascatox (Mon, 15 Mar 2021 11:01:19 GMT):
Has joined the channel.
troyronda (Mon, 29 Mar 2021 16:37:42 GMT):
Has left the channel.
rjones (Sat, 12 Feb 2022 22:02:57 GMT):
Has joined the channel.
rjones (Sat, 12 Feb 2022 22:02:58 GMT):
[Please move to Discord](https://discord.com/channels/905194001349627914/905205711850594336)
rjones (Sat, 12 Feb 2022 22:02:58 GMT):
[Please get an account on the Hyperledger discord](https://discord.gg), then [join Indy](https://discord.com/channels/905194001349627914/905205711850594336)
rjones (Sun, 13 Feb 2022 01:33:46 GMT):
Has left the channel.
rjones (Wed, 23 Mar 2022 17:26:52 GMT):
rjones (Wed, 23 Mar 2022 17:26:52 GMT):
rjones (Wed, 23 Mar 2022 17:26:52 GMT):
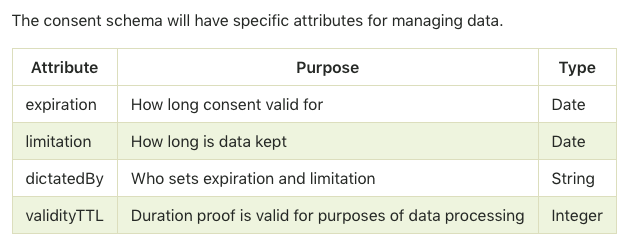{kind=link}
{kind=link}
{kind=link}
{kind=link}
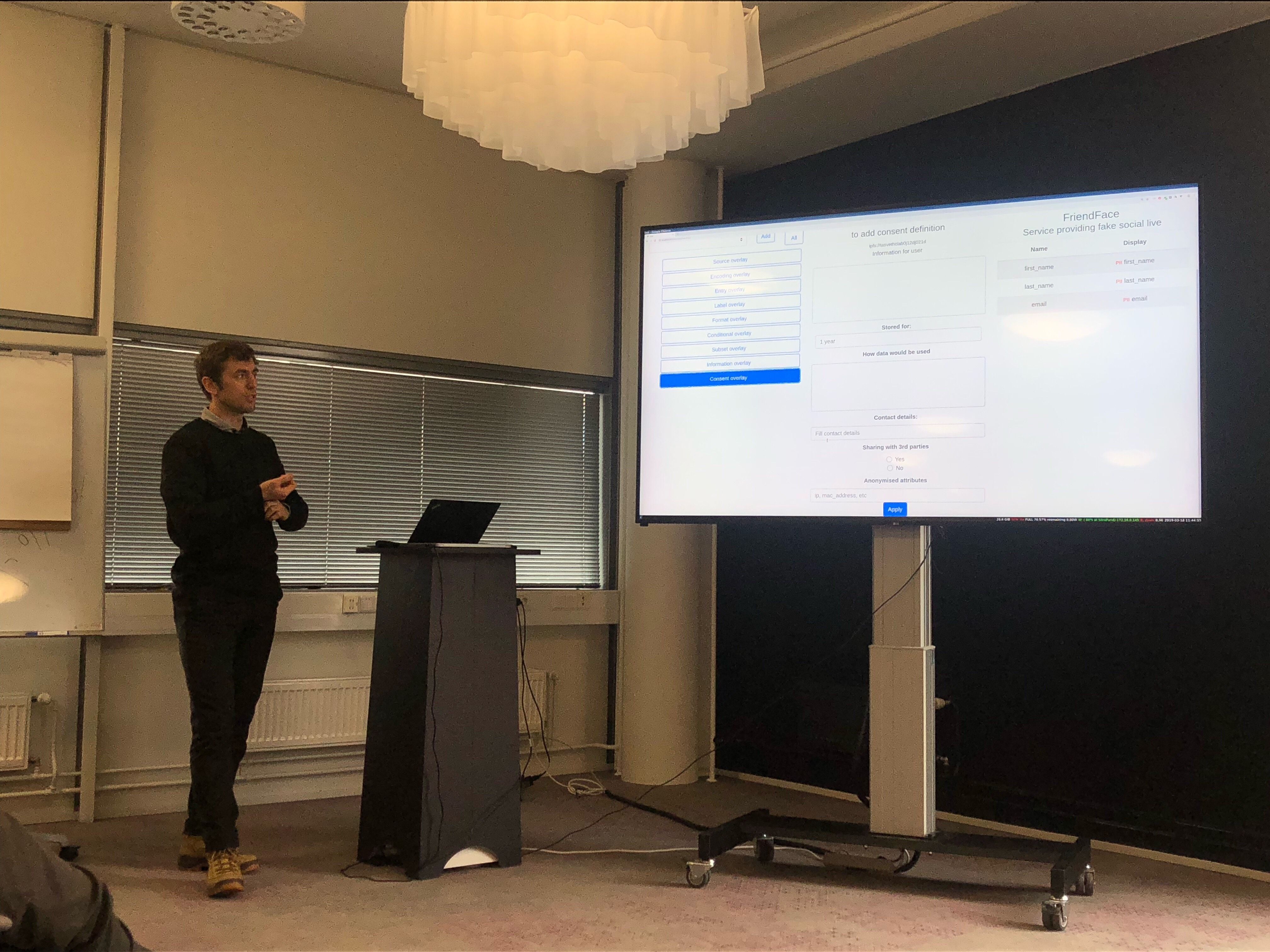{kind=link}
{kind=link}
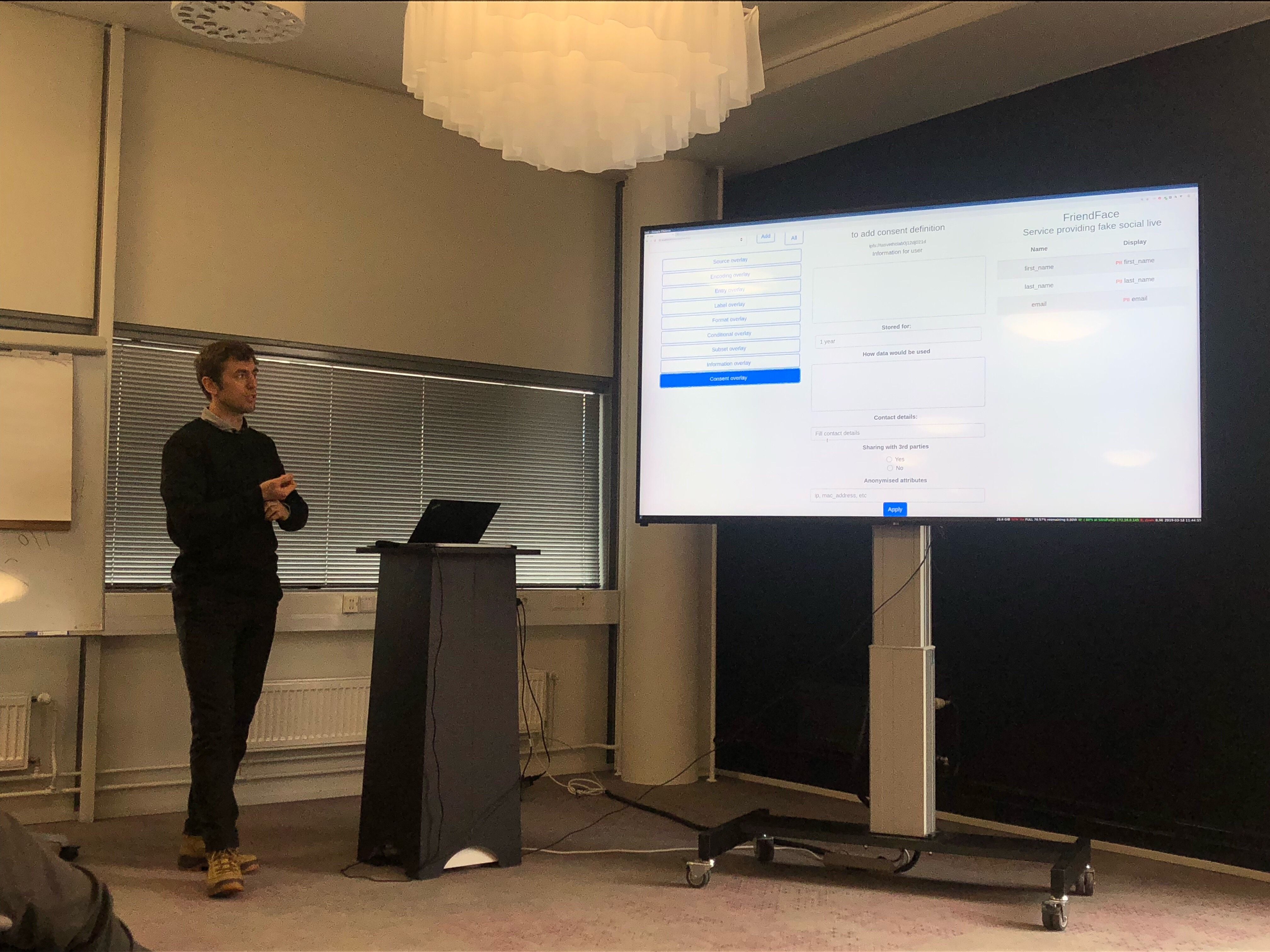{kind=link}
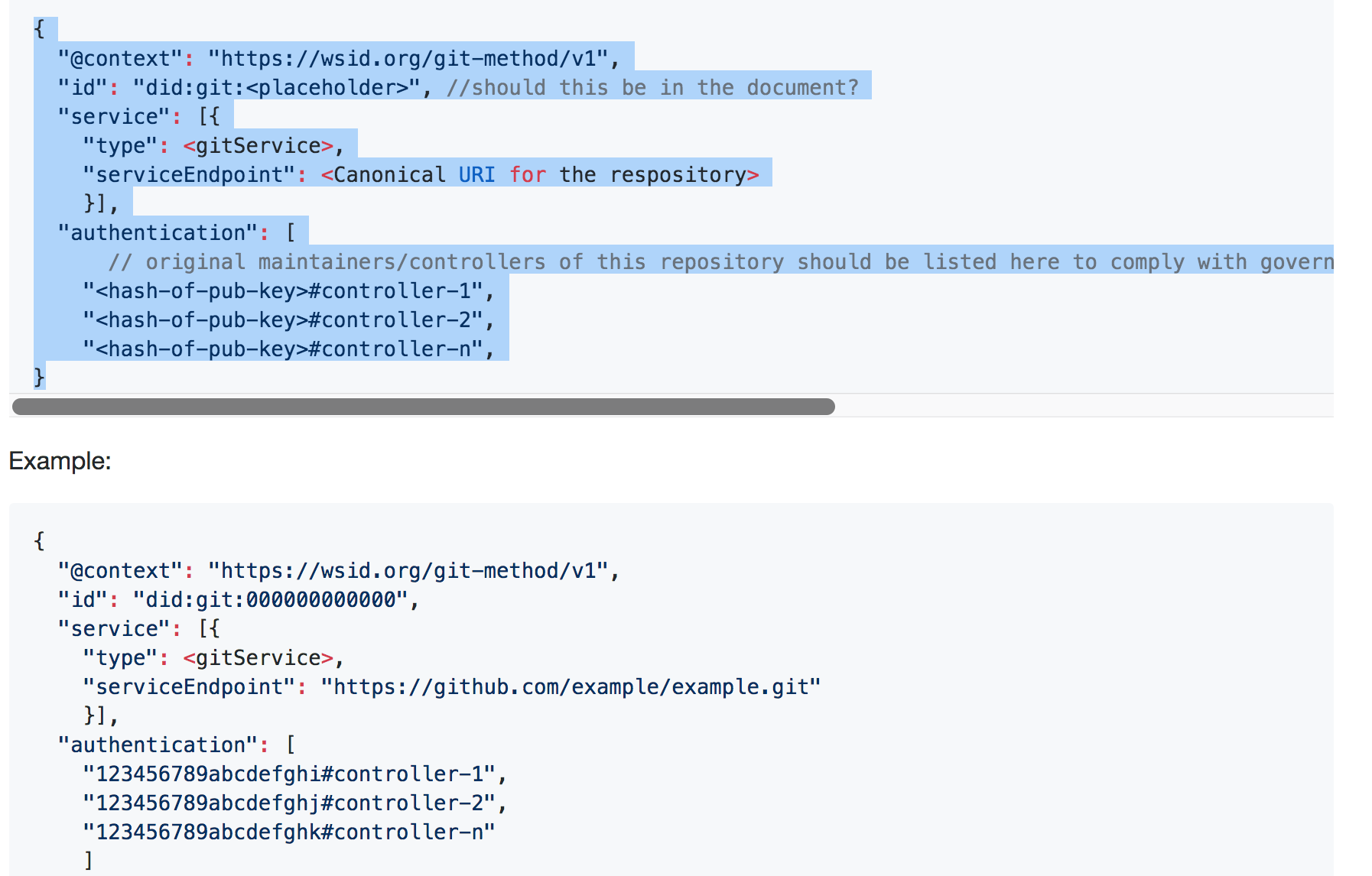{kind=link}
{kind=link}